Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo complementa os fluxos de trabalho do MLOps no Databricks adicionando informações específicas aos fluxos de trabalho do LLMOps. Para mais detalhes, consulte O Grande Livro do MLOps.
Como o fluxo de trabalho do MLOps é alterado para LLMs?
Os LLMs são uma classe de modelos de PLN (processamento de linguagem natural) que superaram significativamente seus predecessores em tamanho e desempenho em uma variedade de tarefas, como resposta às perguntas abertas, resumo e execução de instruções.
O desenvolvimento e a avaliação de LLMs diferem de algumas maneiras importantes dos modelos de ML tradicionais. Esta seção resume brevemente algumas das principais propriedades de LLMs e as implicações para MLOps.
| Principais propriedades de LLMs | Implicações para MLOps |
|---|---|
Os LLMs estão disponíveis em várias formas.
|
Processo de desenvolvimento: os projetos geralmente se desenvolvem incrementalmente, começando por modelos existentes, de terceiros ou de código aberto e terminando com modelos personalizados ajustados. |
| Muitos LLMs usam consultas e instruções gerais de linguagem natural como entrada. Essas consultas podem conter mensagens cuidadosamente elaboradas para obter as respostas desejadas. |
Processo de desenvolvimento: criar modelos de texto para consultar LLMs geralmente é uma parte importante do desenvolvimento de novos pipelines de LLM. Empacotamento de artefatos de ML: muitos pipelines de LLM usam LLMs existentes ou pontos de existentes de serviço de LLM. A lógica de ML desenvolvida para esses pipelines pode se concentrar em modelos de prompt, agentes ou cadeias em vez do próprio modelo. Os artefatos de ML empacotados e promovidos à produção podem ser esses pipelines, em vez de modelos. |
| Muitos LLMs podem receber prompts com exemplos, contexto ou outras informações para ajudar a responder à consulta. | Infraestrutura de serviço: Ao aumentar as consultas LLM com contexto, você pode usar ferramentas adicionais, como índices de vetor, para pesquisar contexto relevante. |
| As APIs de terceiros fornecem modelos proprietários e de código aberto. | Governança de API: o uso da governança de API centralizada fornece a capacidade de alternar facilmente entre provedores de API. |
| Os LLMs são modelos de aprendizado profundo muito grandes, muitas vezes variando de gigabytes a centenas de gigabytes. |
Infraestrutura de serviço: os LLMs podem exigir GPUs para serviço de modelo em tempo real e armazenamento rápido para modelos que precisam ser carregados dinamicamente. Compensações de custo/desempenho: como os modelos maiores exigem mais computação e são mais caros, podem ser necessárias técnicas para reduzir o tamanho do modelo e a computação. |
| Os LLMs são difíceis de avaliar usando métricas de ML tradicionais, pois muitas vezes não há uma única resposta "certa". | Comentários humanos: os comentários humanos são essenciais para avaliar e testar os LLMs. Você deve incorporar comentários do usuário diretamente no processo do MLOps, incluindo para teste, monitoramento e ajustes futuros. |
Pontos em comum entre MLOps e LLMOps
Muitos aspectos dos processos de MLOps não são alterados para LLMs. Por exemplo, as diretrizes a seguir também se aplicam a LLMs:
- Use ambientes separados para desenvolvimento, preparo e produção.
- Usar GIT para controle de versão.
- Gerencie o desenvolvimento de modelos com o MLflow e use Modelos no Catálogo do Unity para gerenciar o ciclo de vida do modelo.
- Armazene dados em uma arquitetura do lakehouse usando tabelas Delta.
- Sua infraestrutura de CI/CD existente não deve exigir alterações.
- A estrutura modular do MLOps permanece a mesma, com pipelines para a definição de recursos, treinamento de modelo, inferência de modelo, e assim por diante.
Diagramas de arquitetura de referência
Esta seção usa dois aplicativos baseados em LLM para ilustrar alguns dos ajustes na arquitetura de referência do MLOps tradicional. Os diagramas mostram a arquitetura de produção para 1) um aplicativo de geração aumentada por recuperação (RAG) usando uma API de terceiros e 2) um aplicativo RAG usando um modelo auto-hospedado e ajustado. Ambos os diagramas mostram um banco de dados de vetor opcional – esse item pode ser substituído consultando diretamente o LLM por meio do ponto de extremidade deo Serviço de Modelo.
RAG com uma API de LLM de terceiros
O diagrama mostra uma arquitetura de produção para um aplicativo RAG que se conecta a uma API de LLM de terceiros usando modelos externos do Databricks.
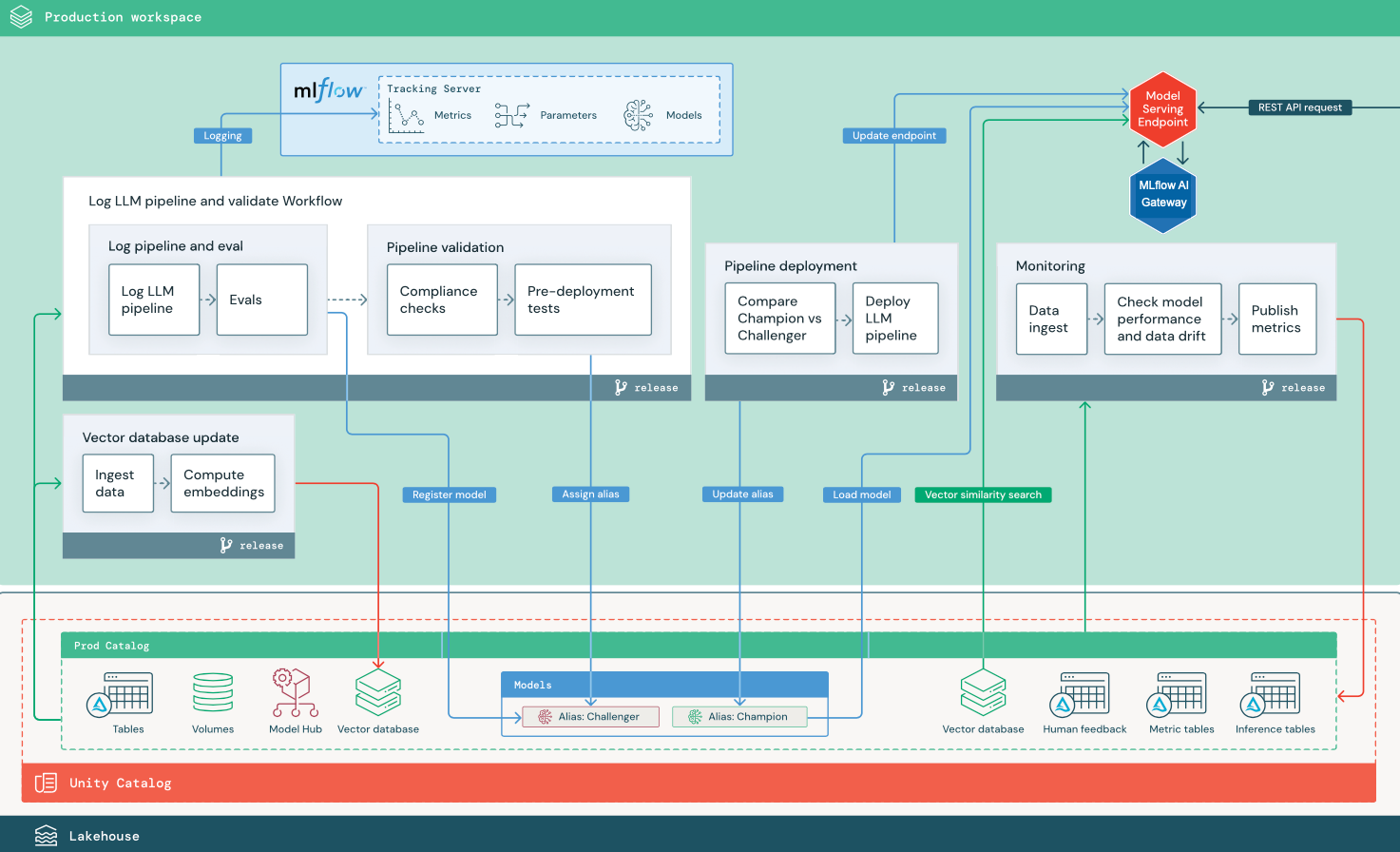
RAG com um modelo de código aberto finamente ajustado
O diagrama mostra uma arquitetura de produção para um aplicativo RAG que ajusta um modelo de código aberto.

Alterações de LLMOps na arquitetura de produção do MLOps
Esta seção destaca as principais alterações na arquitetura de referência do MLOps para aplicativos LLMOps.
Hub de modelos
Os aplicativos de LLM geralmente usam modelos existentes e pré-treinados selecionados de um hub de modelos interno ou externo. O modelo pode ser usado como está ou ajustado.
O Databricks inclui uma seleção de modelos de base pré-treinados e de alta qualidade no Catálogo do Unity e no Databricks Marketplace. Você pode usar esses modelos pré-treinados para acessar recursos de IA de última geração, economizando tempo e custos de criação de seus próprios modelos personalizados. Para obter detalhes, consulte Acesse modelos de IA generativa e LLM do Catálogo do Unity.
Índice vetorial
Alguns aplicativos LLM usam índices de vetor para pesquisas de similaridade rápidas, por exemplo, para fornecer contexto ou conhecimento de domínio em consultas LLM. O Databricks fornece uma funcionalidade de pesquisa de vetor integrada que permite que você use qualquer tabela Delta no Catálogo do Unity como um índice de vetor. O índice de busca em vetores é sincronizado automaticamente com a tabela Delta. Para obter detalhes, confira Busca em Vetores.
Você pode criar um artefato de modelo que encapsula a lógica para recuperar informações de um índice vetorial e usa os dados retornados como contexto para o LLM. Em seguida, você pode registrar o modelo usando o modelo MLflow LangChain ou PyFunc.
Ajuste de LLM
Como os modelos de LLM são caros e demorados para criar do zero, os aplicativos de LLM geralmente ajustam um modelo existente para melhorar seu desempenho em um cenário específico. Na arquitetura de referência, o ajuste fino e a implantação de modelo são representados como trabalhos distintos do Lakeflow. Validar um modelo ajustado antes da implantação geralmente é um processo manual.
O Databricks fornece o ajuste fino do modelo de base, que permite usar seus próprios dados para personalizar um LLM existente para otimizar seu desempenho para seu aplicativo específico. Para obter detalhes, confira Ajuste fino do modelo de base.
Serviço de modelo
No RAG usando um cenário de API de terceiros, uma alteração de arquitetura importante é que o pipeline de LLM faz chamadas de API externas, desde o ponto de extremidade do Serviço de Modelo até as APIs de LLM internas ou de terceiros. Isso adiciona complexidade, latência potencial e gerenciamento de credenciais adicionais.
O Databricks fornece o Serviço de Modelo de IA do Mosaic, que fornece uma interface unificada para implantar, governar e consultar modelos de IA. Para obter detalhes, confira Serviço de Modelo de IA do Mosaic.
Comentários humanos no monitoramento e avaliação
Os ciclos de feedback humano são essenciais na maioria das aplicações de LLM. Os feedbacks humanos devem ser gerenciados como outros dados, idealmente integrados ao monitoramento com base no streaming quase em tempo real.
O aplicativo de revisão do Mosaic AI Agent Framework ajuda você a coletar comentários de revisores humanos. Para obter detalhes, consulte Use o aplicativo de revisão para revisões feitas por humanos de um aplicativo de IA de geração (MLflow 2).