Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
Esse recurso está em Visualização Pública.
Este artigo mostra como executar um experimento de previsão sem necessidade de servidor usando o Mosaic AI Model Training UI.
O Treinamento de Modelo de IA do Mosaico simplifica a previsão de dados de série temporal ao selecionar automaticamente o melhor algoritmo e hiperparâmetros, enquanto é executado em recursos de computação totalmente gerenciados.
Para entender a diferença entre a previsão sem servidor e a previsão de computação clássica, consulte previsão sem servidor versus previsão de computação clássica.
Requisitos
- Dados de treinamento com uma coluna de série temporal, salva como uma tabela do Unity Catalog.
- Se o workspace tiver o SEG (Secure Egress Gateway) habilitado,
pypi.orgdeverá ser adicionado à lista de domínios permitidos . Consulte Gerenciar políticas de rede para controle de saída sem servidor.
Criar um experimento de previsão com a interface do usuário
Vá para a página inicial do Azure Databricks e clique em Experimentos na barra lateral.
No bloco Previsão , selecione Iniciar treinamento.
Selecione os dados de treinamento em uma lista de tabelas do Catálogo do Unity que você pode acessar.
-
Coluna de tempo: selecione a coluna que contém os períodos de tempo da série temporal. As colunas devem ser do tipo
timestampoudate. - Frequência de previsão: selecione a unidade de tempo que representa a frequência dos dados de entrada. Por exemplo, minutos, horas, dias, meses. Isso determina a granularidade de sua série temporal.
- Horizonte de previsão: especifique quantas unidades da frequência selecionada devem ser previstas para o futuro. Junto com a frequência de previsão, isso define as unidades de tempo e o número de unidades de tempo a serem previstas.
Observação
Para usar o algoritmo AUTO-ARIMA , a série temporal deve ter uma frequência regular em que o intervalo entre dois pontos deve ser o mesmo ao longo da série temporal. O AutoML manipula as etapas de tempo ausentes preenchendo esses valores com o valor anterior.
-
Coluna de tempo: selecione a coluna que contém os períodos de tempo da série temporal. As colunas devem ser do tipo
Selecione uma coluna alvo de previsão que você deseja que o modelo preveja.
Especifique, opcionalmente, um caminho de dados de previsão na tabela do Catálogo do Unity para armazenar as previsões de saída.
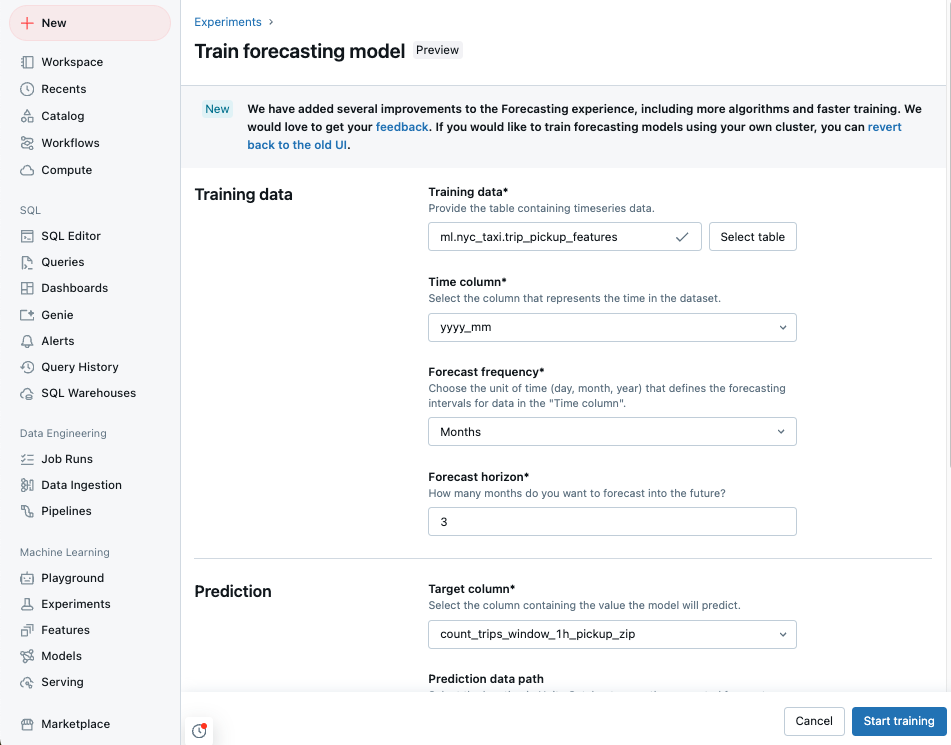
Selecione um local e um nome de registro de modelo do Catálogo do Unity.
Opcionalmente, defina opções avançadas:
- Nome do experimento: forneça um nome de experimento do MLflow.
- Colunas do identificador de série temporal – para previsão de várias séries, selecione as colunas que identificam a série temporal individual. O Databricks agrupa os dados por essas colunas como séries temporais diferentes e treina um modelo para cada série de forma independente.
- Métrica primária: escolha a métrica primária usada para avaliar e selecionar o melhor modelo.
- Estrutura de treinamento: escolha as estruturas para o AutoML explorar.
- Dividir coluna: selecione a coluna que contém a divisão de dados personalizada. Os valores devem ser "treinar", "validar", "testar"
- Coluna de peso: especifique a coluna a ser usada para a ponderação de séries temporais. Todos os exemplos de uma determinada série temporal devem ter o mesmo peso. O peso deve estar no intervalo [0, 10000].
- Região de férias: selecione a região de férias a ser usada como covariada no treinamento de modelo.
- Tempo limite: defina uma duração máxima para o experimento AutoML.
Execute o experimento e monitore os resultados
Para iniciar o experimento autoML, clique em Iniciar o treinamento. Na página de treinamento do experimento, você pode fazer o seguinte:
- Pare o experimento a qualquer momento.
- Monitorar execuções.
- Navegue até a página de execução para qualquer execução.
Além disso, você pode verificar o status do experimento conforme ele passa pelos seguintes estágios:
- Pré-processamento: Valide e prepare a tabela de entrada imputando valores ausentes e dividindo dados em conjuntos de treinamento, validação e teste. O processamento automático de geração de características, como a codificação binária para características categóricas, também é realizada durante esse estágio.
- Ajuste: Explore diferentes algoritmos de previsão e ajuste os hiperparâmetros.
- Formação: Treine e avalie o modelo final com as melhores configurações selecionadas. Registre o modelo no Catálogo do Unity se um caminho for especificado.
Exibir resultados ou usar o melhor modelo
Após a conclusão do treinamento, os resultados da previsão são armazenados na tabela Delta especificada e o melhor modelo é registrado no Catálogo do Unity.
Na página de experimentos, você escolhe entre as seguintes etapas:
- Selecione Exibir previsões para ver a tabela de resultados de previsão.
- Selecione o notebook de inferência em lote para abrir um notebook automaticamente gerado para inferência em lote usando o melhor modelo.
- Selecione Criar ponto de serviço para implantar o melhor modelo em um ponto de serviço de Model Serving.
Previsão sem servidor versus previsão de computação clássica
A tabela a seguir resume as diferenças entre previsão sem servidor e previsão com computação clássica
| Característica | Previsão sem servidor | Previsão de computação clássica |
|---|---|---|
| Infraestrutura de computação | O Azure Databricks gerencia a configuração de computação e otimiza automaticamente o custo e o desempenho. | Computação configurada pelo usuário |
| Governança | Modelos e artefatos registrados no Catálogo do Unity | Repositório de arquivos de workspace configurado pelo usuário |
| Escolha do algoritmo | Modelos estatísticos mais o algoritmo de rede neural de aprendizado profundo DeepAR | Modelos estatísticos |
| Integração do Feature Store | Sem suporte | Suportado |
| Notebooks gerados automaticamente | Caderno de inferência em lote | Código-fonte para todas as avaliações |
| Implantação de serviço de modelo de um clique | Suportado | Sem suporte |
| Divisões de treinamento/validação/teste personalizadas | Suportado | Sem suporte |
| Pesos personalizados para séries temporais individuais | Suportado | Sem suporte |