Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Databricks Runtime é compatível com fonte de dados de arquivo binário, que lê arquivos binários e os converte em um único registro com o conteúdo bruto e os metadados do arquivo. A fonte de dados do arquivo binário produz um DataFrame com as colunas a seguir e, possivelmente, colunas de partição:
-
path (StringType): o caminho do arquivo. -
modificationTime (TimestampType): date e hora de modificação do arquivo. Em algumas implementações de FileSystem do Hadoop, esse parâmetro pode estar indisponível e o valor seria definido como um valor padrão. -
length (LongType): o tamanho do arquivo em bytes. -
content (BinaryType): o conteúdo do arquivo.
Para ler arquivos binários, especifique a fonte de dados format como binaryFile.
Imagens
O Databricks recomenda usar a fonte de dados de arquivo binário para carregar dados de imagem.
A função Databricks display dá suporte à exibição de dados de imagem carregados usando a fonte de dados binária.
Se todos os arquivos carregados tiverem um nome de arquivo com uma extensão de imagem, a visualização da imagem será habilitada automaticamente:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
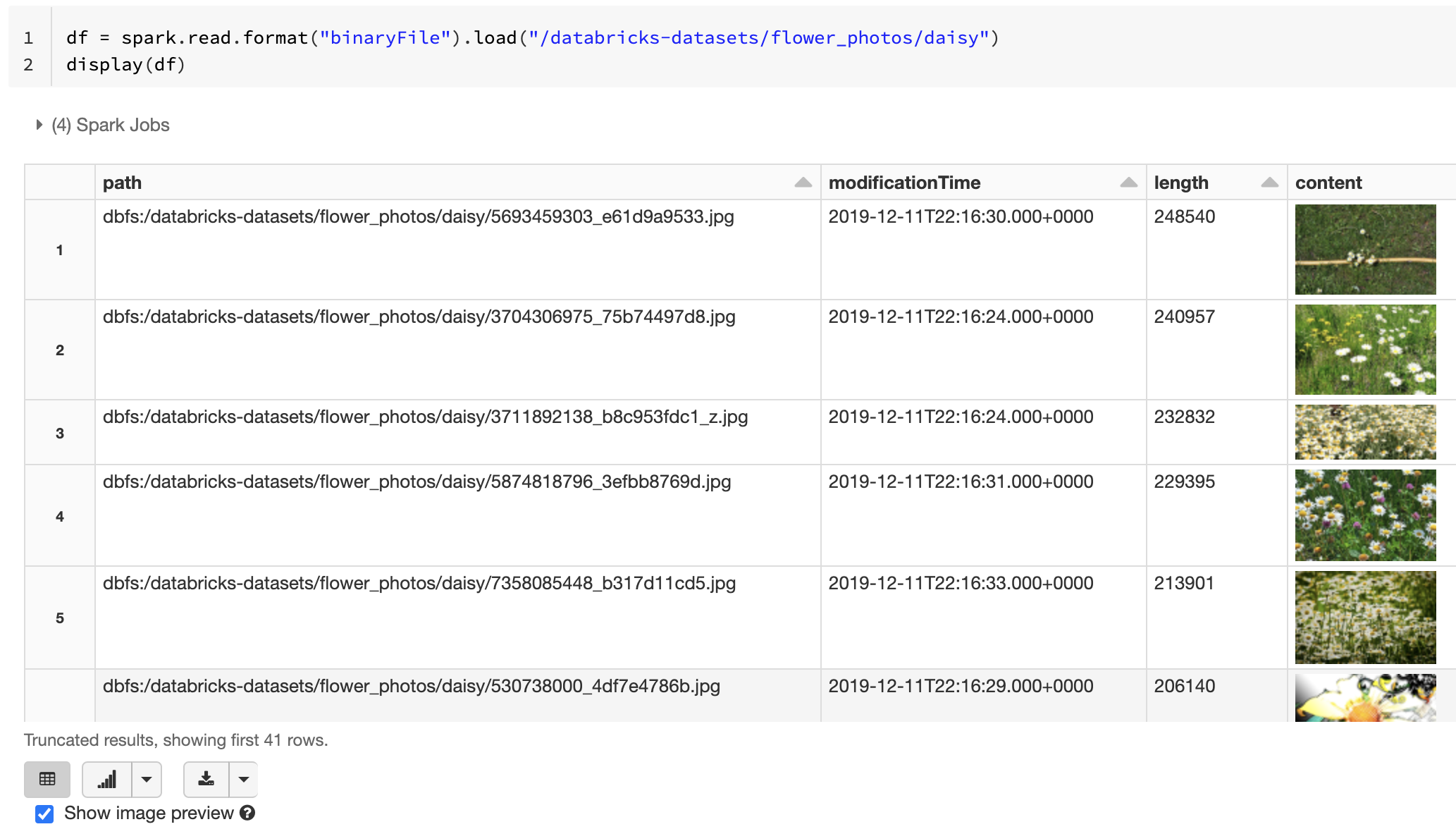
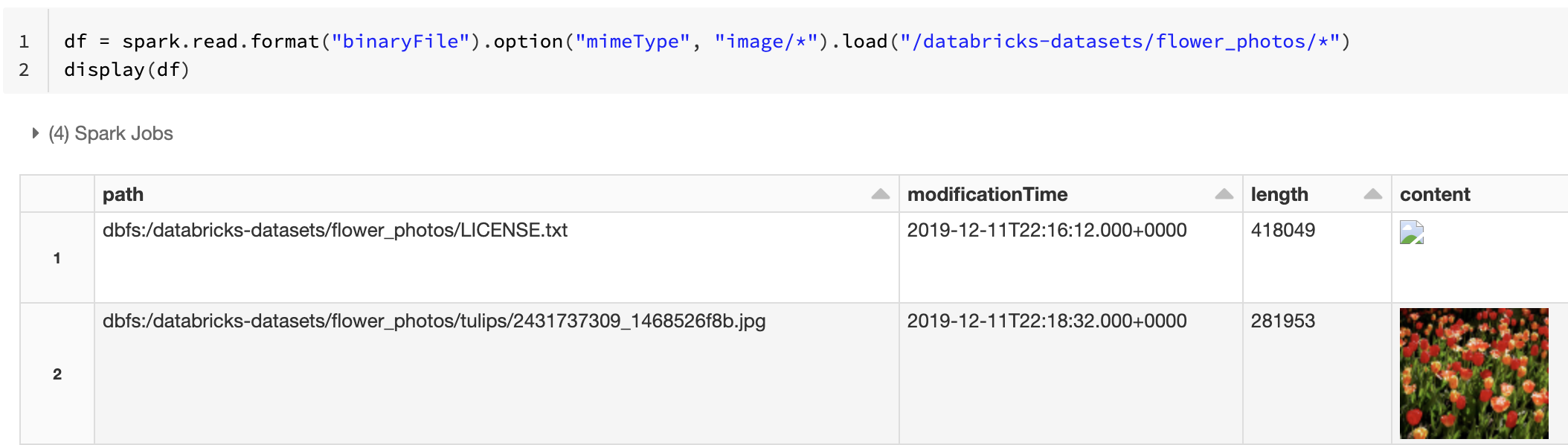
Como alternativa, você pode forçar a funcionalidade de visualização da imagem usando a opção mimeType com um valor "image/*" de cadeia de caracteres para explicar a coluna binária. As imagens são decodificadas com base nas respectivas informações de formato no conteúdo binário. Os tipos de imagem com suporte são bmp, gifjpeg e png. Os arquivos sem suporte aparecem como um ícone de imagem quebrada.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Consulte Solução de referência para aplicativos de imagem para informar-se sobre o fluxo de trabalho recomendado para manipular dados de imagem.
Opções
Para carregar arquivos com caminhos que correspondem a um determinado padrão glob e manter o comportamento da descoberta de partição, você pode usar a opção pathGlobFilter. O código a seguir lê todos os arquivos JPG do diretório de entrada com descoberta de partição:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Para ignorar a descoberta de partição e pesquisar arquivos recursivamente no diretório de entrada, use a opção recursiveFileLookup. Essa opção pesquisará diretórios aninhados, mesmo que os nomes deles não sigam um esquema de nomenclatura de partição como date=2019-07-01.
O código a seguir lê todos os arquivos JPG recursivamente do diretório de entrada e ignora a descoberta de partição:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Existem APIs semelhantes para Scala, Java e R.
Observação
Para aprimorar o desempenho de leitura quando você carrega os dados novamente, o Azure Databricks recomenda salvar os dados carregados dos arquivos de binários usando tabelas Delta:
df.write.save("<path-to-table>")