Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Regulamento Geral de Proteção de Dados (GDPR) e a Lei de Privacidade do Consumidor da Califórnia (CCPA) são regulamentos de privacidade e segurança de dados que exigem que as empresas excluam permanente e completamente todas as informações de identificação pessoal (PII) coletadas sobre um cliente após sua solicitação explícita. Também conhecida como RTBF ("direito de ser esquecido" ou "direito à eliminação de dados", as solicitações de exclusão devem ser executadas durante um período especificado (por exemplo, dentro de um mês do calendário).
Este artigo orienta você sobre como implementar o RTBF em dados armazenados no Databricks. O exemplo incluído neste artigo modela conjuntos de dados para uma empresa de comércio eletrônico e mostra como excluir dados em tabelas de origem e propagar essas alterações para tabelas downstream.
Blueprint para implementar o "direito de ser esquecido"
O diagrama a seguir ilustra como implementar o "direito de ser esquecido".

Exclusões do ponto com o Delta Lake
O Delta Lake acelera a exclusão dos pontos em grandes data lakes com transações ACID, permitindo que você localize e remova informações de identificação pessoal (PII) em resposta às solicitações de GDPR ou de CCPA do consumidor.
O Delta Lake retém o histórico da tabela e o disponibiliza para consultas e reversões pontuais. A VACUUM função remove arquivos de dados que não são mais referenciados por uma tabela Delta e são mais antigos do que um limite de retenção especificado, excluindo permanentemente os dados. Para saber mais sobre padrões e recomendações, consulte Trabalhar com o histórico das tabelas do Delta Lake.
Verifique se os dados são excluídos ao usar vetores de exclusão
Para tabelas com vetores de exclusão habilitados, depois de excluir registros, você também deve executar REORG TABLE ... APPLY (PURGE) para excluir permanentemente registros subjacentes. Isso inclui tabelas do Delta Lake, exibições materializadas e tabelas de streaming. Confira Aplicar alterações aos arquivos de dados Parquet.
Excluir dados em fontes upstream
GDPR e CCPA se aplicam a todos os dados, incluindo dados em fontes fora do Delta Lake, como Kafka, arquivos e bancos de dados. Além de excluir dados no Databricks, você também deve se lembrar de excluir dados em fontes upstream, como filas e armazenamento em nuvem.
Observação
Antes de implementar fluxos de trabalho de exclusão de dados, talvez seja necessário exportar dados do workspace para fins de conformidade ou backup. Consulte Exportar dados do workspace.
A exclusão completa é preferível à ofuscação
Você precisa escolher entre excluir dados e ofuscar. A ofuscação pode ser implementada usando pseudonimização, mascaramento de dados etc. No entanto, a opção mais segura é a eliminação completa porque, na prática, eliminar o risco de reidentificação geralmente requer uma exclusão completa dos dados de PII.
Excluir dados na camada bronze e, em seguida, propagar exclusões para a camada prata e a camada ouro.
Recomendamos que você inicie a conformidade com GDPR e CCPA excluindo os dados na camada bronze primeiro, mediante um trabalho agendado que consulta uma tabela de pedidos de exclusão. Depois que os dados são excluídos da camada bronze, as alterações podem ser propagadas para camadas de prata e ouro.
Manter tabelas regularmente para remover dados de arquivos históricos
Por padrão, o Delta Lake mantém o histórico da tabela, incluindo registros excluídos, por 30 dias e o disponibiliza para viagens no tempo e reversões. No entanto, mesmo que as versões anteriores dos dados sejam removidas, os dados ainda serão mantidos no armazenamento em nuvem. Portanto, você deve manter regularmente conjuntos de dados para remover versões anteriores de dados. A maneira recomendada é a Otimização preditiva para tabelas gerenciadas do Unity Catalog, que mantém de maneira inteligente tabelas de streaming e exibições materializadas.
- Para tabelas gerenciadas pela otimização preditiva, o Lakeflow Spark Declarative Pipelines mantém inteligentemente tabelas de streaming e exibições materializadas, com base em padrões de uso.
- Para tabelas sem otimização preditiva habilitada, o Lakeflow Spark Declarative Pipelines executa automaticamente tarefas de manutenção dentro de 24 horas após a atualização de tabelas de streaming e exibições materializadas.
Se você não estiver usando otimização preditiva ou os Pipelines Declarativos do Lakeflow Spark, deverá executar o comando VACUUM em tabelas Delta para remover permanentemente as versões anteriores dos dados. Por padrão, isso reduzirá os recursos de viagem no tempo para 7 dias, que é uma configuração configurávele removerá versões históricas dos dados em questão do armazenamento em nuvem também.
Excluir dados de PII da camada bronze
Dependendo do design de seu lakehouse, você pode conseguir eliminar o vínculo entre dados de usuário que contêm e que não contêm PII. Por exemplo, se você estiver usando uma chave não natural, como user_id, em vez de uma chave natural, como um e-mail, poderá excluir informações de identificação pessoal (PII), enquanto as informações não PII são mantidas.
O restante deste artigo aborda a RTBF excluindo completamente registros de usuário de todas as tabelas bronze. Você pode excluir dados executando um comando DELETE, conforme mostrado no seguinte código:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
Ao excluir um grande número de registros juntos ao mesmo tempo, recomendamos usar o comando MERGE. O código a seguir pressupõe que você tenha uma tabela de controle chamada gdpr_control_table que contém uma coluna user_id. Você insere um registro nesta tabela para cada usuário que solicitou o "direito de ser esquecido" nesta tabela.
O comando MERGE especifica a condição para a correspondência de linhas. Neste exemplo, é feita a correspondência entre registros de target_table com registros em gdpr_control_table com base no user_id. Se houver uma correspondência (por exemplo, um user_id no target_table e no gdpr_control_table), a linha no target_table será excluída. Depois que esse comando MERGE for bem-sucedido, atualize a tabela de controle para confirmar se a solicitação foi processada.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Propagar alterações da camada bronze para as camadas prata e ouro
Depois que os dados são excluídos na camada bronze, você deve propagar as alterações para as tabelas nas camadas prata e ouro.
Exibições materializadas: lidar automaticamente com exclusões
Exibições materializadas lidam automaticamente com exclusões nas origens. Portanto, você não precisa fazer nada especial para garantir que uma exibição materializada não contenha dados que foram excluídos de uma fonte. Você deve atualizar uma exibição materializada e executar a manutenção para assegurar que as exclusões sejam processadas completamente.
Uma exibição materializada sempre retorna o resultado correto porque usa a computação incremental se for mais barata do que a recomputação completa, mas nunca ao custo da correção. Em outras palavras, a exclusão de dados de uma origem pode fazer com que uma exibição materializada seja totalmente recomputada.

Tabelas de streaming: excluir dados e ler fonte de streaming usando skipChangeCommits
As tabelas de streaming processam dados somente de acréscimo quando são transmitidos de fontes de tabelas Delta. Qualquer outra operação, como atualizar ou excluir um registro de uma fonte de streaming, não tem suporte e interrompe o fluxo.
Observação
Para uma implementação de streaming mais robusta, transmita a partir dos fluxos de alterações das tabelas Delta e manipule atualizações e deleções no seu código de processamento. Consulte Opção 1: Transmitir de um feed CDC (captura de dados de mudanças).

Como o streaming de tabelas Delta manipula apenas novos dados, você deve lidar com alterações nos dados por conta própria. O método recomendado é: (1) excluir dados nas tabelas Delta de origem usando DML, (2) excluir dados da tabela de streaming usando DML e, em seguida, (3) atualizar a leitura de streaming para usar skipChangeCommits. Esse sinalizador indica que a tabela de streaming deve ignorar qualquer coisa que não seja inserções, como atualizações ou exclusões.

Como alternativa, você pode (1) excluir dados da origem e, em seguida, (2) atualizar totalmente a tabela de streaming. Quando você atualiza totalmente uma tabela de streaming, ela limpa o estado de streaming da tabela e reprocessa todos os dados novamente. Qualquer fonte de dados upstream que esteja além de seu período de retenção (por exemplo, um tópico Kafka que exclui os dados após 7 dias) não será processada outra vez, o que pode causar perda de dados. Recomendamos essa opção para tabelas de streaming apenas no cenário em que os dados históricos estão disponíveis e processá-los novamente não será caro.

Exemplo: conformidade com GDPR e CCPA para uma empresa de comércio eletrônico
O diagrama a seguir mostra uma arquitetura medalhão para uma empresa de comércio eletrônico em que a conformidade com a GDPR e a CCPA precisa ser implementada. Mesmo que os dados de um usuário sejam excluídos, talvez você queira contar suas atividades em agregações downstream.
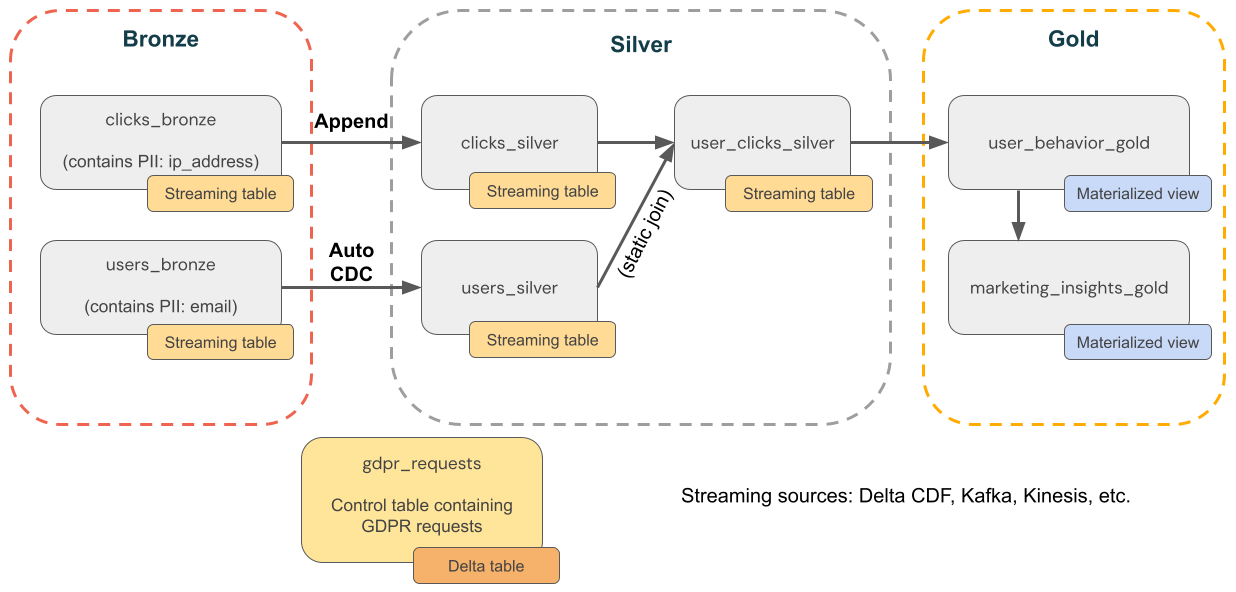
-
Tabelas de origem
-
source_users- Uma tabela de origem de streaming de usuários (criada aqui, para o exemplo). Ambientes de produção normalmente usam Kafka, Kinesis ou plataformas de streaming semelhantes. -
source_clicks- Uma tabela de origem de streaming de cliques (criada aqui, como exemplo). Ambientes de produção normalmente usam Kafka, Kinesis ou plataformas de streaming semelhantes.
-
-
Tabela de controle
-
gdpr_requests- Tabela de controle que contém IDs de usuário sujeitas ao "direito de ser esquecido". Quando um usuário solicita ser removido, adicione-o aqui.
-
-
Camada bronze
-
users_bronze– Dimensões do usuário. Contém PII (por exemplo, endereço de email). -
clicks_bronze– Eventos de clique. Contém PII (por exemplo, endereço IP).
-
-
camada prata
-
clicks_silver– Dados de cliques limpos e padronizados. -
users_silver- Dados de usuário limpos e padronizados. -
user_clicks_silver- Uneclicks_silver(streaming) com um instantâneo deusers_silver.
-
-
camada dourada
-
user_behavior_gold- Métricas de comportamento do usuário agregadas. -
marketing_insights_gold– Segmentação de usuário para insights de mercado.
-
Etapa 1: Preencher tabelas com dados de exemplo
O código a seguir cria estas duas tabelas para este exemplo e as preenche com dados de exemplo:
-
source_userscontém dados dimensionais sobre usuários. Esta tabela contém uma coluna PII chamadaemail. -
source_clickscontém dados de evento sobre as atividades executadas pelos usuários. Ele contém uma coluna PII chamadaip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Etapa 2: Criar um pipeline que processa dados PII
O código a seguir cria camadas de bronze, prata e ouro da arquitetura de medalhão mostrada anteriormente.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dp.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dp.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dp.create_streaming_table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dp.view
@dp.expect_or_drop('valid_email', "email IS NOT NULL")
def users_bronze_view():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.users_silver",
source="users_bronze_view",
keys=["user_id"],
sequence_by="registration_date",
)
@dp.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dp.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dp.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame - each refresh
# will use a snapshot of the users_silver table.
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame.
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join - join of a static dataset with a
# streaming dataset creates a streaming table.
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dp.materialized_view(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dp.materialized_view(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Etapa 3: Excluir dados em tabelas de origem
Nesta etapa, você exclui dados em todas as tabelas em que a PII é encontrada. A função a seguir remove todas as instâncias dos dados pessoais de identificação (PII) de um usuário de tabelas com PII.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Etapa 4: Adicionar skipChangeCommits a definições de tabelas de streaming afetadas
Nesta etapa, você deve especificar ao Lakeflow Spark Declarative Pipelines para ignorar linhas não-acrescentadas. Adicione a opção skipChangeCommits aos métodos a seguir. Você não precisa atualizar as definições de exibições materializadas porque elas lidarão automaticamente com atualizações e exclusões.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
O código a seguir mostra como atualizar o método users_bronze:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
Quando você executar o pipeline novamente, ele será atualizado com êxito.