Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A atividade do Azure Databricks no Data Factory para Microsoft Fabric permite orquestrar os seguintes trabalhos do Azure Databricks:
- Notebook
- JAR
- Python
- Job
Este artigo fornece um passo a passo que descreve como criar uma atividade do Azure Databricks usando a interface do usuário do Data Factory.
Pré-requisitos
Para começar, você deve concluir os seguintes pré-requisitos:
- Uma conta de locatário com uma assinatura ativa. Crie uma conta gratuitamente.
- Um workspace é criado.
Configurando uma atividade do Azure Databricks
Para usar uma atividade do Azure Databricks em um pipeline, conclua as seguintes etapas:
Configurando a conexão
Crie um pipeline no seu workspace.
Selecione Adicionar atividade de pipeline e pesquise por Azure Databricks.

Como alternativa, você pode pesquisar o Azure Databricks no painel Atividades do pipeline e selecioná-lo para adicioná-lo à tela do pipeline.

Selecione a nova atividade do Azure Databricks na tela se ela ainda não estiver selecionada.

Consulte as diretrizes de Configurações Geraispara definir a guia Configurações Gerais.
Configurando os clusters
Selecione a guia Cluster. Em seguida, você pode escolher uma conexão existente ou criar uma nova conexão do Azure Databricks e, em seguida, escolher um novo cluster de trabalho, um cluster interativo existente ou um pool de instâncias existente.
Dependendo do que você escolher para o cluster, preencha os campos correspondentes conforme apresentado.
- Em novo cluster de trabalho e pool de instâncias existente, você também tem a capacidade de configurar o número de trabalhadores e habilitar instâncias spot.
Você também pode especificar outras configurações de cluster, como política de cluster, configuração do Spark, variáveis de ambiente do Spark e marcas personalizadas, conforme necessário para o cluster ao qual você está se conectando. Os scripts de inicialização do Databricks e o caminho de destino do Log de Cluster também podem ser adicionados nas configurações adicionais de cluster.
Observação
Todas as propriedades de cluster avançadas e expressões dinâmicas com suporte no serviço vinculado do Azure Data Factory Azure Databricks agora também têm suporte na atividade do Azure Databricks no Microsoft Fabric na seção "Configuração de cluster adicional" na interface do usuário. Como essas propriedades agora estão incluídas na interface do usuário da atividade, elas podem ser usadas com uma expressão (conteúdo dinâmico) sem a necessidade da especificação JSON Avançada.

A atividade do Azure Databricks agora também oferece suporte à Política de Cluster e ao Catálogo Unity.
- Em configurações avançadas, você pode escolher a Política de Cluster para especificar quais configurações de cluster são permitidas.
- Além disso, em configurações avançadas, você pode configurar o Modo de Acesso do Catálogo do Unity para maior segurança. Os tipos de modo de acesso disponíveis são:
- Modo de Acesso para Usuário Único Esse modo foi projetado para cenários em que cada cluster é usado por um único usuário. Ele garante que o acesso aos dados no cluster seja restrito apenas a esse usuário. Esse modo é útil para tarefas que exigem isolamento e tratamento individual de dados.
- Modo de Acesso Compartilhado Nesse modo, vários usuários podem acessar o mesmo cluster. Ele combina a governança de dados do Unity Catalog com as listas de controle de acesso (ACLs) de tabelas herdadas. Esse modo permite o acesso colaborativo a dados, mantendo protocolos de governança e segurança. No entanto, ele tem certas limitações, como não oferecer suporte ao Databricks Runtime ML, a trabalhos de envio do Spark e a APIs e UDFs específicas do Spark.
- Sem Modo de Acesso Esse modo desabilita a interação com o Catálogo do Unity, o que significa que os clusters não têm acesso aos dados gerenciados pelo Catálogo do Unity. Esse modo é útil para cargas de trabalho que não exigem recursos de governança do Catálogo do Unity.

Definindo as configurações
Selecionando a guia Configurações , você pode escolher entre 4 opções do tipo do Azure Databricks que deseja orquestrar.

Orquestrando o tipo Notebook na atividade do Azure Databricks:
Na guia Configurações, você pode escolher o botão de opção Notebook para executar um Notebook. Você precisa especificar o caminho do notebook a ser executado no Azure Databricks, parâmetros base opcionais a serem passados para o notebook e quaisquer bibliotecas extras a serem instaladas no cluster para executar o trabalho.

Orquestrando o tipo Jar na atividade do Azure Databricks:
Na guia Configurações, você pode escolher o botão de opção Jar para executar um Jar. Você precisa especificar o nome da classe a ser executado no Azure Databricks, parâmetros base opcionais a serem passados para o Jar e quaisquer bibliotecas adicionais a serem instaladas no cluster para executar o trabalho.

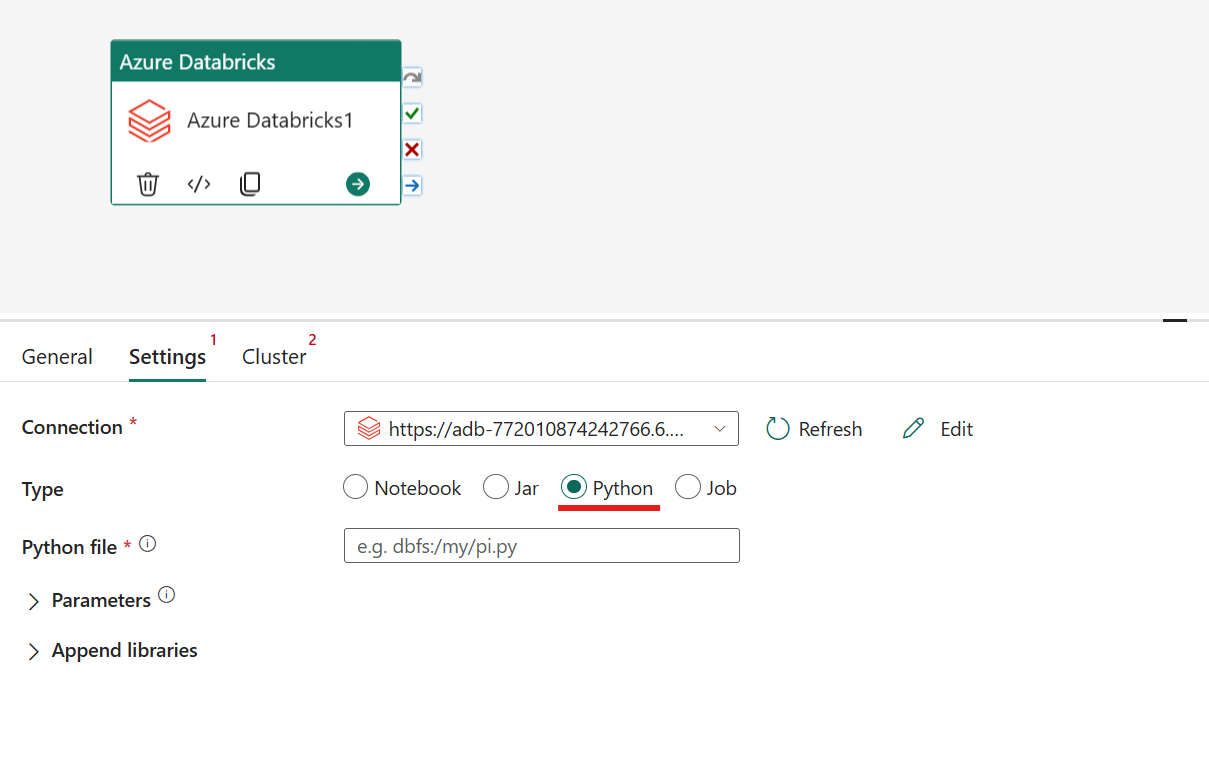
Orquestrando o tipo Python na atividade do Azure Databricks:
Na guia Configurações, você pode escolher o botão de opção Python para executar um arquivo Python. Você precisa especificar o caminho no Azure Databricks para um arquivo Python a ser executado, parâmetros base opcionais a serem passados e quaisquer bibliotecas adicionais a serem instaladas no cluster para executar o trabalho.
Orquestrando o tipo de trabalho na atividade do Azure Databricks:
Na guia Configurações , você pode escolher o botão de opção Trabalho para executar um Trabalho do Databricks. Você precisa especificar o Job usando a lista suspensa para ser executado no Azure Databricks e passar quaisquer parâmetros opcionais do Job. Você pode executar trabalhos sem servidor com essa opção.

Bibliotecas com suporte para a atividade do Azure Databricks
Na definição da atividade do Databricks acima, você especifica esses tipos de biblioteca: jar, egxg, whl, maven, pypi, cran.
Para obter mais informações, consulte a documentação do Databricks para tipos de biblioteca.
Passando parâmetros entre a atividade do Azure Databricks e os pipelines
Você pode passar parâmetros para notebooks usando a propriedade baseParameters na atividade do Databricks.

Às vezes, pode ser necessário retornar valores de um notebook para o serviço, visando o controle de fluxo ou uso em atividades subsequentes (com um limite de tamanho de 2 MB).
No caderno, por exemplo, você pode chamar dbutils.notebook.exit("returnValue") e o "returnValue" correspondente será retornado ao serviço.
Você pode consumir a saída no serviço usando expressão como
@{activity('databricks activity name').output.runOutput}.
Salvar e executar ou agendar o pipeline
Após configurar quaisquer outras atividades exigidas pelo pipeline, alterne para a guia Página Inicial na parte superior do editor do pipeline e selecione o botão Salvar para salvar o pipeline. Selecione Executar para executá-lo diretamente ou Agendar para agendá-lo. Você também pode exibir o histórico de execuções aqui ou definir outras configurações.
