Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Para obter informações gerais sobre a detecção de anomalias multivariadas na Inteligência em Tempo Real, confira Detecção de anomalias multivariadas no Microsoft Fabric - visão geral. Neste tutorial, você usará dados de exemplo para treinar um modelo de detecção de anomalias multivariada usando o mecanismo Spark em um notebook Python. Em seguida, você prevê anomalias aplicando o modelo treinado a novos dados usando o mecanismo eventhouse. As primeiras etapas configuram os ambientes e as etapas seguintes treinam o modelo e preveem as anomalias.
Pré-requisitos
- Um espaço de trabalho com uma capacidade habilitada para o Microsoft Fabric
- Função de Administrador, Contribuidor ou Membrono espaço de trabalho. Esse nível de permissão é necessário para criar itens como um Ambiente.
- Uma casa de eventos em seu workspace com um banco de dados.
- Baixe os dados de exemplo do repositório GitHub
- Baixe o notebook do repositório GitHub
Parte 1 - Habilitar a disponibilidade do OneLake
A disponibilidade do OneLake deve ser habilitada antes de obter dados no Eventhouse. Essa etapa é importante, pois permite a disponibilização dos dados ingeridos no OneLake. Em uma etapa posterior, esses mesmos dados serão acessados do Notebook do Spark para treinar o modelo.
Em seu workspace, selecione o Eventhouse que você criou como pré-requisito. Escolha o banco de dados para o qual deseja carregar os dados.
No painel Detalhes do banco de dados, alterne o botão de disponibilidade do OneLake para Ativado.

Parte 2 - Ativar o plug-in KQL Python
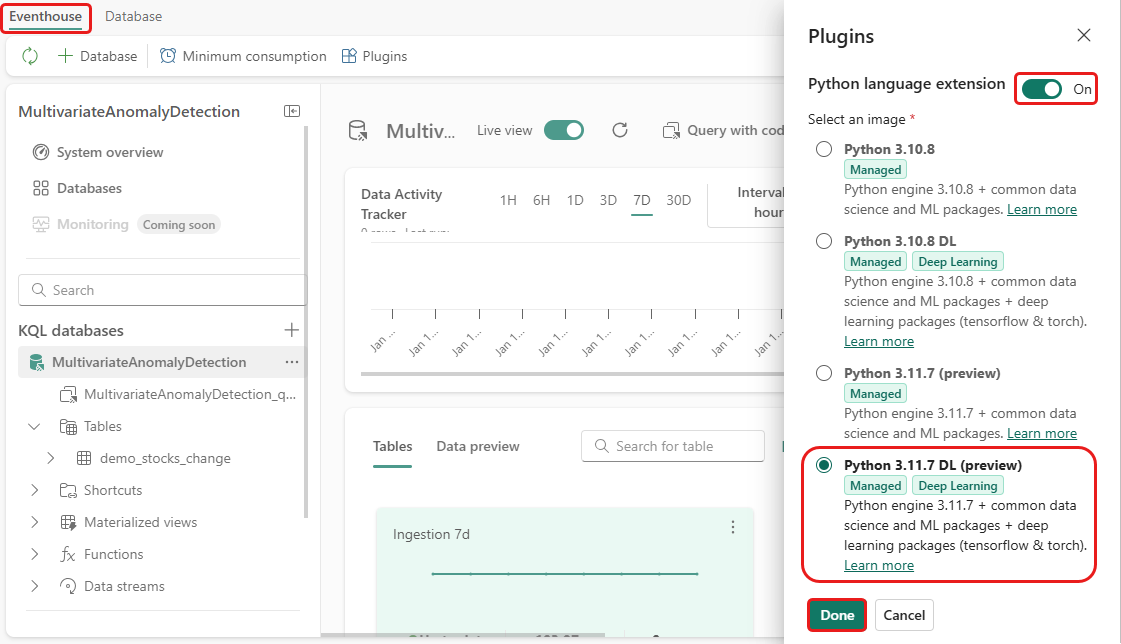
Nesta etapa, você habilita o plug-in do python no Eventhouse. Esta etapa é necessária para executar o código Python de previsão de anomalias no queryset KQL. É importante escolher a imagem correta que contém o pacote detector de anomalias em séries temporais .
Na tela Eventhouse, selecione Eventhouse>Plugins na faixa de opções.
No painel Plug-ins, alterne a extensão de linguagem Python para Ativada.
Selecione Python 3.11.7 DL (versão prévia).
Selecione Concluído.

Parte 3 - Criar um ambiente do Spark
Nesta etapa, você cria um ambiente do Spark para executar o notebook do Python que treina o modelo de detecção de anomalias multivariadas usando o mecanismo do Spark. Para obter mais informações sobre a criação de ambientes, confira Criar e gerenciar ambientes.
No seu espaço de trabalho, selecione + Novo item e depois Ambiente.

Insira o nome MVAD_ENV para o ambiente e selecione Criar.
Em Bibliotecas, selecione Bibliotecas públicas.
Selecione Adicionar do PyPI.
Na caixa de pesquisa, digite time-series-anomaly-detector. O campo de versão é preenchido automaticamente com a versão mais recente. Altere-a para a versão 0.3.9, que é a versão mais recente compatível com o MLflow 2.19.0 (a versão atual na imagem do Python)
Selecione Salvar.

Selecione a guia Início no ambiente.
Na faixa de opções, selecione o ícone Publicar.

Selecione Publicar tudo. Essa etapa pode levar vários minutos para ser concluída.



Parte 4 - Obter dados para o Eventhouse
Passe o mouse sobre o banco de dados KQL no qual deseja armazenar seus dados. Selecione o menu Mais [...]>Obter dados>Arquivo local.

Selecione + Nova tabela e digite demo_stocks_change como o nome da tabela.
Na caixa de diálogo de upload de dados, selecione Procurar arquivos e carregue o arquivo de dados de exemplo baixado nos Pré-requisitos
Selecione Avançar.
Na seção Inspecionar os dados, verifique se A primeira linha é o cabeçalho da coluna está definido como Ativado.
Selecione Concluir.
Após a conclusão do carregamento, selecione Fechar.
Parte 5 - Copiar o caminho do OneLake para a tabela
Selecione a tabela demo_stocks_change. No painel Detalhes da tabela, selecione Pasta do OneLake para copiar o caminho do OneLake para a área de transferência. Salve o texto copiado em um editor de texto em algum local usar em uma etapa posterior.

Parte 6 – Preparar o notebook
Selecione o espaço de trabalho.
Selecione Importar, Notebook e, em seguida Deste computador.
Selecione Upload e escolha o notebook que você baixou nos pré-requisitos.
Depois que o notebook for carregado, você poderá encontrar e abrir seu notebook no espaço de trabalho.
Na faixa de opções superior, selecione a lista suspensaPadrão do workspace e selecione o ambiente que criou na etapa anterior.

Parte 7- Executar o notebook
Importe os pacotes padrão.
import numpy as np import pandas as pdO Spark precisa de um URI ABFSS para se conectar com segurança ao armazenamento do OneLake. Portanto, a próxima etapa define essa função para converter o URI do OneLake em URI ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriSubstitua o espaço reservado OneLakeTableURI pelo seu URI OneLake copiado da Parte 5 - Copie o caminho OneLake para a tabela para carregar a tabela demo_stocks_change em um dataframe pandas.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Execute as células a seguir para preparar os dataframes de treinamento e previsão.
Observação
As previsões reais serão executadas em dados pelo Eventhouse empart 9 - Predict-anomalies-in-the-kql-queryset. Em um cenário de produção, se você estivesse transmitindo dados para o eventhouse, as previsões seriam feitas nos novos dados de streaming. Para fins do tutorial, o conjunto de dados foi dividido por data em duas seções para treinamento e previsão. Isso é feito para simular dados históricos e novos dados de streaming.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Execute as células para treinar o modelo e salvá-lo no registro de modelos de MLflow do Fabric.
from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)model_name = "mvad_5_stocks_model"import mlflow with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name=model_name, )Execute a célula a seguir para extrair o caminho do modelo registrado a ser usado para previsão usando o sandbox do Kusto Python.
from mlflow.tracking import MlflowClient client = MlflowClient() mvs = client.search_model_versions(f"name='{model_name}'") latest = max(mvs, key=lambda v: v.creation_timestamp) model_abfss = latest.source print(model_abfss)Copie o URI do modelo da última saída da célula para uso em uma etapa posterior.
Parte 8 - Configurar o conjunto de consultas KQL
Para obter informações gerais, confira Criar um conjunto de consultas KQL.
- No espaço de trabalho, selecione +Novo item>Conjunto de consultas KQL.
- Insira o nome MultivariateAnomalyDetectionTutoriale, em seguida, selecione Criar.
- Na janela do hub de dados do OneLake, selecione o banco de dados KQL em que você armazenou os dados.
- Selecione Conectar.
Parte 9 – Prever anomalias no conjunto de consultas KQL
Execute a seguinte consulta ‘.create-or-alter function’ para definir a função
predict_fabric_mvad_fl()armazenada:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Execute a consulta de previsão a seguir, substituindo o URI do modelo de saída pelo URI copiado no final de etapa 7.
A consulta detecta anomalias multivariadas nos cinco estoques, com base no modelo treinado, e renderiza os resultados como
anomalychart. Os pontos anômalos são renderizados na primeira ação (AAPL), embora representem anomalias multivariadas, ou seja, anomalias das mudanças conjuntas das cinco ações na data específica.let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
O gráfico de anomalia resultante deve ser semelhante à imagem a seguir:

Limpar os recursos
Ao concluir o tutorial, você poderá excluir os recursos criados para evitar incorrer em outros custos. Para excluir os recursos, siga estas etapas:
- Navegue até a home page do espaço de trabalho.
- Exclua o ambiente criado neste tutorial.
- Exclua o notebook criado neste tutorial.
- Exclua o Eventhouse ou o banco de dados usado neste tutorial.
- Exclua o conjunto de consultas KQL criado neste tutorial.