Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Criar um modelo dimensional é uma das tarefas mais comuns que você pode fazer com um fluxo de dados. Este artigo destaca algumas das práticas recomendadas para criar um modelo dimensional usando um fluxo de dados.
Fluxos de dados intermediários
Um dos principais pontos em qualquer sistema de integração de dados é reduzir o número de leituras do sistema operacional de origem. Na arquitetura de integração de dados tradicional, essa redução é feita criando um novo banco de dados chamado banco de dados de preparo. A finalidade do banco de dados de estágio é carregar dados como está da fonte de dados para o banco de dados de estágio em uma programação regular.
Em seguida, o resto da integração de dados usa o banco de dados de preparo como a origem para uma transformação adicional e o converte em uma estrutura de modelo dimensional.
Recomendamos que você siga a mesma abordagem usando fluxos de dados. Crie um conjunto de fluxos de dados que são responsáveis por carregar apenas os dados tal como estão do sistema fonte (e somente para as tabelas que você precisa). Em seguida, o resultado é armazenado na estrutura de armazenamento do fluxo de dados (Azure Data Lake Storage ou Dataverse). Essa alteração garante que a operação de leitura do sistema de origem seja mínima.
Em seguida, você pode criar outros fluxos de dados que obtêm seus dados de fluxos de dados de pré-processamento. Os benefícios dessa abordagem incluem:
- Reduzindo o número de operações de leitura do sistema de origem e reduzindo a carga no sistema de origem como resultado.
- Reduzindo a carga em gateways de dados caso uma fonte de dados local seja utilizada.
- Ter uma cópia intermediária dos dados para fins de reconciliação, caso os dados do sistema de origem sejam alterados.
- Tornando os fluxos de dados de transformação independentes da fonte.
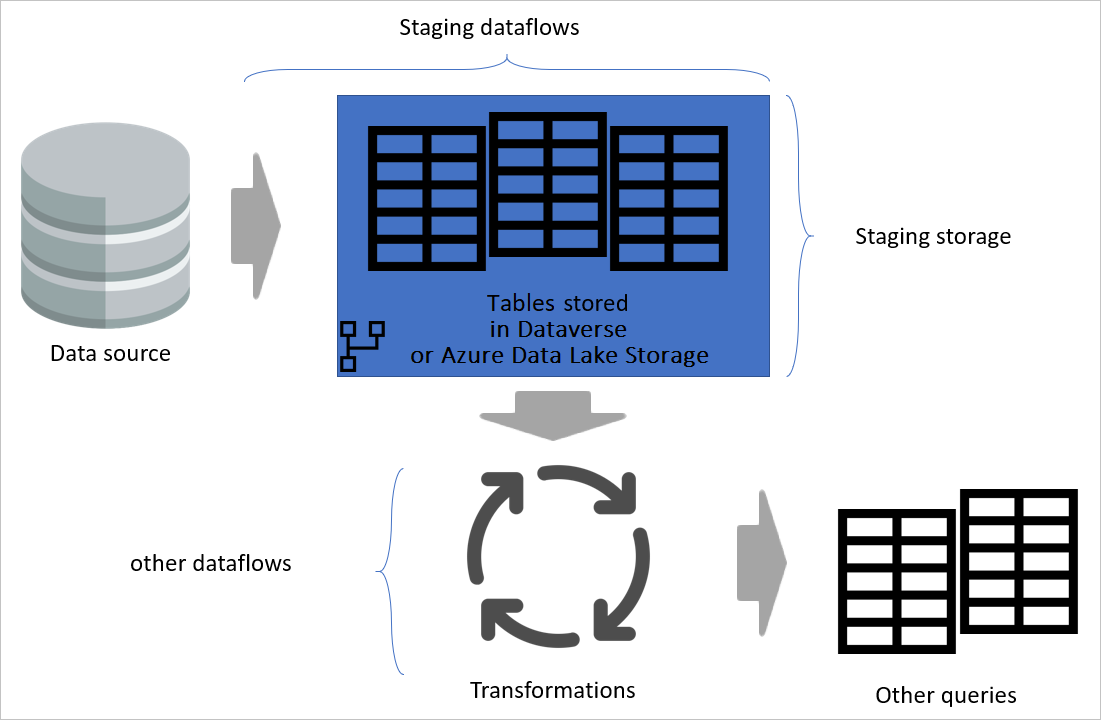
Diagrama enfatizando fluxos de dados de estágio e armazenamento de estágio. O diagrama mostra os dados que estão sendo acessados da fonte de dados pelo fluxo de dados de preparo e as tabelas que estão sendo armazenadas em Cadavers ou no Azure Data Lake Storage. Em seguida, as tabelas são mostradas sendo transformadas junto com outros fluxos de dados, que são enviados como consultas.
Fluxos de dados de transformação
Quando você separa os fluxos de dados de transformação dos fluxos de dados de preparo, a transformação é independente da origem. Essa separação ajuda se você estiver migrando o sistema de origem para um novo sistema. Tudo o que você precisa fazer nesse caso é alterar os fluxos de dados intermediários. É provável que os fluxos de dados de transformação funcionem sem nenhum problema, pois são provenientes apenas dos fluxos de dados de preparo.
Essa separação também ajuda no caso de a conexão do sistema de origem ser lenta. O fluxo de dados de transformação não precisa esperar muito tempo para obter registros provenientes de uma conexão lenta do sistema de origem. O fluxo de dados de preparo já fez essa parte e os dados estão prontos para a camada de transformação.

Arquitetura em camadas
Uma arquitetura em camadas é uma arquitetura na qual você executa ações em camadas separadas. Os fluxos de dados de preparo e transformação podem ser duas camadas de uma arquitetura de fluxo de dados de várias camadas. Tentar executar ações em camadas garante a manutenção mínima necessária. Quando você deseja alterar algo, você só precisa alterá-lo na camada em que ele está localizado. Todas as outras camadas devem continuar funcionando bem.
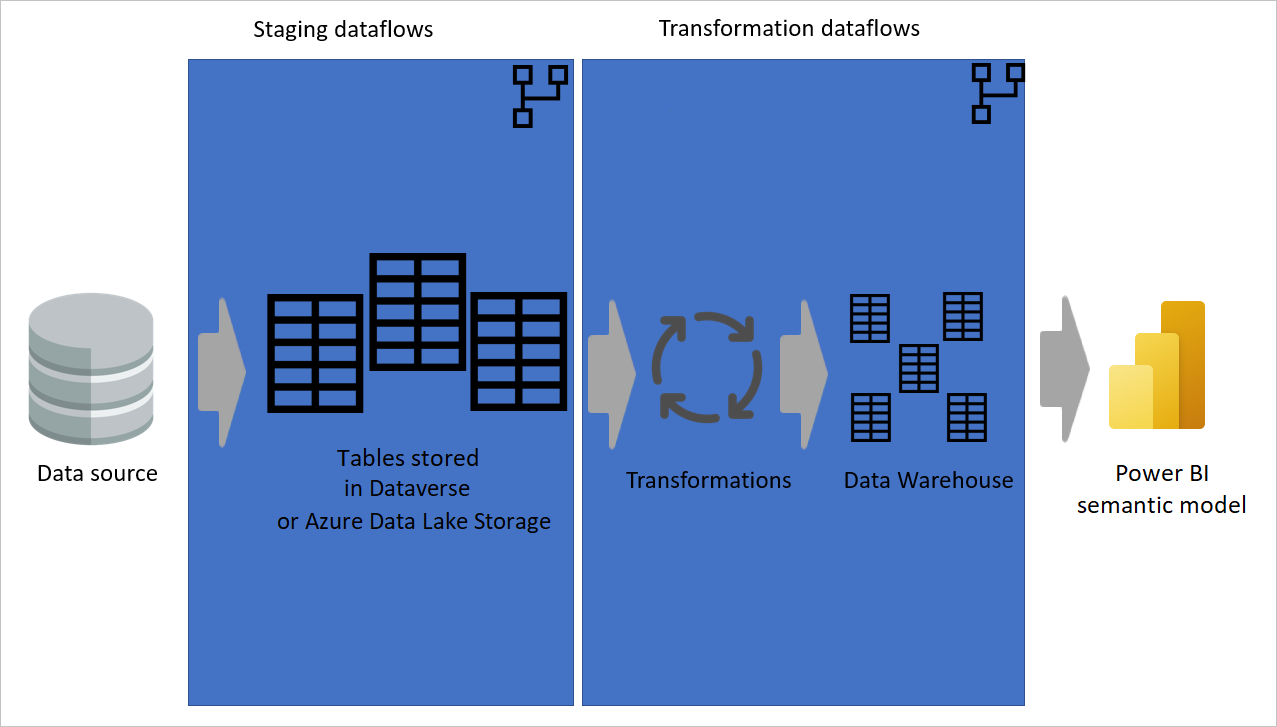
A imagem a seguir mostra uma arquitetura de várias camadas para fluxos de dados nos quais suas tabelas são usadas em modelos semânticos do Power BI.
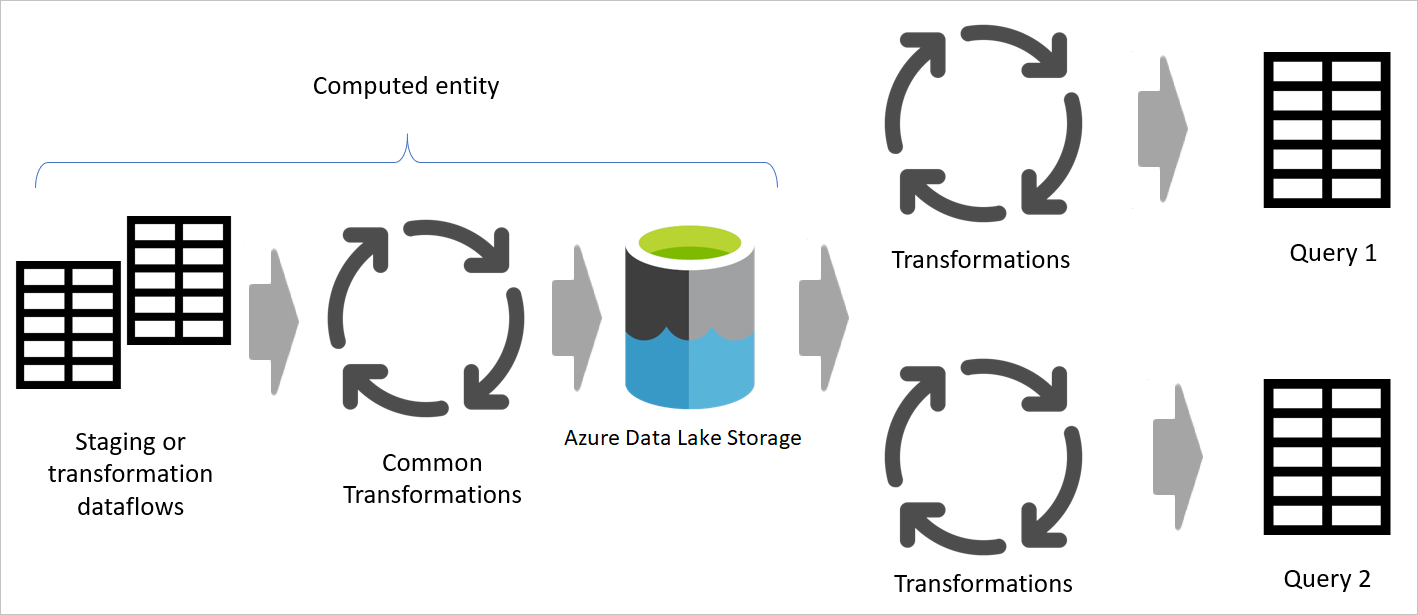
Usar uma tabela computada o máximo possível
Ao usar o resultado de um fluxo de dados em outro fluxo de dados, você está usando o conceito da tabela computada, o que significa obter dados de uma tabela "já processada e armazenada". A mesma coisa pode acontecer dentro de um fluxo de dados. Ao fazer referência a uma tabela de outra tabela, você pode usar a tabela computada. Esse método é útil quando você tem um conjunto de transformações que precisam ser feitas em várias tabelas, que são chamadas de transformações comuns.

Na imagem anterior, a tabela computada obtém os dados diretamente da origem. No entanto, na arquitetura dos fluxos de dados de preparo e transformação, é provável que as tabelas computadas sejam originadas dos fluxos de dados de preparo.
Criar um esquema de estrela
O melhor modelo dimensional é um modelo de esquema estrela que tem dimensões e tabelas de fatos projetadas de forma a minimizar a quantidade de tempo para consultar os dados do modelo. Um modelo de esquema estrela também facilita o entendimento do visualizador de dados.
Não é ideal colocar dados no mesmo layout do sistema operacional em um sistema de BI. As tabelas de dados devem ser remodeladas. Algumas das tabelas devem assumir a forma de uma tabela de dimensão, que mantém as informações descritivas. Algumas das tabelas devem assumir a forma de uma tabela de fatos, para manter os dados aggregáveis. O melhor layout para formar tabelas de fatos e tabelas de dimensão é um esquema estrela. Para obter mais informações, vá para Entender o esquema de estrela e a importância para o Power BI.

Usar um valor de chave exclusivo para dimensões
Ao criar tabelas de dimensão, verifique se você tem uma chave para cada uma delas. Essa chave garante que não haja relações de muitos para muitos, também conhecidas como "fracas", entre as dimensões. Você pode criar a chave aplicando alguma transformação para garantir que uma coluna ou uma combinação de colunas esteja retornando linhas exclusivas na dimensão. Em seguida, essa combinação de colunas pode ser marcada como uma chave na tabela no fluxo de dados.

Fazer uma atualização incremental para tabelas de fatos grandes
Tabelas de fatos são sempre as maiores tabelas no modelo dimensional. Recomendamos que você reduza o número de linhas transferidas para essas tabelas. Se você tiver uma tabela de fatos muito grande, certifique-se de usar a atualização incremental para essa tabela. Uma atualização incremental pode ser feita no modelo semântico do Power BI e também nas tabelas de fluxo de dados.
Você pode usar a atualização incremental para atualizar apenas parte dos dados, a parte que foi alterada. Há várias opções para escolher qual parte dos dados a serem atualizados e qual parte deve ser mantida. Para obter mais informações, acesse Usar a atualização incremental com fluxos de dados do Power BI.

Utilizando referência para criar tabelas de dimensões e fatos
No sistema de origem, você geralmente tem uma tabela usada para gerar tabelas de fatos e dimensões no data warehouse. Essas tabelas são boas candidatas para tabelas computadas e também fluxos de dados intermediários. A parte comum do processo, como limpeza de dados e remoção de linhas e colunas extras, pode ser feita uma vez. Usando uma referência do resultado dessas ações, você pode produzir as tabelas de dimensão e de fato. Essa abordagem usa a tabela computada para as transformações comuns.
