Modelagem de dados para o Dataverse
Quando você está armazenando ou exibindo dados com seu aplicativo, uma parte importante do design é a estrutura dos dados. É preciso considerar como os dados são usados em determinado aplicativo ou tela e como outras pessoas usam os dados. Referir-se a suas personas, tarefas, processos empresariais e metas ajuda você a definir quais dados devem ser armazenados e como estruturá-los.
Tipos de tabela
O Dataverse tem três tipos de tabela:
- Padrão: tabelas onde você pode armazenar dados e adicionar à navegação em aplicativos baseados em modelo. A maioria das tabelas que você criar será padrão. Várias tabelas padrão são criadas com base no esquema Common Data Model em um ambiente Dataverse.
- Atividade: essas tabelas são usadas para armazenar interações, como telefonemas, tarefas e compromissos. Um conjunto de tabelas de atividades fica em um banco de dados do Dataverse.
- Virtual: essas tabelas permitem criar a tabela e as colunas no Dataverse, mas usam uma fonte de dados externa para armazenar os dados. Para o usuário, os dados aparecem nos aplicativos como todos os outros dados.
Ao criar uma tabela padrão personalizada, é preciso especificar a propriedade dela:
- Usuário/Equipe: opção padrão
- Organização: usada para dados de referência

Tabelas de atividades personalizadas
As tabelas de atividades são usadas para armazenar interações. Elas têm um relacionamento com todas as tabelas que têm a opção Habilitar para atividades definida em seus metadados de tabela. As tabelas de atividades compartilham o mesmo conjunto de colunas e os mesmos privilégios de segurança. As linhas nas tabelas de atividades aparecem na linha do tempo em formulários de aplicativos baseados em modelo. Neste exemplo, uma tabela de atividades personalizada chamada Doação foi criada.
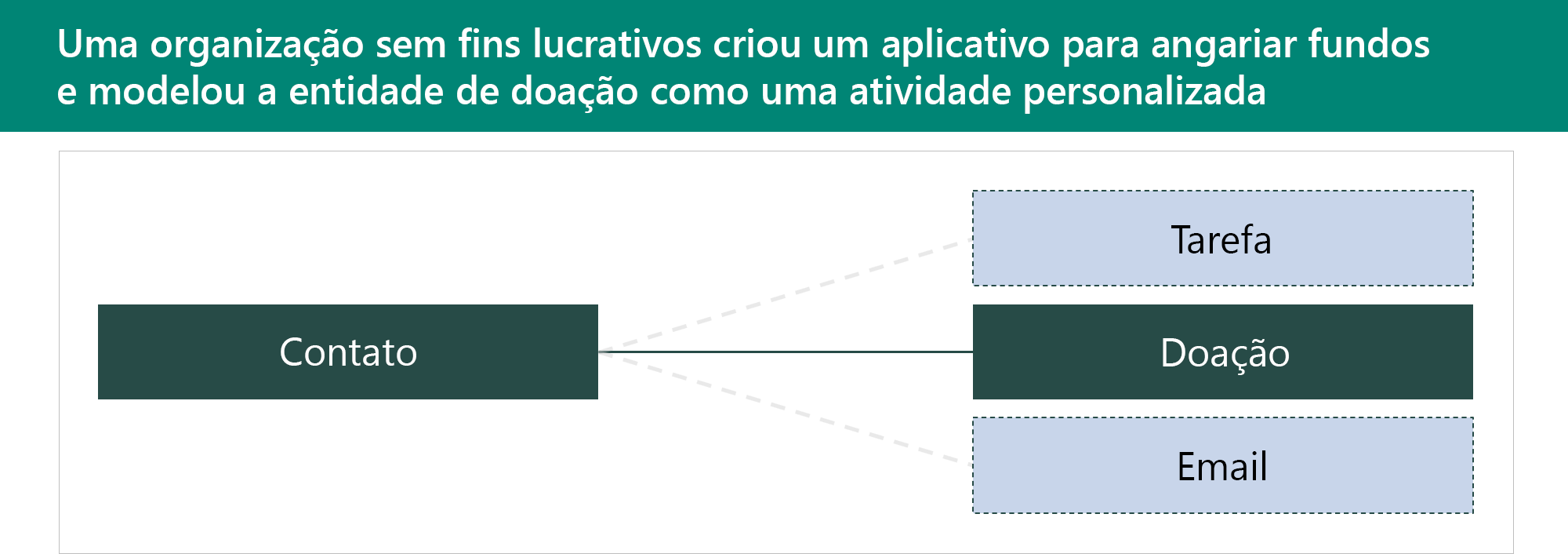
As vantagens de usar tabelas de atividades personalizadas são que elas:
- Aparecem em uma lista com outras atividades.
- Podem ser combinadas com outras atividades.
- Podem criar uma doação em qualquer tabela que ofereça suporte a atividades.
As principais desvantagens de usar tabelas de atividades personalizadas são que elas não podem:
- Configurar uma segurança diferente de qualquer outra atividade.
- Controlar quais tabelas estão relacionadas a uma doação.
Tipos de dados de coluna
Você precisa escolher o tipo de dados para as colunas de maneira sensata. Essa noção é válida principalmente para os tipos de dados numéricos porque não é possível comparar colunas numéricas com tipos diferentes, e restrições são aplicadas aos tipos de dados para colunas calculadas e cumulativas. Depois que um tipo é escolhido, ele não pode ser alterado.
| Tipo de dados | Comentários |
|---|---|
| Sim/Não | Certifique-se de que você nunca precisará de mais opções |
| Arquivo e Imagem | Permite armazenar arquivos e imagens em linha no Dataverse |
| Cliente | Pode ser contato ou conta |
| Pesquisa/Opção | Certifique-se de escolher a melhor opção |
| Data/Hora | Certifique-se de escolher o comportamento apropriado |
| Numérico | Há muitas opções disponíveis, portanto, escolha a mais adequada |
Tabela de opções ou tabela de pesquisa
As circunstâncias determinam a sua decisão entre uma tabela de pesquisa ou de opções.
Use uma tabela de opções para:
- Armazenar somente rótulo e valor como um par de chave e valor.
- Ter uma localização interna.
- Ser tratada como um componente da solução.
- Não incluir um meio interno de desativar valores.
- Ter uma experiência do usuário que funcione para cerca de 200 itens.
- Poder ser filtrada usando JavaScript.
- Ser armazenada como um número inteiro na linha.
Use uma tabela de pesquisa para:
- Poder armazenar outros dados em colunas na linha.
- Exigir que você crie uma localização.
- Ser tratada como dados de referência.
- Permitir um estado inativo.
- Ter uma experiência do usuário que seja escalonada para vários itens.
- Poder filtrar por exibições e segurança.
- Ser armazenada como uma referência de entidade.
O armazenamento de outros dados na tabela de pesquisa permite acesso quando você está executando fluxos de trabalho ou outras personalizações que fazem referência aos dados. Por exemplo, uma propriedade relacionada pode ser usada em uma condição de verificação.
Por ser um componente da solução, a tabela de opções manipula a resolução de mesclagem adicionando o prefixo do editor ao valor.
A adição de valores em uma tabela de opções exige acesso de administrador/personalizador, já os valores de pesquisa podem ser alterados por um usuário que tenha recebido permissão por meio dos direitos de acesso.
A experiência do usuário (UX) para opções é ideal para uma quantidade pequena, mas não funciona bem para conjuntos grandes. As pesquisas fornecem recursos de tipo de pesquisa que não estão disponíveis em opções.
Se você tiver várias colunas de opções que dependem umas das outras, essa tarefa só poderá ser realizada com um script baseado em formulário. As pesquisas podem ser filtradas em outras pesquisas usando a configuração.
Armazenar dados de arquivos e imagens
Há várias opções de locais para armazenar arquivos e imagens:
- Dataverse: armazene arquivos e imagens usando os tipos de dados Arquivo e Imagem.
- SharePoint: use para colaboração, mas essa opção tem um problema de segurança. A segurança dos arquivos segue as permissões do SharePoint e não é sincronizada com as permissões de linha do Dataverse.
- Armazenamento do Azure: use para arquivamento e acesso externo. Essa opção tem segurança independente, mas pode ser concedida por pequenos períodos com base em um link gerado para consumo (padrão limitado). O Armazenamento do Azure também pode processar arquivos grandes.
Características dos tipos de dados de arquivo e imagem:
- São bons para upload e referência.
- A segurança segue as permissões de registro.
- Têm limitação de tamanho.
Colunas calculadas (colunas de fórmula Fx)
As colunas calculadas permitem que cálculos simples sejam executados com base nos dados de uma linha e:
- São calculadas na recuperação de um registro.
- Têm um valor somente leitura.
- Podem incluir colunas da mesma linha e colunas em relacionamentos muitos para um.
- Podem incluir colunas cumulativas no cálculo.
- Não podem disparar um evento para fluxo de trabalho, plug-in ou Power Automate.
- São criados usando a linguagem de fórmula Fx.
Colunas cumulativas
As colunas cumulativas permitem agregações para linhas relacionadas em relacionamentos um para muitos e:
- São calculadas de forma programada (no mínimo uma hora) e podem ser atualizadas por demanda por um usuário.
- Têm um valor somente leitura.
- Podem acumular colunas calculadas.
- Podem usar hierarquia de registros relacionados.
- Podem filtrar pelas tabelas relacionadas.
- Não podem disparar um evento para fluxo de trabalho, plug-in ou Power Automate.
Você pode acumular colunas calculadas "simples", ou seja, colunas calculadas que incluem funções não determinísticas não podem ser acumuladas.
Relacionamentos
Os relacionamentos definem como as linhas estão relacionadas entre si no Dataverse. Cada tabela no Dataverse tem uma chave primária para fornecer uma referência exclusiva às linhas da tabela. No Dataverse, a chave primária é um identificador global exclusivo (GUID) gerado automaticamente pelo Dataverse quando uma linha é criada. Os relacionamentos são criados pela adição de uma referência à chave primária, que é conhecida como chave estrangeira. No Dataverse, as relacionamentos são criados usando uma coluna em uma tabela para manter o valor da chave estrangeira. Essa chave estrangeira é um ponteiro para a chave primária na outra tabela.
Dois tipos de relacionamentos são permitidos no Dataverse:
- Um para muitos (1:N)
- Muitos para muitos (N:N)
Relacionamento um para muitos
O relatório de despesas a seguir mostra um exemplo de relacionamento um para muitos (1:N).

A captura de tela anterior mostra a parte principal do relatório de despesas, que tem o nome do funcionário e os detalhes do departamento. Abaixo da parte principal estão várias linhas de descrições para cada item comprado. Neste exemplo, essas descrições são chamadas de itens de linha. Os itens de linha têm uma estrutura diferente da parte principal do relatório de despesas. Portanto, cada relatório de despesas tem vários itens de linha.
O relacionamento entre o relatório de despesas e o item de linha é um exemplo de relacionamento um para muitos (1:N). A parte principal do relatório de despesas está vinculada a vários itens de linha. Você também pode ver o relacionamento da perspectiva dos itens de linha: cada item de linha só pode ser vinculado a um relatório de despesas, que é um relacionamento muitos para um (N:1).
Relacionamento muitos para muitos
A estrutura de dados múltiplos para múltiplos é um tipo especial usado para casos em que é possível associar vários registros a vários conjuntos de outros registros. Um bom exemplo de estrutura de dados múltiplos para múltiplos é a sua rede de parceiros comerciais. Você trabalha com vários parceiros comerciais (clientes e fornecedores), e eles também trabalham com vários colegas seus.

As seções a seguir apresentam exemplos de tipos diferentes de estruturas de dados múltiplos para múltiplos.
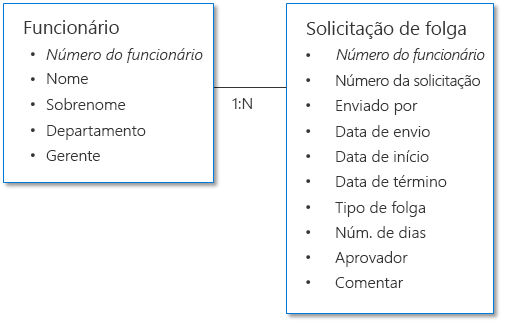
Exemplo 1: solicitação de aprovação de folga
O exemplo a seguir mostra dois conjuntos de dados: um que representa o funcionário e outro que representa a solicitação de folga. Como cada funcionário envia várias solicitações, o relacionamento neste cenário é de um para muitos, em que "um" é o funcionário e "muitos" são as solicitações. Os dados do funcionário e os dados da solicitação de folga estão relacionados entre si, tendo o número do funcionário como a coluna comum (também conhecida como chave).
Exemplo 2: aprovação da compra
Neste exemplo, a estrutura de dados parece sofisticada, mas é semelhante ao exemplo do relatório de despesas que foi abordado no início deste artigo. Cada fornecedor está associado a várias ordens de compra. Cada funcionário é responsável por várias ordens de compra. Portanto, ambos os conjuntos de dados têm uma estrutura de dados de um para muitos.
Como os funcionários nem sempre podem usar o mesmo fornecedor, os fornecedores são usados por vários funcionários e cada funcionário trabalha com vários fornecedores. Portanto, o relacionamento entre funcionários e fornecedores é de muitos para muitos.

Exemplo 3: relatório de despesas
O exemplo a seguir mostra um ERD (diagrama de relacionamento entre entidades) que contém várias tabelas para uma solução de relatório de despesas.

Exemplo 4: rastrear quais são os dois benefícios que o VIP selecionou
Este exemplo apresenta dois VIPs: John e Mary. John escolheu os benefícios Wi-Fi e Lavanderia, e Mary escolheu os benefícios Wi-Fi e Minibar. Você pode criar um modelo deste cenário de maneiras diferentes. A primeira maneira é como um relacionamento 1:N.
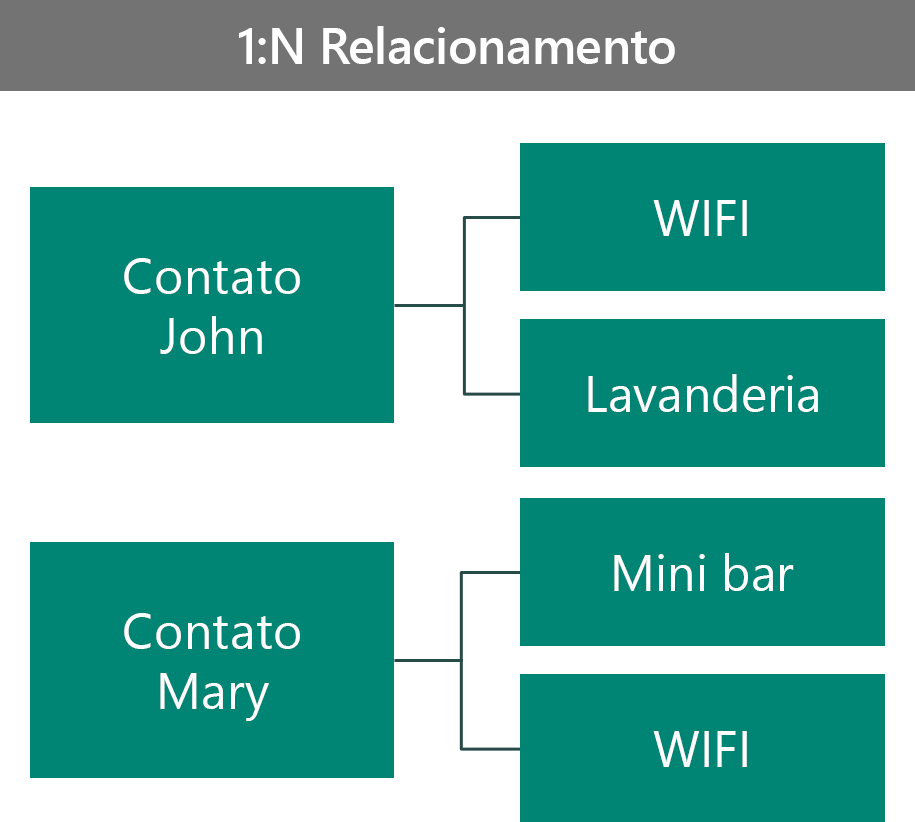
Nesta configuração:
- O registro de benefícios é exclusivo do contato.
- Não é permitido ver todos os contatos que escolhem um determinado benefício.
- Você pode definir a segurança do registro de benefícios com base no proprietário do contato.
- Você pode armazenar mais dados sobre o registro de benefícios específico do contato.
- O relacionamento precede o benefício; caso contrário, os registros de benefícios seriam órfãos.
A segunda maneira é como um relacionamento N:N.
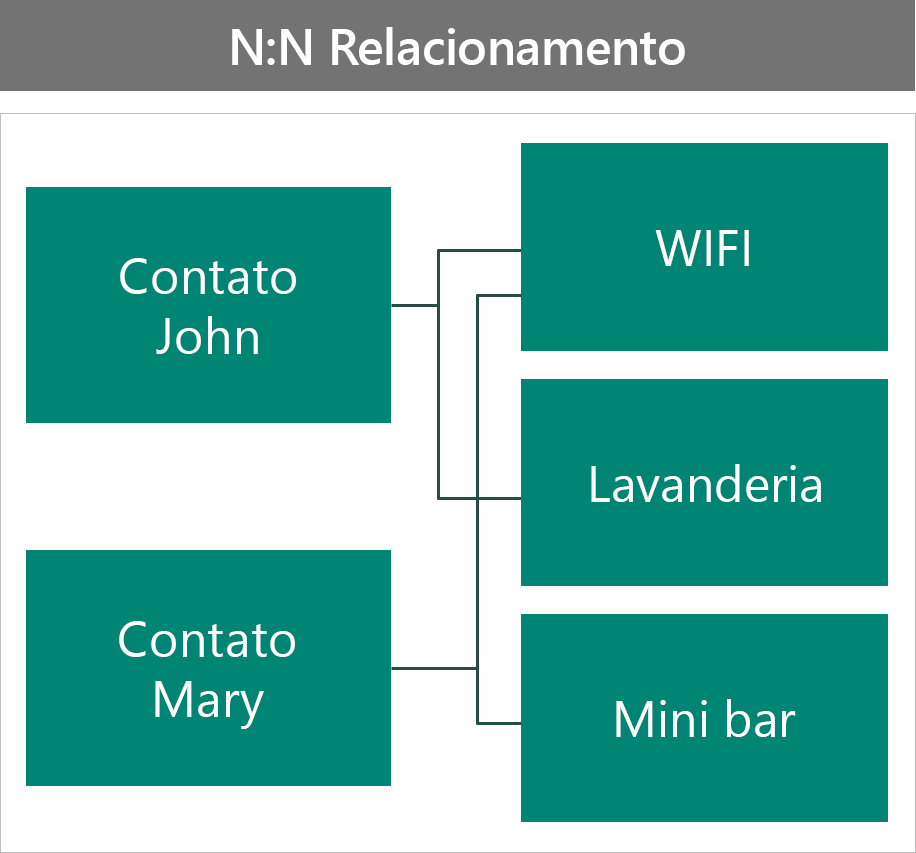
Nesta configuração:
- Os registros associados do benefício mostram todos os contatos que escolhem esse benefício.
- A segurança do benefício é compartilhada com todos os contatos e, portanto, não será possível personalizar cada contato.
- Os atributos do benefício são compartilhados com todos os contatos e, portanto, você não terá dados específicos do contato.
- Você deve usar um relacionamento de referência; caso contrário, removerá o benefício dos outros contatos.
Nenhuma das configurações é a ideal.
O próximo exemplo mostra a criação de uma tabela personalizada (interseção) para armazenar os benefícios do VIP.
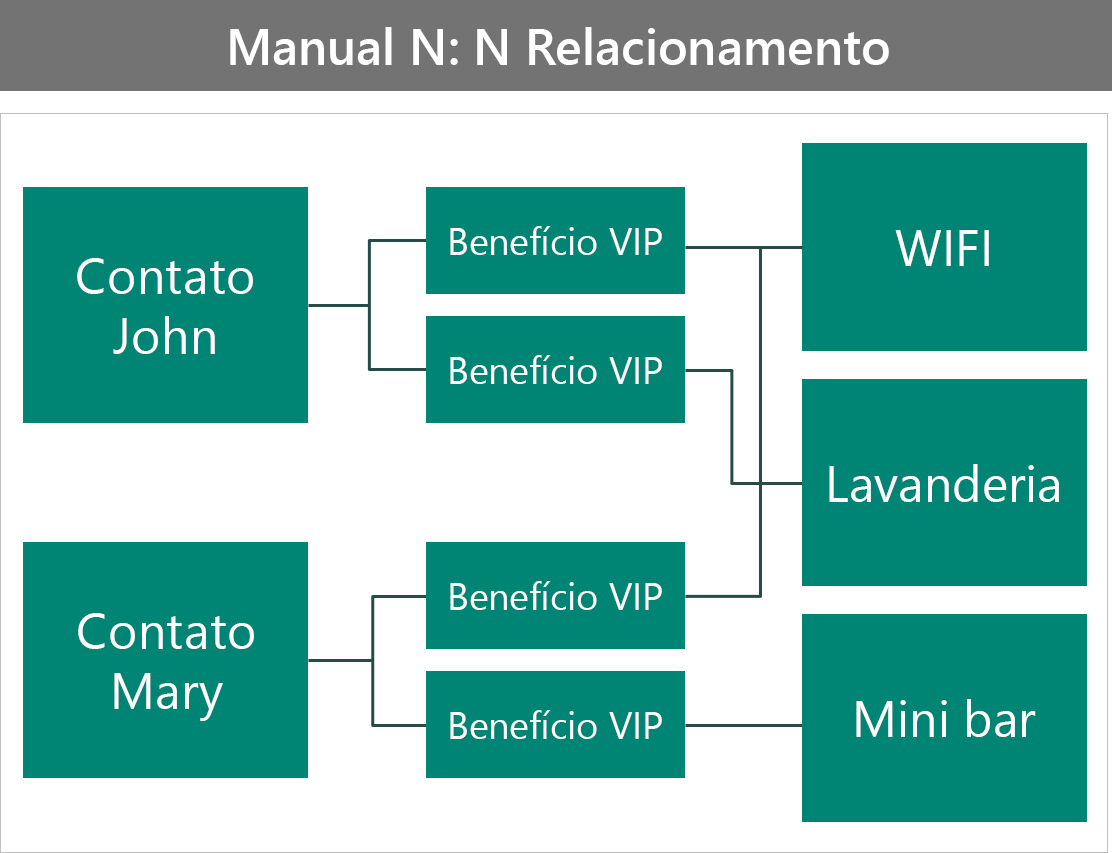
Esta configuração:
- Adiciona a capacidade de armazenar mais dados na tabela de benefícios específica desse contato.
- Requer mais trabalho para que o usuário se conecte aos registros. Agora, ele precisa criar a linha de interseção manualmente.
- Protege os benefícios individualmente.
- Dificulta a consulta, pois você não pode acessar diretamente os atributos na tabela de benefícios.
O exemplo a seguir mostra o uso de colunas na tabela de contatos.

Esta configuração:
- Funciona bem para benefícios principais e secundários, mas não pode ser dimensionada para o acompanhamento de muitos benefícios.
- Simplifica a consulta e torna o autoatendimento do Power BI mais fácil para os usuários.
- Segue a mesma segurança do registro de contato.
- Requer a criação de uma consulta que verifique os benefícios principais e secundários, se você estiver consultando todos os usuários que escolheram um benefício principal.
Essa configuração é um bom exemplo de quando o benefício deve ser registrado para alguma finalidade de conformidade/estatística, mas sem impacto nos negócios ou no processamento.
Comportamentos de relacionamento
Os comportamentos de relacionamento controlam como certas ações se propagam para as linhas que estão relacionadas à linha da tabela principal por meio do relacionamento 1:N. Os comportamentos mantêm a integridade referencial e podem impedir que registros órfãos sejam deixados para trás.
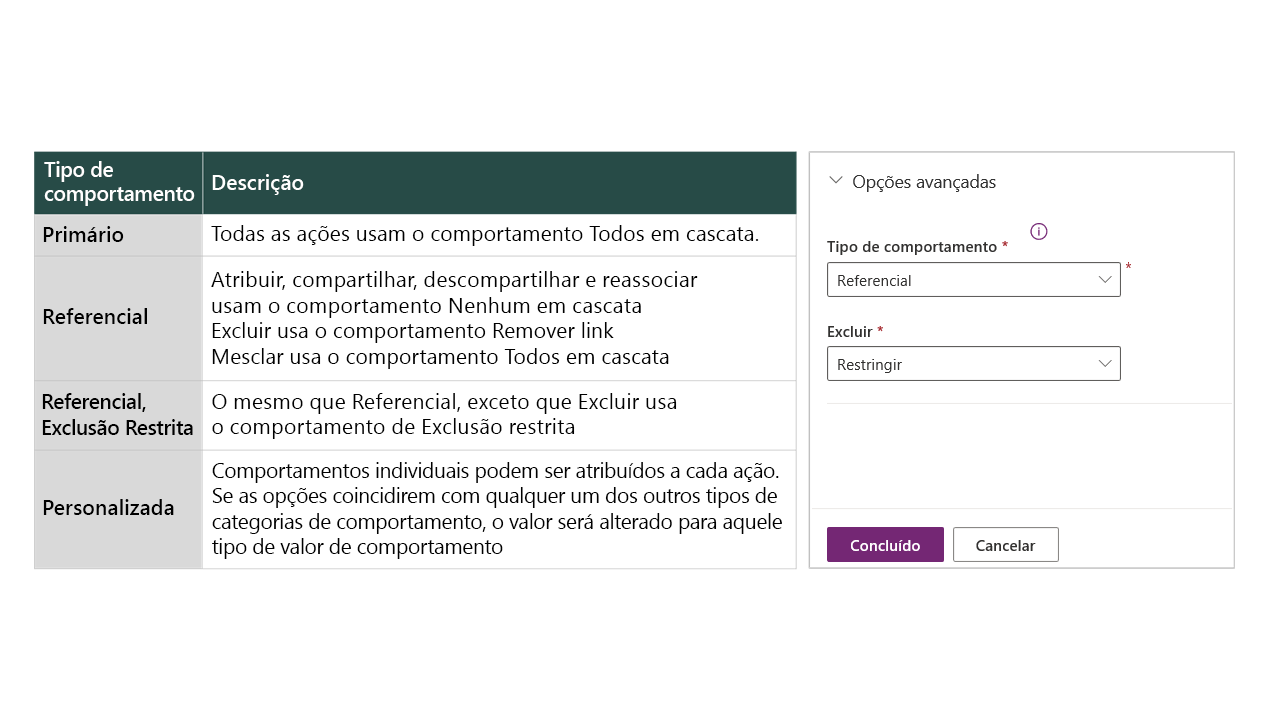
Importante
A definição dos comportamentos de relacionamento é importante porque a propagação de registros atribuídos pode fazer com que os registros relacionados sejam atribuídos. Na dúvida, defina o comportamento como Referencial e Restrito.
Chaves alternativas
As chaves alternativas são usadas em integrações para reduzir a necessidade de executar uma consulta para localizar um registro. Ao usar uma chave alternativa, você pode atualizar uma linha sem saber o GUID.
Chaves alternativas:
- São excelentes para uso em recuperações e atualizações.
- Podem conter números decimais, inteiros, campos de texto, datas e campos de pesquisa.
- Podem ter até cinco chaves alternativas para cada tabela.
- Criam um índice exclusivo anulável em segundo plano para reforçar a exclusividade da chave.
Quando uma chave é criada, o sistema valida que essa chave é compatível com a plataforma.
Práticas recomendadas para diagramas
Ao criar ERDs para o Dataverse, você deve:
- Evitar a duplicação de dados. Os dados devem residir em um único local. Em vez de duplicar os mesmos dados entre várias tabelas, use funcionalidades como formulários de visualização rápida e dados de tabelas relacionadas em exibições.
- Usar os relacionamentos de ERD para revisar e identificar possíveis comportamentos em cascata que podem afetar a lógica de negócios. Por exemplo, com os relacionamentos parentais, permissões como Atribuir, Compartilhar, Descompartilhar, Reassociar, Excluir e Mesclar são automaticamente atribuídas aos registros relacionados quando um registro pai é atualizado.