Definir o problema
Começando com a primeira etapa, você deseja definir o problema que o modelo deve resolver, compreendendo:
- Qual deve ser a saída do modelo.
- Qual tipo de tarefa de aprendizado de máquina você usa.
- Quais critérios tornam um modelo bem-sucedido.
Dependendo dos dados que você tem e da saída esperada do modelo, você pode identificar a tarefa de aprendizado de máquina. A tarefa determina quais tipos de algoritmos você pode usar para treinar o modelo.
Algumas tarefas comuns de aprendizado de máquina são:

- Classificação: prever um valor categórico.
- Regressão: prever um valor numérico.
- Previsão de série temporal: prever valores numéricos futuros com base em dados com carimbo de data/hora.
- Pesquisa visual computacional: classificar imagens ou detectar objetos em imagens.
- NLP (processamento de linguagem natural): extraia insights do texto.
Para treinar um modelo, você tem um conjunto de algoritmos que pode usar, dependendo da tarefa que deseja executar. Para avaliar o modelo, você pode calcular métricas de desempenho, tais como a precisão. As métricas disponíveis também dependem da tarefa que seu modelo precisa executar e ajudam você a decidir se um modelo é bem-sucedido em sua tarefa.
Explore um exemplo
Considere um cenário em que você deseja determinar se os pacientes têm diabetes. O problema que você está tentando resolver e o tipo de dados disponíveis determinam a tarefa de aprendizado de máquina que você escolhe. Neste caso, os dados disponíveis são outros pontos de dados de integridade dos pacientes. Podemos representar a saída desejada como informações categóricas que indicam se o paciente tem ou não diabetes. Assim, a tarefa de aprendizado de máquina é classificação.
Compreender todo o processo antes de começar oferece a você a oportunidade de mapear as decisões que precisa tomar para projetar uma solução de aprendizado de máquina bem-sucedida. A seguir, um diagrama mostra uma maneira de abordar o problema de identificação de diabetes em um paciente. No diagrama, os dados são preparados, divididos e treinados usando algoritmos específicos. Depois, o modelo é avaliado quanto à qualidade.
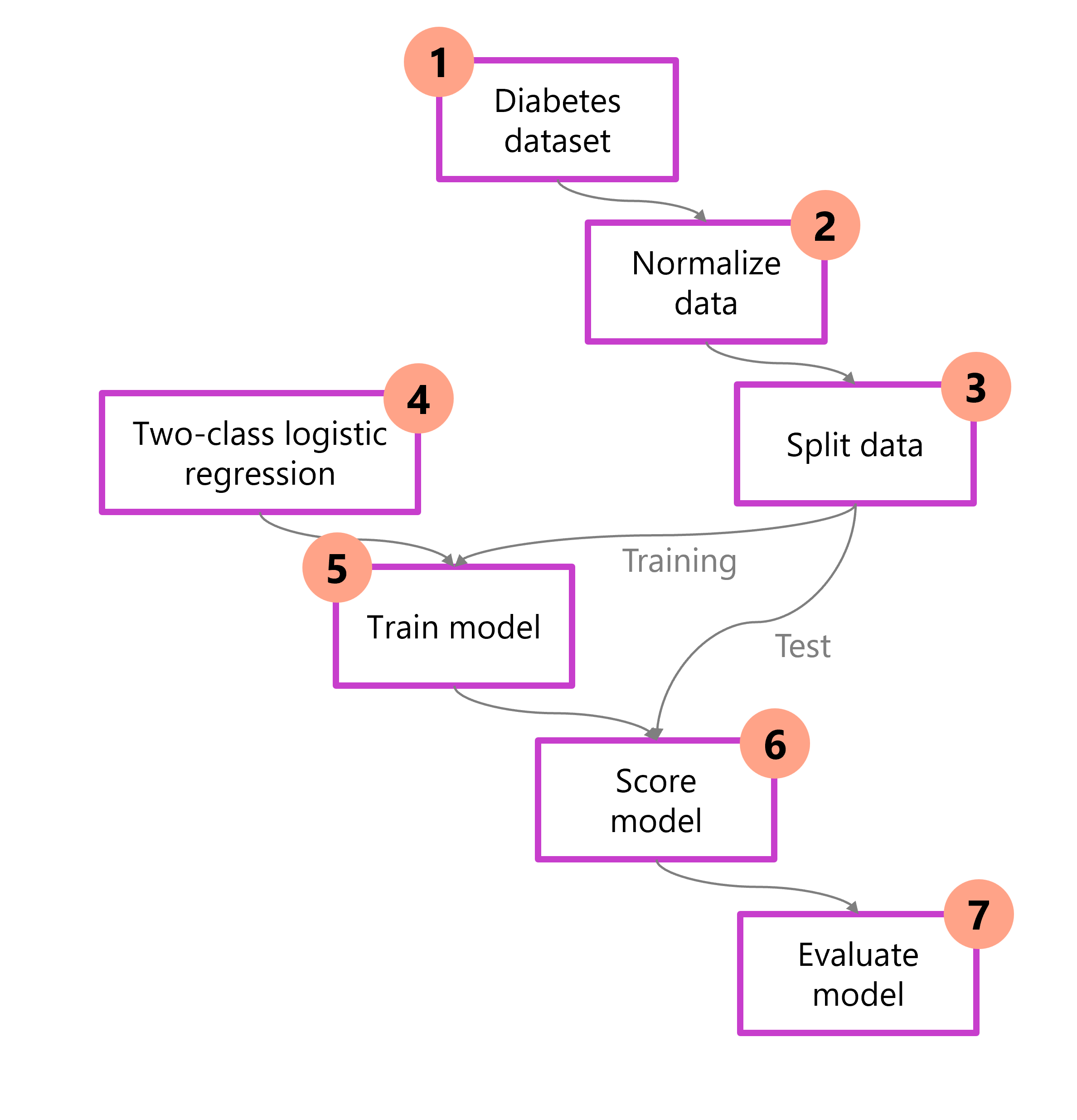
- Carregar dados: Importar e inspecionar o conjunto de dados.
- Pré-processar dados: Normalizar e tirar para garantir a consistência.
- Dividir dados: Separar em conjuntos de treinamento e teste.
- Escolher modelo: Selecionar e configurar um algoritmo.
- Treinar modelo: Aprender padrões dos dados de treinamento.
- Pontuar modelo: Gerar previsões sobre os dados de teste.
- Avaliar: Calcular métricas de desempenho.
O treinamento de um modelo de aprendizado de máquina é geralmente um processo iterativo, em que você passa por cada uma dessas etapas várias vezes para encontrar o modelo de melhor desempenho. Em seguida, vamos examinar o processo de preparação de dados para desenvolver uma solução de machine learning.