Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Painel do WinML é uma ferramenta para exibir, editar, converter e validar modelos de machine learning para o mecanismo de inferência do Windows ML. O mecanismo é integrado ao Windows 10 e avalia modelos treinados localmente em dispositivos Windows usando otimizações de hardware para CPU e GPU para habilitar inferências de alto desempenho.
Obtendo a ferramenta
Você pode baixar o Painel do WinML aqui ou criar o aplicativo na origem seguindo as instruções abaixo.
Compilar a partir da origem
Ao compilar o aplicativo a partir do código-fonte, você precisará do seguinte:
| Requisitos | Versão | Baixar | Comando a verificar |
|---|---|---|---|
| Python3 | 3.4+ | aqui | python --version |
| Fio | mais recente | aqui | yarn --version |
| Node.js | mais recente | aqui | node --version |
| Git | mais recente | aqui | git --version |
| MSBuild | mais recente | aqui | msbuild -version |
| Nuget | mais recente | aqui | nuget help |
Todos os seis pré-requisitos devem ser adicionados ao Caminho do Ambiente. Observe que o MSBuild e o Nuget serão incluídos em uma instalação do Visual Studio 2017.
Etapas para compilar e executar
Para executar o Painel do WinML, siga estas etapas:
- Na linha de comando, clone o repositório:
git clone https://github.com/Microsoft/Windows-Machine-Learning - No repositório, insira o seguinte para acessar a pasta certa:
cd Tools/WinMLDashboard - Execute
git submodule update --init --recursivepara atualizar o Netron. - Execute o yarn para baixar as dependências.
- Em seguida, execute
yarn electron-prodpara criar e iniciar o aplicativo da área de trabalho, que iniciará o Painel.
Todos os comandos disponíveis do Painel podem ser vistos em package.json.
Exibindo e editando modelos
O Painel usa o Netron para exibir modelos de machine learning. Embora o WinML use o formato ONNX, o visualizador do Netron dá suporte à exibição de vários formatos de estrutura diferentes.
Muitas vezes, um desenvolvedor pode precisar atualizar determinados metadados de modelo ou modificar nós de entrada e saída do modelo. Essa ferramenta dá suporte à modificação de propriedades de modelo, metadados e nós de entrada/saída de um modelo ONNX.
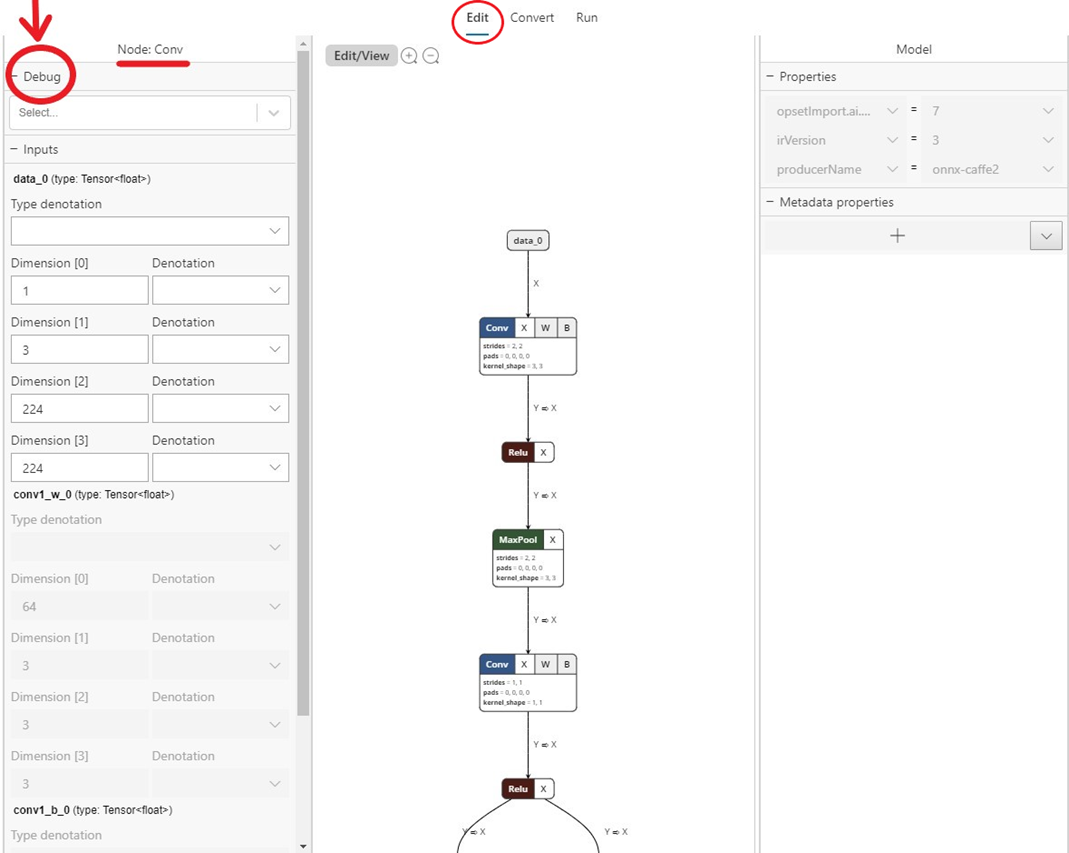
Selecionar a guia Edit (parte superior central, conforme mostrado na imagem abaixo) leva você ao painel de visualização e edição. O painel esquerdo no painel permite editar nós de entrada e saída do modelo e o painel direito permite a edição de propriedades do Modelo. A parte central mostra o grafo. Neste momento, o suporte à edição está limitado a nós de entrada/saída do modelo (e não a nós internos), bem como às propriedades e metadados do modelo.
O Edit/View botão alterna do modo Editar para o modo somente exibição e vice-versa.
O Modo somente exibição não permite a edição e habilita os recursos nativos do visualizador do Netron, como a capacidade de ver informações detalhadas de cada nó.

Convertendo modelos
Atualmente, há várias estruturas diferentes disponíveis para treinamento e avaliação de modelos de machine learning, o que dificulta que os desenvolvedores de aplicativos insiram modelos em seu produto. O Windows ML usa o formato de modelo de machine learning ONNX que permite a conversão de um formato de estrutura para outro, e esse Painel facilita a conversão de modelos de estruturas diferentes para ONNX.
A guia Converter dá suporte à conversão em ONNX das seguintes estruturas de origem:
- ML do núcleo da Apple
- TensorFlow (subconjunto de modelos conversíveis para ONNX)
- Keras
- Scikit-learn (subconjunto de modelos conversíveis para ONNX)
- Impulso de Peso
- LibSVM
A ferramenta também permite a validação do modelo convertido avaliando o modelo com o mecanismo de inferência interno do Windows ML usando dados sintéticos (padrão) ou dados de entrada reais em CPU ou GPU.

Validando modelos
Depois de ter um modelo ONNX, você poderá validar se a conversão ocorreu com êxito e se o modelo pode ser avaliado no mecanismo de inferência do Windows ML. Isso é feito usando a aba Run (veja o recorte abaixo).
Você pode escolher várias opções, como CPU (padrão) vs GPU, entrada real versus entrada sintética (padrão) etc. O resultado da avaliação do modelo aparece na janela do console na parte inferior.
Observe que o recurso de validação de modelo só está disponível no Windows 10 October 2018 Update ou na versão mais recente do Windows 10, pois a ferramenta depende do mecanismo de inferência interno do Windows ML.

Inferência de depuração
Você pode utilizar o recurso de depuração do WinML Dashboard para obter informações sobre como os dados brutos passam pelos operadores em seu modelo. Você também pode optar por visualizar esses dados para inferência de pesquisa visual computacional.
Para depurar seu modelo, siga estas etapas:
- Navegue até a
Editguia e selecione o operador para o qual você deseja capturar dados intermediários. No painel esquerdo, haverá umDebugmenu em que você pode selecionar os formatos de dados intermediários que deseja capturar. No momento, as opções são texto e PNG. O texto produzirá um arquivo de texto que contém as dimensões, o tipo de dados e os dados de tensor brutos produzidos por esse operador. O PNG formatará esses dados em um arquivo de imagem que pode ser útil para aplicativos de pesquisa visual computacional.
- Navegue até a
Runguia e selecione o modelo que você deseja depurar. - Para o campo
Capture, selecioneDebugna lista suspensa. - Selecione uma imagem de entrada ou csv para fornecer ao seu modelo na execução. É importante observar que isso é necessário ao capturar dados de debug.
- Selecione uma pasta de saída para exportar dados de depuração.
- Selecione
Run. Quando a execução for concluída, navegue até a pasta selecionada para exibir a captura da depuração.

Você também pode abrir o modo de depuração no aplicativo Electron usando uma das seguintes opções:
- Execute-o com
flag --dev-tools - Ou selecione
View -> Toggle Dev Toolsno menu do aplicativo - Ou pressione
Ctrl + Shift + I.