Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
No estágio anterior deste tutorial, instalamos o PyTorch em seu computador. Agora, vamos usá-lo para configurar o código com os dados que vamos usar para criar o modelo.
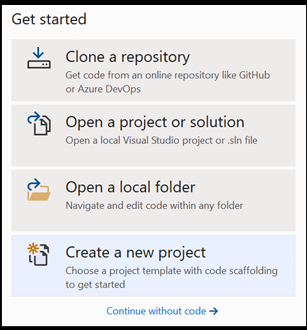
Abrir um novo projeto no Visual Studio.
- Abra o Visual Studio e escolha
create a new project.
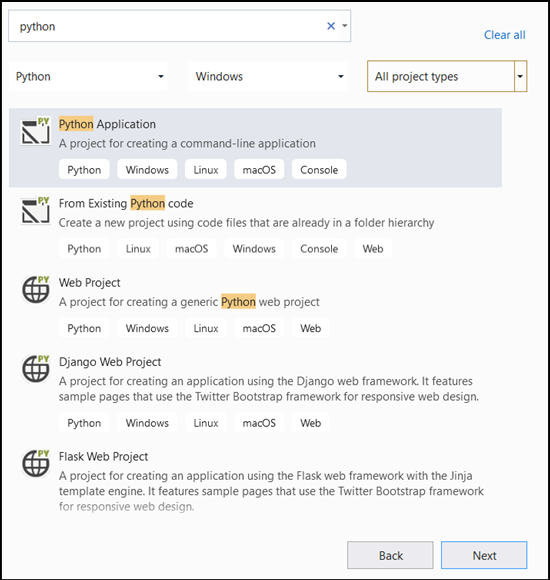
- Na barra de pesquisa, digite
Pythone selecionePython Applicationcomo o modelo de projeto.
- Na janela de configuração:
- Nomeie o projeto. Aqui, chamamos de DataClassifier.
- Escolha o local do projeto.
- Se você está usando o VS2019, verifique se
Create directory for solutionestá marcado. - Se estiver usando o VS2017, verifique se a opção
Place solution and project in the same directoryestá desmarcada.
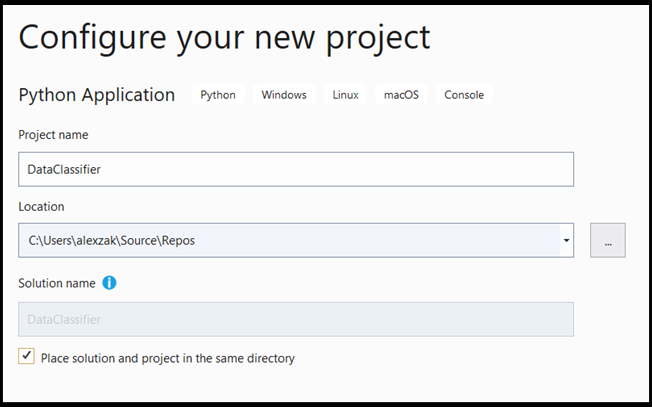
Pressione create para criar o projeto.
Criar um interpretador do Python
Você precisa definir um novo interpretador do Python. Isso deve incluir o pacote PyTorch instalado recentemente.
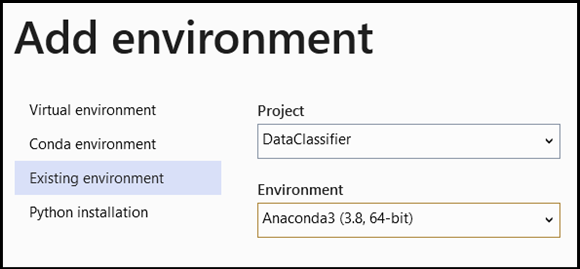
- Navegue até a seleção do interpretador e selecione
Add Environment:

- Na janela
Add Environment, selecioneExisting environmente escolhaAnaconda3 (3.6, 64-bit). Isso inclui o pacote PyTorch.
Para testar o novo interpretador do Python e o pacote PyTorch, insira o seguinte código no arquivo DataClassifier.py:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
A saída deve ser um tensor 5x3 aleatório semelhante ao apresentado abaixo.
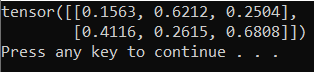
Observação
Quer aprender mais? Visite o site oficial do PyTorch.
Compreendendo os dados
O modelo será treinado no conjunto de dados de flor de íris de Fisher. Este famoso conjunto de dados inclui 50 registros para cada uma das três espécies de Íris: Iris setosa, Iris virginica e Iris versicolor.
Várias versões do conjunto de dados foram publicadas. Você pode encontrar o conjunto de dados Iris no Repositório de Machine Learning da UCI, importar o conjunto de dados diretamente da biblioteca do Python Scikit-learn ou usar qualquer outra versão publicada anteriormente. Para saber mais sobre o conjunto de dados Íris, visite a página dele na Wikipédia.
Neste tutorial, para mostrar como treinar o modelo com o tipo de entrada tabular, você usará o conjunto de dados Iris exportado para o arquivo do Excel.
Cada linha da tabela do Excel mostrará quatro recursos de Íris: comprimento do sepal em cm, largura do sepal em cm, comprimento da pétala em cm e largura da pétala em cm. Esses recursos servirão como sua entrada. A última coluna inclui o tipo Iris relacionado a esses parâmetros e representará a saída de regressão. Ao todo, o conjunto de dados inclui 150 entradas de quatro características, cada uma associada ao tipo de íris relevante.
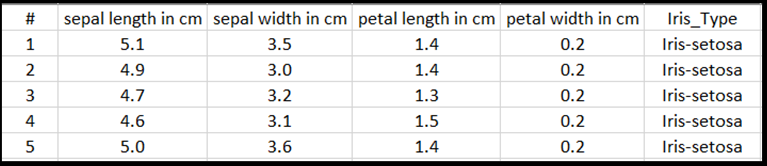
A análise de regressão analisa a relação entre variáveis de entrada e o resultado. Com base na entrada, o modelo aprenderá a prever o tipo correto de saída: um dos três tipos Iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Importante
Se você decidir usar qualquer outro conjunto de dados para criar seu próprio modelo, precisará especificar as variáveis de entrada e a saída do modelo de acordo com seu cenário.
Carregue o conjunto de dados.
Baixe o conjunto de dados iris no formato do Excel. Você pode encontrá-lo aqui.
DataClassifier.pyNo arquivo na pasta Arquivos do Gerenciador de Soluções, adicione a seguinte instrução de importação para obter acesso a todos os pacotes de que precisaremos.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Como você pode ver, você usará o pacote pandas (análise de dados do Python) para carregar e manipular dados e pacote torch.nn que contém módulos e classes extensíveis para a criação de redes neurais.
- Carregue os dados na memória e verifique o número de classes. Esperamos ver 50 itens de cada espécie de íris. Especifique o local do conjunto de dados em seu computador.
Adicione o seguinte código ao arquivo DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Quando executamos esse código, a saída esperada é a seguinte:

Para poder usar o conjunto de dados e treinar o modelo, precisamos definir entrada e saída. A entrada é de 150 linhas de recursos; a saída é a coluna "Espécie de íris". A rede neural que usaremos requer variáveis numéricas, portanto, você converterá a variável de saída em um formato numérico.
- Crie uma nova coluna no conjunto de dados que representará a saída em um formato numérico e definirá uma entrada e uma saída de regressão.
Adicione o seguinte código ao arquivo DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
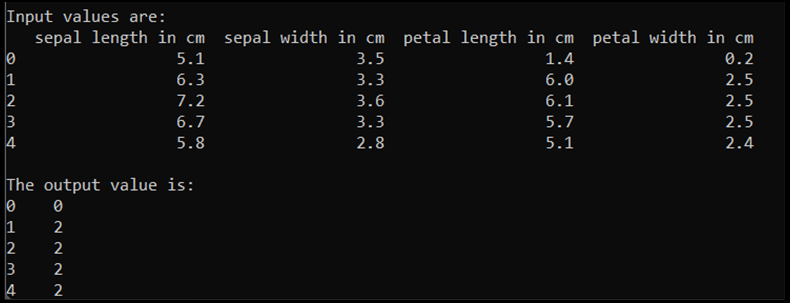
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Quando executamos esse código, a saída esperada é a seguinte:
Para treinar o modelo, precisamos converter a entrada e a saída do modelo no formato Tensor:
- Converter em Tensor:
Adicione o seguinte código ao arquivo DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Se executarmos o código, a saída esperada mostrará o formato de entrada e saída, da seguinte maneira:

Há 150 valores de entrada. Cerca de 60% serão os dados de treinamento do modelo. Você manterá 20% para validação e 30% para um teste.
Neste tutorial, o tamanho do lote de um conjunto de dados de treinamento é definido como 10. Há 95 itens no conjunto de treinamento, o que significa que, em média, há nove lotes completos para iterar por meio do conjunto de treinamento uma vez (uma época). Você manterá o tamanho do lote dos conjuntos de validação e teste como 1.
- Divida os dados para treinar, validar e testar conjuntos:
Adicione o seguinte código ao arquivo DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Próximas etapas
Com os dados prontos para serem usados, é hora de treinar nosso modelo PyTorch