Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
O Databricks Feature Serving disponibiliza dados na plataforma Databricks para modelos ou aplicativos implantados fora do Azure Databricks. Os pontos de extremidade do serviço de funcionalidades são dimensionados automaticamente para se ajustar ao tráfego em tempo real e fornecer um serviço de alta disponibilidade e baixa latência para disponibilizar funcionalidades. Esta página descreve como configurar e usar o Feature Serving. Para obter um tutorial passo a passo, consulte Exemplo: implantar e consultar um endpoint de serviço de funcionalidades.
Quando você usa o Mosaic AI Model Serving para servir um modelo que foi criado usando recursos do Databricks, o modelo automaticamente procura e transforma recursos para solicitações de inferência. Com o Databricks Feature Serving, você pode fornecer dados estruturados para recuperar aplicativos de geração aumentada (RAG), bem como recursos necessários para outros aplicativos, como modelos servidos fora do Databricks ou qualquer outro aplicativo que exija recursos baseados em dados no Unity Catalog.

Por que usar o Feature Serving?
O Databricks Feature Serving fornece uma interface única que atende recursos pré-materializados e sob demanda. Inclui também os seguintes benefícios:
- Simplicidade. Databricks trata da infraestrutura. Com uma única chamada de API, o Databricks cria um ambiente de serviço pronto para produção.
- Alta disponibilidade e escalabilidade. Os endpoints de distribuição de funcionalidades aumentam e diminuem automaticamente para se adaptar ao volume de pedidos de serviço.
- Segurança. Os pontos de extremidade são implantados numa fronteira de rede segura e usam computação dedicada que termina quando o ponto de extremidade é excluído ou reduzido a zero.
Requerimentos
- Databricks Runtime 14.2 ML ou superior.
- Para usar a API do Python, o Feature Serving requer
databricks-feature-engineeringa versão 0.1.2 ou superior, que é incorporada ao Databricks Runtime 14.2 ML. Para versões anteriores do Databricks Runtime ML, instale manualmente a versão necessária usando%pip install databricks-feature-engineering>=0.1.2. Se você estiver usando um bloco de anotações Databricks, você deve reiniciar o kernel Python executando este comando em uma nova célula:dbutils.library.restartPython(). - Para usar o SDK do Databricks, o Feature Serving requer
databricks-sdka versão 0.18.0 ou superior. Para instalar manualmente a versão necessária, use%pip install databricks-sdk>=0.18.0. Se você estiver usando um bloco de anotações Databricks, você deve reiniciar o kernel Python executando este comando em uma nova célula:dbutils.library.restartPython().
O Databricks Feature Serving fornece uma interface do utilizador e várias opções programáticas para criar, atualizar, consultar e excluir endpoints. Este artigo inclui instruções para cada uma das seguintes opções:
- Interface do usuário do Databricks
- API REST
- API Python
- Databricks SDK
Para usar a API REST ou o SDK de implantações MLflow, você deve ter um token de API Databricks.
Importante
Como prática recomendada de segurança para cenários de produção, o Databricks recomenda que você use tokens OAuth máquina a máquina para autenticação durante a produção.
Para teste e desenvolvimento, o Databricks recomenda o uso de um token de acesso pessoal pertencente a entidades de serviço em vez de usuários do espaço de trabalho. Para criar tokens para entidades de serviço, consulte Gerenciar tokens para uma entidade de serviço.
Autenticação para servir funcionalidades
Para obter informações sobre autenticação, consulte Autorizar acesso aos recursos do Azure Databricks.
Criar um FeatureSpec
Um FeatureSpec é um conjunto de recursos e funções definido pelo usuário. Você pode combinar recursos e funções em um FeatureSpec.
FeatureSpecs são armazenados e gerenciados pelo Unity Catalog e aparecem no Catalog Explorer.
As tabelas especificadas em um FeatureSpec devem ser publicadas em uma loja de recursos online ou em uma loja online de terceiros. Consulte Databricks Online Feature Stores.
Você deve usar o pacote databricks-feature-engineering para criar um FeatureSpec.
Primeiro, defina a função:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
Então você pode usar a função em um FeatureSpec:
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Especificar valores padrão
Para especificar valores padrão para recursos, use o default_values parâmetro no FeatureLookup. Veja o seguinte exemplo:
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
Se as colunas de recursos forem renomeadas usando o rename_outputs parâmetro, default_values deverão usar os nomes de recursos renomeados.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Criar um ponto final
O FeatureSpec define o ponto de extremidade. Para obter mais informações, consulte Criar endpoints de serviço de modelo personalizado, a documentação da API Python ou a documentação do SDK do Databricks para obter detalhes.
Nota
Para cargas de trabalho sensíveis à latência ou que exigem altas taxas de consultas por segundo, o Model Serving oferece otimização de rota nos endpoints de serviço de modelo personalizado, consulte Otimização de rota nos endpoints de serviço.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
API Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
API REST
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Para ver o ponto de extremidade, clique em Serviços na barra lateral esquerda da interface de utilizador do Databricks. Quando o estado estiver Pronto, o ponto de extremidade estará pronto para responder a consultas. Para saber mais sobre o Serviço do Modelo AI da Mosaic, consulte Serviço do Modelo AI da Mosaic.
Salve o DataFrame aumentado na tabela de inferência
Para terminais criados a partir de fevereiro de 2025, pode-se configurar o terminal de serviço de modelo para registar o DataFrame aumentado que contém os valores de características pesquisadas e os valores de retorno da função. O DataFrame é salvo na tabela de inferência para o modelo servido.
Para obter instruções sobre como definir esta configuração, consulte Registar DataFrames de consulta de funcionalidades em tabelas de inferência.
Para obter informações sobre tabelas de inferência, consulte Tabelas de inferência para modelos de monitoramento e depuração.
Obtenha um ponto de extremidade
Você pode usar o SDK do Databricks ou a API Python para obter os metadados e o status de um ponto de extremidade.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
API Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Obter o esquema de um ponto de extremidade
Você pode usar o SDK do Databricks ou a API REST para obter o esquema de um ponto de extremidade. Para mais informações sobre o esquema do ponto de extremidade, consulte Obter um esquema de ponto de extremidade de serviço de modelo.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
API REST
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Consultar um ponto de extremidade
Você pode usar a API REST, o SDK de implantações MLflow ou a interface de utilizador do serviço para consultar um endpoint.
O código a seguir mostra como configurar credenciais e criar o cliente ao usar o SDK de implantações MLflow.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Nota
Como prática recomendada de segurança, quando você se autentica com ferramentas, sistemas, scripts e aplicativos automatizados, o Databricks recomenda que você use tokens de acesso pessoal pertencentes a entidades de serviço em vez de usuários do espaço de trabalho. Para criar tokens para entidades de serviço, consulte Gerenciar tokens para uma entidade de serviço.
Fazer uma consulta a um endpoint usando APIs
Esta seção inclui exemplos de consulta a um endpoint usando a API REST ou o SDK de implantações do MLflow.
SDK de Implementações do MLflow
Importante
O exemplo a seguir usa a predict() API do MLflow Deployments SDK. Esta API é Experimental e a definição da API pode mudar.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
API REST
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Consultar um endpoint usando a interface do utilizador
Você pode consultar diretamente um endpoint a partir da interface de serviço. A interface do utilizador inclui exemplos de código gerado que pode usar para consultar o endpoint.
Na barra lateral esquerda do espaço de trabalho do Azure Databricks, clique em Servir.
Clique no ponto de extremidade que você deseja consultar.
No canto superior direito do ecrã, clique em Ponto de extremidade de consulta.
Na caixa Solicitação , digite o corpo da solicitação no formato JSON.
Clique em Enviar solicitação.
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
A caixa de diálogo Ponto de extremidade de consulta inclui código de exemplo gerado em curl, Python e SQL. Clique nas guias para visualizar e copiar o código de exemplo.

Para copiar o código, clique no ícone de cópia no canto superior direito da caixa de texto.
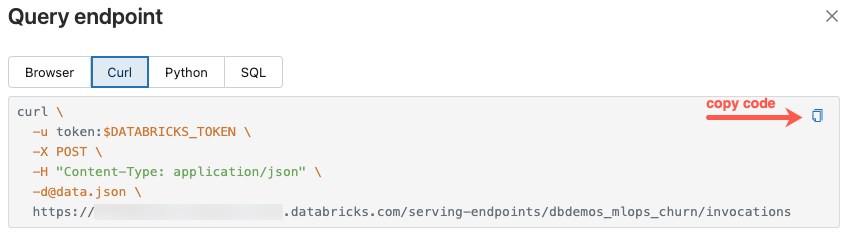
Atualizar um endpoint
Você pode atualizar um endpoint usando a API REST, o SDK do Databricks ou a interface de serviço.
Atualizar um endpoint usando APIs
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
API REST
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Atualize um endpoint usando a interface do usuário
Siga estes passos para usar a interface de serviço:
- Na barra lateral esquerda do espaço de trabalho do Azure Databricks, clique em Servir.
- Na tabela, clique no nome do ponto de extremidade que você deseja atualizar. O ecrã do endpoint aparece.
- No canto superior direito do ecrã, clique em Editar ponto de extremidade.
- Na caixa de diálogo Editar ponto de extremidade de serviço , edite as configurações do ponto de extremidade conforme necessário.
- Clique em Atualizar para salvar as alterações.

Excluir um ponto de extremidade
Aviso
Esta ação é irreversível.
Você pode excluir um endpoint utilizando a API REST, o SDK do Databricks, a API do Python ou a UI de Serviço.
Excluir um ponto de extremidade usando APIs
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
API Python
fe.delete_feature_serving_endpoint(name="customer-features")
API REST
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Excluir um ponto de extremidade usando a interface do usuário
Siga estas etapas para excluir um ponto de extremidade usando a interface de serviço:
- Na barra lateral esquerda do espaço de trabalho do Azure Databricks, clique em Servir.
- Na tabela, clique no nome do ponto de extremidade que você deseja excluir. O ecrã do endpoint aparece.
- No canto superior direito da tela, clique no
 selecione Excluir.
selecione Excluir.

Monitorizar a saúde de um ponto de extremidade
Para obter informações sobre os logs e métricas disponíveis para pontos de extremidade de serviço de funcionalidades, consulte Monitorizar a qualidade do modelo e a integridade do ponto de extremidade.
Controlo de acesso
Para obter informações sobre permissões nos endpoints de serviço de funcionalidade, consulte Gerir permissões em um endpoint de serviço de modelo.
Bloco de notas de exemplo
pt-PT: Este notebook ilustra como usar o SDK do Databricks para criar um endpoint de fornecimento de funcionalidades utilizando tabelas online do Databricks.