Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Você pode usar a divisão em mosaico para maximizar o desempenho do seu aplicativo. O particionamento divide os threads em subconjuntos retangulares iguais ou tiles. Se utilizares um tamanho de mosaico apropriado e um algoritmo em mosaico, poderás obter ainda mais aceleração do teu código AMP C++. Os componentes básicos da telha são:
tile_staticvariáveis. O principal benefício da tilagem é o ganho de desempenho no acessotile_static. O acesso aos dados natile_staticmemória pode ser significativamente mais rápido do que o acesso aos dados no espaço global (arrayarray_viewou objetos). Uma instância de umatile_staticvariável é criada para cada bloco, e todos os threads no bloco têm acesso à variável. Em um algoritmo baseado em mosaico típico, os dados são copiados paratile_staticmemória uma vez a partir da memória global e, em seguida, acessados muitas vezes a partir detile_staticmemória.Método tile_barrier::wait. Uma chamada para
tile_barrier::waitsuspende a execução do thread atual até que todos os threads no mesmo tile alcancem a chamada paratile_barrier::wait. Você não pode garantir a ordem em que os threads serão executados, apenas que nenhum thread no bloco será executado além da chamada paratile_barrier::waitaté que todos os threads tenham atingido a chamada. Isso significa que, ao usar o métodotile_barrier::wait, é possível executar tarefas bloco por bloco, em vez de thread por thread. Um algoritmo de mosaico típico tem código para inicializar atile_staticmemória para o bloco inteiro, seguido de uma chamada paratile_barrier::wait. O código a seguirtile_barrier::waitcontém cálculos que exigem acesso a todos ostile_staticvalores.Indexação local e global. Você tem acesso ao índice do thread relativo ao todo
array_viewouarrayobjeto e ao índice relativo ao bloco. Usar o índice local pode tornar seu código mais fácil de ler e depurar. Normalmente, você usa indexação local para acessartile_staticvariáveis e indexação global para acessararrayearray_viewvariáveis.Classe tiled_extent e Classe tiled_index. Você usa um objeto
tiled_extentem vez de um objetoextentna invocaçãoparallel_for_each. Você usa um objetotiled_indexem vez de um objetoindexna invocaçãoparallel_for_each.
Para tirar proveito do mosaico, seu algoritmo deve particionar o domínio de computação em blocos e, em seguida, copiar os dados do bloco em tile_static variáveis para acesso mais rápido.
Exemplo de Índices Globais, de Mosaico e Locais
Observação
Os cabeçalhos AMP C++ foram preteridos a partir do Visual Studio 2022 versão 17.0.
A inclusão de cabeçalhos AMP gerará erros de compilação. Defina _SILENCE_AMP_DEPRECATION_WARNINGS antes de incluir quaisquer cabeçalhos AMP para silenciar os avisos.
O diagrama a seguir representa uma matriz de dados 8x9 organizada em blocos 2x3.
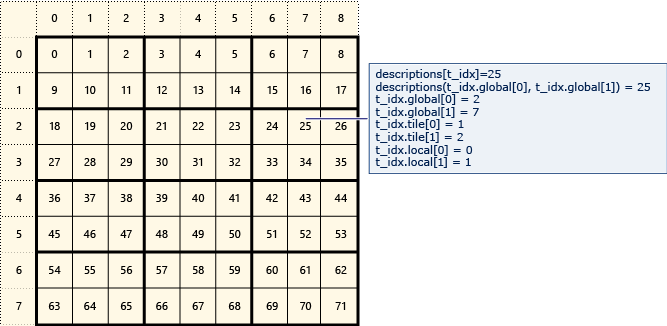
O exemplo a seguir exibe os índices globais, de mosaico e locais desta matriz em mosaico. Um array_view objeto é criado usando elementos do tipo Description. O Description contém os índices globais, de bloco e locais do elemento na matriz. O código na chamada para parallel_for_each define os valores dos índices global, de bloco e local de cada elemento. Os valores nas Description estruturas são exibidos na saída.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
O trabalho principal do exemplo está na definição do array_view objeto e na chamada para parallel_for_each.
O vetor de
Descriptionestruturas é copiado para um objeto de 8x9array_view.O
parallel_for_eachmétodo é chamado com umtiled_extentobjeto como o domínio de computação. Otiled_extentobjeto é criado chamando oextent::tile()descriptionsmétodo da variável. Os parâmetros de tipo da chamada paraextent::tile(),<2,3>, especificam que blocos 2x3 são criados. Assim, a matriz 8x9 é dividida em 12 blocos, distribuídos em quatro linhas e três colunas.O
parallel_for_eachmétodo é chamado usando umtiled_index<2,3>objeto (t_idx) como o índice. Os parâmetros de tipo do índice (t_idx) devem corresponder aos parâmetros de tipo do domínio de computação (descriptions.extent.tile< 2, 3>()).Quando cada thread é executado, o índice
t_idxretorna informações sobre em qual bloco o thread está (tiled_index::tilepropriedade) e o local do thread dentro do bloco (tiled_index::localpropriedade).
Sincronização de mosaicos — tile_static e tile_barrier::wait
O exemplo anterior ilustra o layout e os índices do tile, mas não é em si mesmo muito útil. A tesselação torna-se útil quando as tesselas são parte integrante do algoritmo e exploram tile_static variáveis. Como todos os threads em um tile têm acesso às variáveis tile_static, as chamadas para tile_barrier::wait são usadas para sincronizar o acesso às variáveis tile_static. Embora todos os threads em um bloco tenham acesso às tile_static variáveis, não há ordem garantida de execução dos threads no bloco. O exemplo a seguir mostra como usar tile_static variáveis e o tile_barrier::wait método para calcular o valor médio de cada bloco. Aqui estão as chaves para entender o exemplo:
O rawData é armazenado em uma matriz 8x8.
O tamanho do azulejo é 2x2. Isso cria uma grade 4x4 de blocos, e as médias podem ser armazenadas em uma matriz 4x4 usando um objeto
array. Há apenas um número limitado de tipos que você pode capturar por referência em uma função restrita a AMP. Aarrayclasse é uma delas.O tamanho da matriz e o tamanho da amostra são definidos usando
#defineinstruções, porque os parâmetros de tipo paraarray,array_view,extent, etiled_indexdevem ser valores constantes. Você também pode usar declaraçõesconst int static. Como benefício adicional, é trivial alterar o tamanho da amostra para calcular a média em blocos 4x4.Uma
tile_staticmatriz 2x2 de valores flutuantes é declarada para cada bloco. Embora a declaração esteja no caminho de código para cada thread, apenas uma matriz é criada para cada bloco na matriz.Há uma linha de código para copiar os valores em cada bloco para a
tile_staticmatriz. Para cada thread, depois de o valor ser copiado para a matriz, a execução no thread para pela chamada paratile_barrier::wait.Quando todos os fios de uma telha atingirem a barreira, a média pode ser calculada. Como o código é executado para cada thread, há uma
ifinstrução para calcular apenas a média em um thread. A média é armazenada na variável médias. A barreira é essencialmente a construção que controla os cálculos por bloco, semelhante a como se usaria umforloop.Os dados na
averagesvariável, por serem umarrayobjeto, devem ser copiados de volta para o host. Este exemplo usa o operador de conversão vetorial.No exemplo completo, você pode alterar SAMPLESIZE para 4 e o código é executado corretamente sem quaisquer outras alterações.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Condições da Corrida
Pode ser tentador criar uma tile_static variável chamada total e incrementar essa variável para cada thread, da seguinte forma:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
O primeiro problema com essa abordagem é que tile_static as variáveis não podem ter inicializadores. O segundo problema é que há uma condição de corrida na atribuição para total, porque todos os threads no tile têm acesso à variável sem uma ordem específica. Você pode programar um algoritmo para permitir que apenas um thread acesse o total em cada barreira, como mostrado a seguir. No entanto, esta solução não é extensível.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Barreiras de Memória
Há dois tipos de acessos à memória que devem ser sincronizados: acesso à memória global e tile_static acesso à memória. Um concurrency::array objeto aloca apenas memória global. A concurrency::array_view pode fazer referência à memória global, à memória tile_static, ou a ambas, dependendo de como foi construída. Existem dois tipos de memória que devem ser sincronizados:
memória global
tile_static
Uma cerca de memória garante que os acessos à memória estejam disponíveis para outros threads no bloco de threads e que os acessos à memória sejam executados de acordo com a ordem do programa. Para garantir isso, os compiladores e processadores não reordenam leituras e gravações através da cerca. No C++ AMP, uma cerca de memória é criada por uma chamada para um destes métodos:
Método tile_barrier::wait: Cria uma barreira em torno do global e da
tile_staticmemória.Método tile_barrier::wait_with_all_memory_fence: Cria uma barreira em torno da memória global e
tile_static.Método tile_barrier::wait_with_global_memory_fence: Cria uma cerca apenas em torno da memória global.
Método tile_barrier::wait_with_tile_static_memory_fence: Cria uma cerca em torno somente da
tile_staticmemória.
Chamar a cerca específica que você precisa pode melhorar o desempenho do seu aplicativo. O tipo de barreira afeta como o compilador e o hardware reordenam as instruções. Por exemplo, se você usar uma cerca de memória global, ela se aplicará somente a acessos à memória global e, portanto, o compilador e o hardware poderão reordenar leituras e gravações tile_static em variáveis nos dois lados da cerca.
No exemplo seguinte, a barreira sincroniza as gravações com tileValues, uma tile_static variável. Neste exemplo, tile_barrier::wait_with_tile_static_memory_fence é chamado em vez de tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Ver também
C++ AMP (paralelismo maciço acelerado em C++)
tile_static palavra-chave