หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
กลไกการดําเนินการแบบดั้งเดิมคือการเพิ่มประสิทธิภาพแบบใหม่สําหรับการดําเนินการงาน Apache Spark ใน Microsoft Fabric กลไกแบบเวกเตอร์นี้ปรับประสิทธิภาพและประสิทธิภาพของคิวรี Spark ของคุณให้เหมาะสมโดยการเรียกใช้โดยตรงบนโครงสร้างพื้นฐานของเลคเฮ้าส์ของคุณ การรวมที่ราบรื่นของเครื่องยนต์หมายความว่าไม่จําเป็นต้องแก้ไขรหัสและหลีกเลี่ยงการล็อคผู้จัดจําหน่าย รองรับ Apache Spark API และเข้ากันได้กับ Runtime 1.3 (Apache Spark 3.5) และทํางานกับทั้งรูปแบบ Parquet และ Delta ได้ โดยไม่คํานึงถึงตําแหน่งที่ตั้งของข้อมูลของคุณภายใน OneLake หรือถ้าคุณเข้าถึงข้อมูลผ่านทางลัด กลไกการดําเนินการแบบดั้งเดิมจะเพิ่มประสิทธิภาพและประสิทธิภาพสูงสุด
กลไกการดําเนินการแบบดั้งเดิมช่วยยกระดับประสิทธิภาพคิวรีได้อย่างมากในขณะที่ลดค่าใช้จ่ายในการดําเนินงาน ให้ประสิทธิภาพที่เร็วขึ้นถึงสี่เท่าเมื่อเทียบกับ OSS (ซอฟต์แวร์โอเพ่นซอร์ส) Spark แบบดั้งเดิม ตามที่ตรวจสอบโดยเกณฑ์มาตรฐาน TPC-DS 1 TB กลไกจัดการอย่างเหมาะสมในการจัดการสถานการณ์การประมวลผลข้อมูลที่หลากหลาย ตั้งแต่การนําเข้าข้อมูลประจํา ชุดงาน และ ETL (แยก แปลง โหลด) ไปจนถึงการวิเคราะห์วิทยาศาสตร์ข้อมูลที่ซับซ้อนและคิวรีแบบโต้ตอบแบบตอบสนอง ผู้ใช้ได้รับประโยชน์จากเวลาการประมวลผลที่เร่ง ความเร็วที่สูงขึ้น และการใช้ทรัพยากรที่ดีที่สุด
กลไกการดําเนินการแบบเนทีฟนั้นยึดตามส่วนประกอบ OSS หลักสองส่วน: Velox, ไลบรารีการเร่งฐานข้อมูล C++ ที่นําเสนอโดยเมตาและ Apache Gluten (incubating) เลเยอร์กลางที่รับผิดชอบในการถ่ายเอกสารการดําเนินการของกลไก SQL ที่ใช้ JVM ไปยังกลไกดั้งเดิมที่เปิดตัวโดย Intel
เมื่อต้องใช้กลไกจัดการการดําเนินการดั้งเดิม
กลไกการดําเนินการแบบดั้งเดิมเสนอโซลูชันสําหรับการเรียกใช้คิวรีบนชุดข้อมูลขนาดใหญ่ ซึ่งปรับประสิทธิภาพให้เหมาะสมโดยใช้ความสามารถดั้งเดิมของแหล่งข้อมูลต้นแบบ และลดค่าใช้จ่ายที่เกี่ยวข้องกับการเคลื่อนไหวของข้อมูลและการจัดเรียงเป็นอนุกรมในสภาพแวดล้อม Spark แบบดั้งเดิม กลไกจัดการสนับสนุนตัวดําเนินการและชนิดข้อมูลต่าง ๆ รวมถึงการรวมแฮชค่าสะสม การออกอากาศแบบซ้อนกันการรวม (BNLJ) และรูปแบบประทับเวลาอย่างแม่นยํา อย่างไรก็ตามเพื่อให้ได้รับประโยชน์อย่างเต็มที่จากความสามารถของเครื่องยนต์ คุณควรพิจารณากรณีการใช้งานที่เหมาะสมที่สุด:
- กลไกจัดการมีประสิทธิภาพเมื่อทํางานกับข้อมูลในรูปแบบ Parquet และ Delta ซึ่งสามารถประมวลผลได้อย่างสมบูรณ์และมีประสิทธิภาพ
- คิวรีที่เกี่ยวข้องกับการแปลงและการรวมที่สลับซับซ้อนจะได้รับประโยชน์อย่างมากจากการประมวลผลแบบคอลัมน์และความสามารถของเวกเตอร์ของกลไกจัดการ
- การปรับปรุงประสิทธิภาพการทํางานที่โดดเด่นที่สุดในสถานการณ์ที่คิวรีไม่สามารถทริกเกอร์กลไกการแสดงแทนโดยการหลีกเลี่ยงคุณลักษณะหรือนิพจน์ที่ไม่สนับสนุน
- กลไกนี้เหมาะอย่างยิ่งสําหรับคิวรีที่ใช้การคํานวณมากกว่าแบบง่ายหรือ I/O-bound
สําหรับข้อมูลเกี่ยวกับตัวดําเนินการและฟังก์ชันที่ได้รับการสนับสนุนโดยกลไกการดําเนินการดั้งเดิม โปรดดู เอกสารกํากับ Apache Gluten
เปิดใช้งานกลไกการดําเนินการแบบดั้งเดิม
หากต้องการใช้ความสามารถแบบเต็มของกลไกการดําเนินการแบบดั้งเดิมในระหว่างขั้นตอนการแสดงตัวอย่าง จําเป็นต้องมีการกําหนดค่าเฉพาะ ขั้นตอนต่อไปนี้แสดงวิธีการเปิดใช้งานคุณลักษณะนี้สําหรับสมุดบันทึก ข้อกําหนดงาน Spark และสภาพแวดล้อมทั้งหมด
สำคัญ
กลไกการดําเนินการแบบดั้งเดิมสนับสนุนเวอร์ชันรันไทม์ GA ล่าสุดซึ่งเป็น Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) ด้วยการเปิดตัวเอ็นจิ้นการดําเนินการแบบเนทีฟใน Runtime 1.3 การสนับสนุนสําหรับเวอร์ชันก่อนหน้า - Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4) - จะถูกยกเลิก เราขอแนะนําให้ลูกค้าทุกรายอัปเกรดเป็น Runtime 1.3 ล่าสุด หากคุณกําลังใช้กลไกการดําเนินการดั้งเดิมบนรันไทม์ 1.2 การเร่งความเร็วแบบเนทีฟจะถูกปิดใช้งาน
เปิดใช้งานในระดับสภาพแวดล้อม
เพื่อให้แน่ใจว่าการปรับปรุงประสิทธิภาพการทํางานสม่ําเสมอ ให้เปิดใช้งานกลไกการดําเนินการแบบดั้งเดิมทั่วทั้งงานและสมุดบันทึกทั้งหมดที่เกี่ยวข้องกับสภาพแวดล้อมของคุณ:
นําทางไปยังพื้นที่ทํางานที่มีสภาพแวดล้อมของคุณและเลือกสภาพแวดล้อม หากคุณไม่ได้สร้างสภาพแวดล้อม โปรดดู สร้าง กําหนดค่า และใช้สภาพแวดล้อมใน Fabric
ภายใต้ Spark compute ให้เลือก การเร่งความเร็ว
เลือกกล่องที่มี ป้ายชื่อ เปิดใช้งานกลไกจัดการการดําเนินการแบบดั้งเดิม
บันทึกและเผยแพร่ การเปลี่ยนแปลง
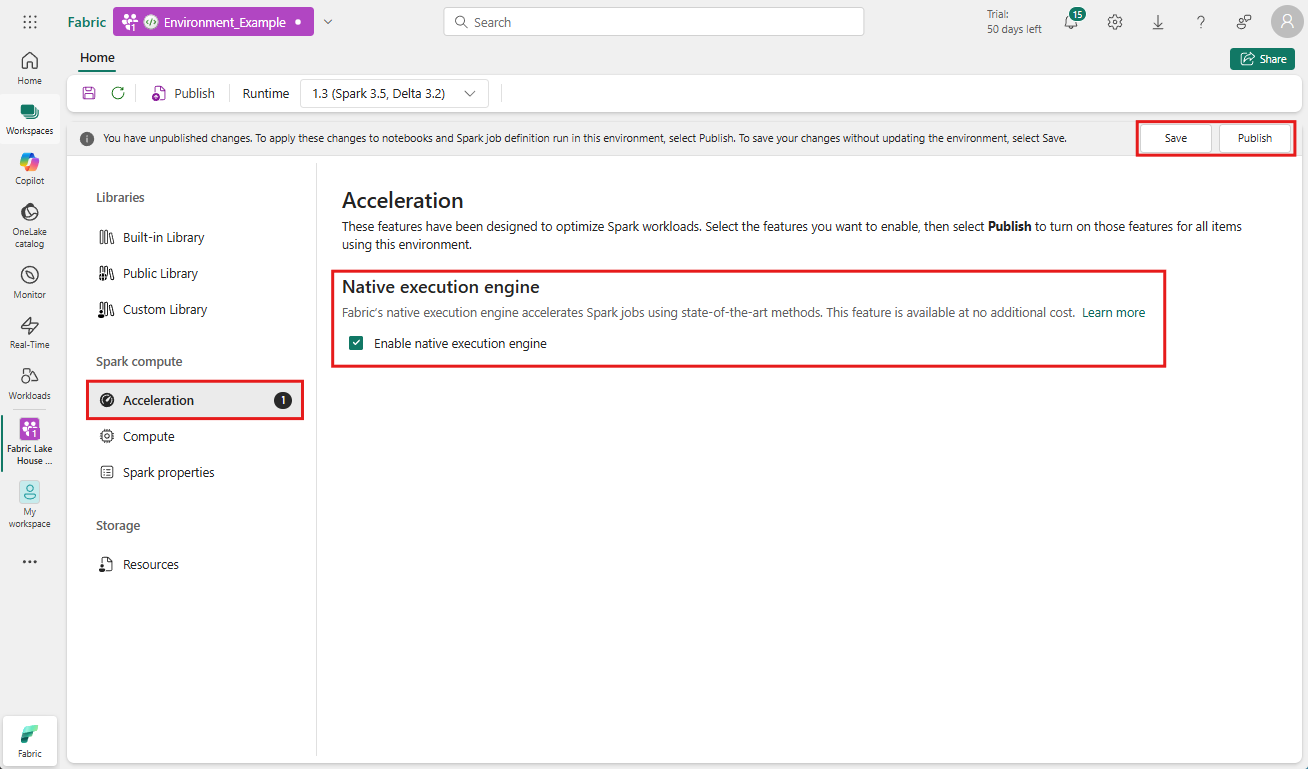

เมื่อเปิดใช้งานในระดับสภาพแวดล้อม งานและสมุดบันทึกที่ตามมาทั้งหมดจะสืบทอดการตั้งค่า การรับช่วงนี้ช่วยให้มั่นใจได้ว่าเซสชันใหม่หรือทรัพยากรใด ๆ ที่สร้างขึ้นในสภาพแวดล้อมจะได้รับประโยชน์โดยอัตโนมัติจากความสามารถในการดําเนินการที่ได้รับการปรับปรุง
สำคัญ
ก่อนหน้านี้ กลไกการดําเนินการดั้งเดิมถูกเปิดใช้งานผ่านการตั้งค่า Spark ภายในการกําหนดค่าสภาพแวดล้อม ขณะนี้กลไกการดําเนินการแบบดั้งเดิมสามารถเปิดใช้งานได้ง่ายขึ้นโดยใช้การสลับในแท็บ Acceleration ของการตั้งค่าสภาพแวดล้อม หากต้องการใช้งานต่อ ให้ไปที่แท็บ การเร่ง ความเร็ว และเปิดการสลับ คุณยังสามารถเปิดใช้งานผ่านคุณสมบัติ Spark ได้หากต้องการ
เปิดใช้งานสําหรับสมุดบันทึกหรือข้อกําหนดงาน Spark
คุณยังสามารถเปิดใช้งานกลไกการดําเนินการดั้งเดิมสําหรับสมุดบันทึกเดี่ยวหรือข้อกําหนดงาน Spark คุณต้องรวมการกําหนดค่าที่จําเป็นที่จุดเริ่มต้นของสคริปต์การดําเนินการของคุณ:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
สําหรับสมุดบันทึก ให้ใส่คําสั่งการกําหนดค่าที่จําเป็นในเซลล์แรก สําหรับข้อกําหนดงาน Spark ให้รวมการกําหนดค่าไว้ที่ด้านหน้าข้อกําหนดงาน Spark ของคุณ กลไกการดําเนินการแบบดั้งเดิมถูกรวมเข้ากับพูลสด ดังนั้นเมื่อคุณเปิดใช้งานคุณลักษณะจะมีผลทันทีโดยที่คุณไม่จําเป็นต้องเริ่มต้นเซสชันใหม่
ควบคุมระดับคิวรี
กลไกการเปิดใช้งานกลไกการดําเนินการดั้งเดิมที่ระดับผู้เช่า พื้นที่ทํางาน และสภาพแวดล้อม รวมกับ UI อย่างราบรื่นอยู่ระหว่างการพัฒนาที่ใช้งานอยู่ ในระหว่างนี้ คุณสามารถปิดใช้งานกลไกการดําเนินการดั้งเดิมสําหรับคิวรีเฉพาะ โดยเฉพาะอย่างยิ่งถ้าเกี่ยวข้องกับตัวดําเนินการที่ไม่ได้รับการสนับสนุนในขณะนี้ (ดู ข้อจํากัด) เมื่อต้องการปิดใช้งาน ให้ตั้งค่า Spark configuration spark.native.enabled เป็น false สําหรับเซลล์เฉพาะที่มีคิวรีของคุณ
%%sql
SET spark.native.enabled=FALSE;

หลังจากดําเนินการคิวรีที่กลไกการดําเนินการดั้งเดิมถูกปิดใช้งาน คุณต้องเปิดใช้งานอีกครั้งสําหรับเซลล์ที่ตามมาโดยการตั้งค่า spark.native.enabled เป็น true ขั้นตอนนี้มีความจําเป็นเนื่องจาก Spark จะดําเนินการกับเซลล์โค้ดตามลําดับ
%%sql
SET spark.native.enabled=TRUE;
ระบุการดําเนินการที่ดําเนินการโดยกลไกจัดการ
มีหลายวิธีในการตรวจสอบว่าตัวดําเนินการในงาน Apache Spark ของคุณได้รับการประมวลผลโดยใช้กลไกการดําเนินการดั้งเดิมหรือไม่
Spark UI และเซิร์ฟเวอร์ประวัติ Spark
เข้าถึงเซิร์ฟเวอร์ประวัติ Spark UI หรือ Spark เพื่อค้นหาคิวรีที่คุณต้องการตรวจสอบ เมื่อต้องการเข้าถึง UI ของเว็บ Spark ให้นําทางไปยังข้อกําหนดงาน Spark ของคุณและเรียกใช้งาน จากแท็บ

ในแผนคิวรีที่แสดงภายในอินเทอร์เฟซ Spark UI ให้ค้นหาชื่อโหนดใด ๆ ที่ลงท้ายด้วยคําต่อท้าย Transformer, *NativeFileScan หรือ VeloxColumnarToRowExec คําต่อท้ายระบุว่ากลไกจัดการการดําเนินการแบบดั้งเดิมจะดําเนินการ ตัวอย่างเช่น โหนดอาจติดป้ายชื่อว่า RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer หรือ BroadcastNestedLoopJoinExecTransformer

อธิบาย DataFrame
อีกวิธีหนึ่งคือ คุณสามารถดําเนินการ df.explain() คําสั่งในสมุดบันทึกของคุณเพื่อดูแผนการดําเนินการ ภายในผลลัพธ์ ให้ค้นหาคําต่อท้าย Transformer, *NativeFileScan หรือ VeloxColumnarToRowExec เดียวกัน วิธีนี้ให้วิธีการที่รวดเร็วเพื่อยืนยันว่าการดําเนินการที่เฉพาะเจาะจงได้รับการจัดการโดยกลไกจัดการการดําเนินการดั้งเดิมหรือไม่

กลไกที่ใช้แสดงแทน
ในบางอินสแตนซ์ กลไกการดําเนินการดั้งเดิมอาจไม่สามารถดําเนินการคิวรีได้เนื่องจากเหตุผลเช่นคุณลักษณะที่ไม่ได้รับการรองรับ ในกรณีเหล่านี้ การดําเนินการจะกลับสู่กลไก Spark แบบดั้งเดิม กลไกที่ใช้แสดงแทนอัตโนมัตินี้ช่วยให้แน่ใจว่าเวิร์กโฟลว์ของคุณไม่มีการหยุดชะงัก


ตรวจสอบคิวรีและ DataFrames ที่ดําเนินการโดยกลไกจัดการ
เพื่อให้เข้าใจวิธีการที่กลไกการดําเนินการดั้งเดิมถูกนําไปใช้กับคิวรี SQL และการดําเนินการ DataFrame และเพื่อเจาะลึกลงไปถึงระดับขั้นตอนและตัวดําเนินการ คุณสามารถอ้างอิงถึง Spark UI และ Spark History Server สําหรับรายละเอียดเพิ่มเติมเกี่ยวกับการดําเนินการของกลไกจัดการแบบดั้งเดิม
แท็บกลไกการดําเนินการแบบดั้งเดิม
คุณสามารถนําทางไปยังแท็บ 'Gluten SQL / DataFrame' ใหม่เพื่อดูข้อมูลการสร้าง Gluten และรายละเอียดการดําเนินการคิวรี ตารางคิวรีให้ข้อมูลเชิงลึกเกี่ยวกับจํานวนของโหนดที่ทํางานบนกลไกจัดการดั้งเดิมและที่ถอยกลับไปยัง JVM สําหรับแต่ละคิวรี

กราฟการดําเนินการคิวรี
คุณยังสามารถเลือกคําอธิบายคิวรีสําหรับการแสดงภาพแผนการดําเนินการคิวรี Apache Spark ได้ กราฟการดําเนินการมีรายละเอียดการดําเนินการดั้งเดิมในขั้นตอนต่าง ๆ และการดําเนินการที่เกี่ยวข้อง สีพื้นหลังจะแยกความแตกต่างของกลไกการดําเนินการ: สีเขียวแสดงกลไกจัดการการดําเนินการแบบดั้งเดิม ในขณะที่สีน้ําเงินอ่อนแสดงว่าการดําเนินการกําลังทํางานบนกลไกจัดการ JVM เริ่มต้น

ข้อจำกัด
ในขณะที่กลไกการดําเนินการแบบเนทีฟ (NEE) ใน Microsoft Fabric ช่วยเพิ่มประสิทธิภาพการทํางานสําหรับงาน Apache Spark อย่างมาก แต่ในขณะนี้มีข้อจํากัดดังต่อไปนี้:
ข้อจํากัดที่มีอยู่
คุณสมบัติ Spark ที่เข้ากันไม่ได้: กลไกการดําเนินการแบบเนทีฟไม่รองรับฟังก์ชันที่ผู้ใช้กําหนด (UDF)
array_containsฟังก์ชัน หรือการสตรีมแบบมีโครงสร้างในขณะนี้ ถ้ามีการใช้ฟังก์ชันหรือคุณลักษณะที่ไม่รองรับเหล่านี้โดยตรงหรือผ่านไลบรารีที่นําเข้า Spark จะแปลงกลับเป็นเครื่องมือเริ่มต้นรูปแบบไฟล์ที่ไม่รองรับ: คิวรีกับ
JSON,XMLและCSVรูปแบบจะไม่เร่งความเร็วโดยกลไกการดําเนินการดั้งเดิม ค่าเริ่มต้นเหล่านี้จะกลับไปใช้เอ็นจิ้น Spark JVM ปกติสําหรับการดําเนินการไม่รองรับโหมด ANSI: เอ็นจิ้นการดําเนินการดั้งเดิมไม่รองรับโหมด ANSI SQL หากเปิดใช้งาน การดําเนินการจะกลับไปที่กลไกจัดการวานิลลา Spark
ชนิดตัวกรองวันที่ไม่ตรงกัน: เพื่อใช้ประโยชน์จากการเร่งของกลไกการดําเนินการดั้งเดิม ตรวจสอบให้แน่ใจว่าทั้งสองด้านของการเปรียบเทียบวันที่ตรงกันในชนิดข้อมูล ตัวอย่างเช่น แทนที่จะเปรียบเทียบ
DATETIMEคอลัมน์กับสัญพจน์สตริง ให้ส่งคอลัมน์อย่างชัดเจนตามที่แสดง:CAST(order_date AS DATE) = '2024-05-20'
ข้อควรพิจารณาและข้อจํากัดอื่น ๆ
การชี้ขาดทศนิยมถึงทศนิยม: เมื่อการคัดเลือกจาก
DECIMALเป็นFLOATSpark จะรักษาความแม่นยําโดยการแปลงเป็นสตริงและแยกวิเคราะห์ NEE (ผ่าน Velox) ทําการแคสต์โดยตรงจากตัวแทนภายในint128_tซึ่งอาจส่งผลให้เกิดความขัดแย้งในการปัดเศษข้อผิดพลาดในการกําหนดค่าโซนเวลา : การตั้งค่าโซนเวลาที่ไม่รู้จักใน Spark ทําให้งานล้มเหลวภายใต้ NEE ในขณะที่ Spark JVM จัดการได้อย่างนุ่มนวล เช่น:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEพฤติกรรมการปัดเศษที่ไม่สอดคล้องกัน:
round()ฟังก์ชันทํางานแตกต่างกันใน NEE เนื่องจากการพึ่งstd::roundพา ซึ่งไม่ได้จําลองตรรกะการปัดเศษของ Spark ซึ่งอาจนําไปสู่ความไม่สอดคล้องกันของตัวเลขในการปัดเศษผลลัพธ์ฟังก์ชันการ
map()เช็คอินคีย์ที่ซ้ํากันหายไป: เมื่อspark.sql.mapKeyDedupPolicyตั้งค่าเป็น EXCEPTION Spark จะแสดงข้อผิดพลาดสําหรับคีย์ที่ซ้ํากัน ขณะนี้ NEE ข้ามการตรวจสอบนี้และอนุญาตให้คิวรีสําเร็จอย่างไม่ถูกต้อง
ตัวอย่าง:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}ค่าความแปรปรวนของลําดับในการ
collect_list()เรียงลําดับ: เมื่อใช้DISTRIBUTE BYและSORT BYSpark จะรักษาลําดับองค์ประกอบในcollect_list()NEE อาจส่งคืนค่าในลําดับที่ต่างกันเนื่องจากความแตกต่างของการสับเปลี่ยน ซึ่งอาจส่งผลให้ความคาดหวังไม่ตรงกันสําหรับตรรกะที่ไวต่อการสั่งซื้อประเภทกลางไม่ตรงกันสําหรับ
collect_list()/collect_set(): Spark ใช้BINARYเป็นชนิดระดับกลางสําหรับการรวมเหล่านี้ ในขณะที่ NEE ใช้ARRAYความไม่ตรงกันนี้อาจนําไปสู่ปัญหาความเข้ากันได้ในระหว่างการวางแผนหรือการดําเนินการแบบสอบถามปลายทางส่วนตัวที่มีการจัดการที่จําเป็นสําหรับการเข้าถึงที่เก็บข้อมูล: เมื่อเปิดใช้งาน Native Execution Engine (NEE) และหากงาน Spark พยายามเข้าถึง Storage Accont โดยใช้ Managed Private Endpoint ผู้ใช้ต้องกําหนดค่า Managed Private Endpoint แยกต่างหากสําหรับทั้ง Blob (blob.core.windows.net) และ DFS / File System (dfs.core.windows.net) Endpoint แม้ว่าจะชี้ไปที่บัญชีที่เก็บข้อมูลเดียวกันก็ตาม ไม่สามารถนําปลายทางเดียวกลับมาใช้ใหม่ได้ทั้งสองอย่าง นี่เป็นข้อจํากัดในปัจจุบันและอาจต้องมีการกําหนดค่าเครือข่ายเพิ่มเติมเมื่อเปิดใช้งานเอ็นจิ้นการดําเนินการดั้งเดิมในพื้นที่ทํางานที่มีการจัดการปลายทางส่วนตัวไปยังบัญชีที่เก็บข้อมูล