หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
ในคู่มือนี้ คุณจะ:
อัปโหลดข้อมูลไปยัง OneLake ด้วยตัวสํารวจไฟล์ OneLake
ใช้สมุดบันทึก Fabric เพื่ออ่านข้อมูลบน OneLake และเขียนกลับเป็นตาราง Delta
วิเคราะห์และแปลงข้อมูลด้วย Spark โดยใช้สมุดบันทึก Fabric
คิวรีหนึ่งสําเนาของข้อมูลบน OneLake ด้วย SQL
ข้อกำหนดเบื้องต้น
ก่อนที่คุณจะเริ่มต้น คุณต้อง:
ดาวน์โหลดและติดตั้ง OneLake file explorer
สร้างพื้นที่ทํางานด้วยรายการเลคเฮ้าส์
ดาวน์โหลดชุดข้อมูล WideWorldImportersDW คุณสามารถใช้ Azure Storage Explorer เพื่อ
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityเชื่อมต่อและดาวน์โหลดชุดไฟล์ csv ได้ หรือคุณสามารถใช้ข้อมูล csv ของคุณเองและอัปเดตรายละเอียดตามที่จําเป็น
อัปโหลดข้อมูล
ในส่วนนี้ คุณอัปโหลดข้อมูลทดสอบลงใน lakehouse ของคุณโดยใช้ OneLake file explorer
ในตัวสํารวจไฟล์ OneLake ให้นําทางไปยัง lakehouse ของคุณและสร้างไดเรกทอรีย่อยที่ชื่อ
dimension_cityภายใต้ไดเรกทอรี/Files
คัดลอกไฟล์ csv ตัวอย่างของคุณไปยังไดเรกทอรี
/Files/dimension_cityOneLake โดยใช้ตัวสํารวจไฟล์ OneLake
นําทางไปยังเลคเฮ้าส์ของคุณในบริการ Power BI หรือ Fabric และดูไฟล์ของคุณ


สร้างตาราง Delta
ในส่วนนี้ คุณแปลงไฟล์ CSV ที่ไม่มีการจัดการลงในตารางที่มีการจัดการโดยใช้รูปแบบ Delta
หมายเหตุ
สร้าง โหลด หรือสร้างทางลัดไปยังข้อมูล Delta-Parquet โดยตรง ภายใต้ ส่วน ตาราง ของเลคเฮ้าส์ อย่าซ้อนตารางของคุณในโฟลเดอร์ย่อยภายใต้ส่วน Table lakehouse ไม่จดจําโฟลเดอร์ย่อยเป็นตารางและป้ายชื่อเป็น ที่ไม่สามารถระบุได้
ในเลคเฮาส์ของคุณ ให้เลือก เปิดสมุดบันทึก จากนั้น สมุดบันทึกใหม่เพื่อสร้างสมุดบันทึก

ใช้โน้ตบุ๊ค Fabric แปลงไฟล์ CSV เป็นรูปแบบ Delta ส่วนย่อยของโค้ดต่อไปนี้จะอ่านข้อมูลจากไดเรกทอรี
/Files/dimension_cityที่ผู้ใช้สร้างขึ้นและแปลงเป็นตารางdim_cityDeltaคัดลอกส่วนย่อยของโค้ดลงในตัวแก้ไขเซลล์ของสมุดบันทึก แทนที่พื้นที่ที่สํารองไว้ด้วยรายละเอียดพื้นที่ทํางานของคุณเอง จากนั้นเลือก เรียกใช้ เซลล์ หรือ เรียกใช้ทั้งหมด
import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/dimension_city"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<YOUR_WORKSPACE_NAME>@onelake.dfs.fabric.microsoft.com/<YOUR_LAKEHOUSE_NAME>.Lakehouse/Files/dimension_city/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/dim_city")ปลาย
คุณสามารถเรียกใช้เส้นทาง ABFS แบบเต็มไปยังไดเรกทอรีของคุณโดยการคลิกขวาที่ชื่อไดเรกทอรีและเลือก คัดลอกเส้นทาง ABFS
หากต้องการดูตารางใหม่ของคุณ ให้รีเฟรชมุมมองของ
/Tablesไดเรกทอรี เลือกตัวเลือกเพิ่มเติม (...) ถัดจากไดเรกทอรีตาราง จากนั้นเลือก รีเฟรช
คิวรีและปรับเปลี่ยนข้อมูล
ในส่วนนี้ คุณใช้สมุดบันทึก Fabric เพื่อโต้ตอบกับข้อมูลในตารางของคุณ
คิวรีตารางของคุณด้วย SparkSQL ในสมุดบันทึก Fabric เดียวกัน
%%sql SELECT * from <LAKEHOUSE_NAME>.dim_city LIMIT 10;ปรับเปลี่ยนตาราง Delta โดยการเพิ่มคอลัมน์ใหม่ที่ ชื่อ newColumn ด้วยจํานวนเต็มของชนิดข้อมูล ตั้งค่า 9 สําหรับเรกคอร์ดทั้งหมดสําหรับคอลัมน์ที่เพิ่งเพิ่มใหม่นี้
%%sql ALTER TABLE <LAKEHOUSE_NAME>.dim_city ADD COLUMN newColumn int; UPDATE <LAKEHOUSE_NAME>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <LAKEHOUSE_NAME>.dim_city LIMIT 10;
คุณยังสามารถเข้าถึงตาราง Delta ใดก็ได้บน OneLake ผ่านจุดสิ้นสุดการวิเคราะห์ SQL จุดสิ้นสุดการวิเคราะห์ SQL อ้างอิงสําเนาเดียวกันของตาราง Delta บน OneLake และนําเสนอประสบการณ์ T-SQL
นําทางไปยังเลคเฮ้าส์ของคุณ จากนั้นเลือก Lakehouse>จุดสิ้นสุดการวิเคราะห์ SQL จากเมนูดรอปดาวน์
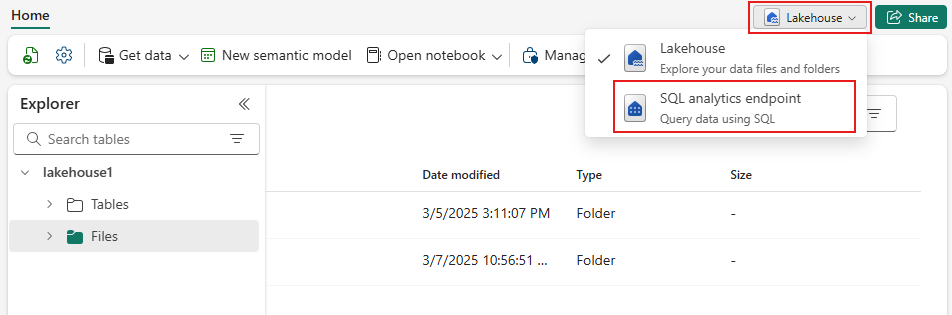
เลือก คิวรี SQL ใหม่เพื่อคิวรีตารางโดยใช้ T-SQL
คัดลอก และวางรหัสต่อไปนี้ลงในตัวแก้ไขคิวรี จากนั้นเลือก เรียกใช้
SELECT TOP (100) * FROM [<LAKEHOUSE_NAME>].[dbo].[dim_city];