你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Microsoft Foundry 提供了一个统一的平台,用于使用各种模型和工具构建、管理和部署 AI 解决方案。 Foundry游乐场是 Foundry 门户内的交互式环境,专为探索、测试和原型制作各种 AI 模型和工具而设计。
使用本文作为入门指南,了解如何使用 Foundry 或 REST API 进行对话语言理解。
注意
- 如果已拥有 Foundry 工具中的 Azure 语言或多服务资源(无论是单独使用还是通过 Language Studio 使用),则可以继续在 Microsoft Foundry 门户中使用这些现有语言资源。
- 有关详细信息,请参阅 如何在 Foundry 门户中使用 Foundry 工具。
- 强烈建议在 Foundry 中使用 Foundry 资源;但也可以使用语言资源按照这些说明操作。
Prerequisites
- Azure 订阅。 如果没有帐户,可以免费创建一个帐户。
- 必备权限。 确保在订阅级别将建立帐户和项目的人员分配为 Azure AI 帐户所有者角色。 或者,拥有订阅范围的“参与者”或“认知服务参与者”角色也会满足此要求。 有关详细信息,请参阅基于角色的访问控制 (RBAC)。
- Foundry 资源。 有关详细信息, 请参阅配置 Foundry 资源。 或者,可以使用 语言资源。
- 在 Foundry 中创建的 Foundry 项目。 有关详细信息, 请参阅创建 Foundry 项目。
Foundry 入门
若要完成本快速入门,需要一个对话语言理解 (CLU) 微调任务项目,其中包含定义的架构和标记的话语。
可以下载示例项目文件,该文件预配置了架构和标记的话语。 该项目可以预测用户阅读电子邮件、删除电子邮件和将文档附加到电子邮件等命令的意图。
让我们开始吧:
- 导航到 Foundry。
- 如果尚未登录,门户会提示你使用 Azure 凭据执行此操作。
- 登录后,可以在 Foundry 中创建或访问现有项目。
- 如果尚未开始执行此任务的项目,请选择它。
- 在左侧导航窗格中,选择 “游乐场”,导航到 “语言游乐场”磁贴,然后选择“ 试用 Azure 语言游乐场 ”按钮。

试用 Azure 语言体验区
Azure 语言控制台的顶部是用户可以查看和选择可用语言的地方。
选择“对话语言理解”磁贴。
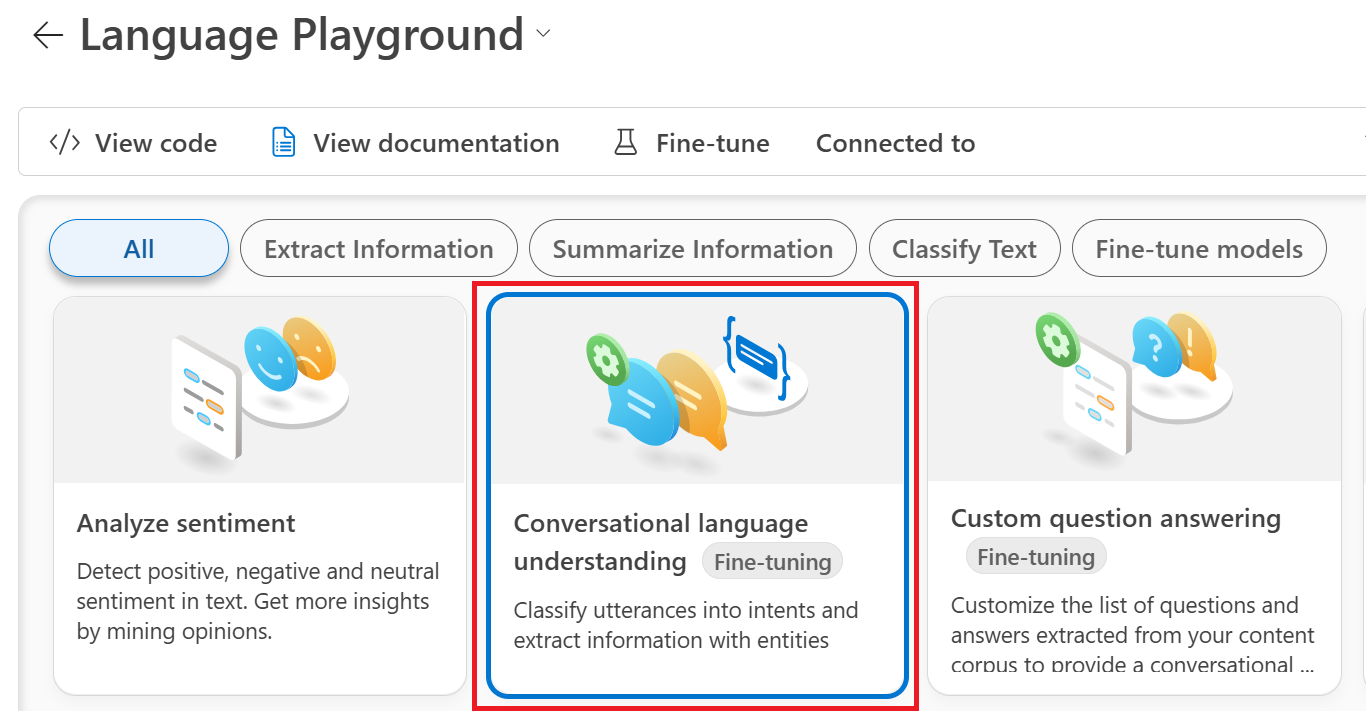
接下来,滚动至“微调”按钮处并选中该按钮。

从“创建服务微调”窗口中,选择“对话语言理解”卡片。 然后选择下一步。

在“创建 CLU 微调任务”窗口中,选择“导入现有项目”,然后从下拉菜单中选择“已连接的服务”,然后填写“名称”字段。

接下来,将之前下载的示例项目文件添加到上传区域。
选择“创建”按钮。 创建操作可能需要几分钟才能完成。
创建微调任务项目后,系统将打开“微调入门”页面。


训练模型
项目创建就绪后,后续步骤是架构构造和言语标记。 对于此快速入门,这些步骤已在示例项目中预先配置。 因此,可以从“入门”菜单中选择“训练模型”以生成模型,从而继续操作并启动训练作业。

从“训练模型”窗口中选择“➕训练模型”按钮。

填写“选择模式”表单,方法是填写“模型名称”字段并选择“训练模式”。 在本快速入门中,请选择免费的“标准”训练模式。 有关更多信息,请参阅训练模式。
从下拉菜单中选择“训练版本”,然后选择“下一步”按钮。
在“审阅”窗口中检查所选内容,然后选择“创建”按钮

部署模型
一般情况下,在训练模型后,你会查看其评估详细信息。 对于本快速入门,只需部署模型并使其可用于在 Azure 语言场中进行测试,或者通过调用 预测 API。 但是,如果需要,可以花点时间从左侧菜单中选择“评估模型”,并浏览模型的深入遥测数据。 完成以下步骤,在 Foundry 中部署模型:
在左侧菜单中,选择“部署模型”。
接下来,从“部署模型”窗口中选择“➕部署已训练的模型”。

确保已选择“创建新部署”按钮。
填写“部署已训练的模型”窗口字段:
创建部署名称。
从“分配模型”下拉菜单中选择训练的模型。
从“订阅”下拉菜单中选择你的订阅。
从“区域”下拉菜单中选择一个区域。
从“资源”下拉菜单中选择一个资源。 资源必须位于同一部署区域中。

最后,选择“创建”按钮。 部署模型可能需要几分钟时间。
成功部署后,可以在“部署模型”页上查看模型的部署状态。 显示的到期日期表示部署模型将不再可用于预测任务的日期。 部署训练配置后,此日期通常为 18 个月。

从最左侧的菜单中,进入 Azure Language 测试区。
游乐场 → 语言实验环境(试用 Azure 语言实验环境)。选择对话语言理解卡片。
包含已部署模型的“配置”窗口应出现在主/中心窗口中。
在文本框中,输入要测试的语句。 例如,如果使用我们的示例项目应用程序来处理与电子邮件相关的言语,可以输入“Check email”。
输入测试文本后,选择“运行”按钮。
运行测试后,在结果中应会看到模型的响应。

可以使用文本或 JSON 格式视图查看结果。

完成了,恭喜!
在本快速入门中,你部署了一个 CLU 模型,并在 Foundry 语言场中对其进行了测试。 接下来,了解如何为应用程序和工作流创建自己的微调任务项目。
清理资源
如果不再需要项目,则可以将其从 Foundry 中删除。
导航到 Foundry 主页。 除非已完成此步骤且会话处于活动状态,否则请通过登录来启动身份验证过程。
从“继续使用 Foundry 构建”中选择要删除的项目
选择“管理中心”。
选择“删除项目”。

删除中心及其所有项目:
导航到“中心”部分的“概述”选项卡。

在右侧,选择“删除中心”。
该链接将打开 Azure 门户,你可以在那里删除该中心。

Prerequisites
- Azure 订阅 - 免费创建订阅。
从 Azure 门户创建新资源
登录到 Azure 门户 ,在 Foundry Tools 资源中创建新的 Azure 语言。
选择“创建新资源”。
在出现的窗口中,搜索 语言。
选择 创建。
创建包含以下信息的语言资源:
实例详细信息 所需的值 区域 语言资源支持的区域之一。 名称 语言资源所需的名称。 定价层 语言资源支持的定价层之一。
获取资源密钥和终结点
在 Azure 门户中,转到资源概述页面。
在左侧菜单中,选择“密钥和终结点”。 你需要 API 请求的端点和密钥。


导入新的 CLU 示例项目
创建语言资源后,请创建对话语言理解项目。 项目是一个工作区,用于基于你的数据构建自定义 ML 模型。 只有你和有权访问所用语言资源的其他人才能访问你的项目。
对于本快速入门,可以下载并导入此示例项目。 此项目可以基于用户输入预测所需的命令,例如:阅读电子邮件、删除电子邮件,以及将文档附加到电子邮件。
触发导入项目作业
使用以下 URL、标头和 JSON 正文提交 POST 请求,以导入项目。
请求 URL
创建 API 请求时,请使用以下 URL。 将占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写,必须与要导入的 JSON 文件中的项目名称匹配。 | EmailAppDemo |
{API-VERSION} |
要调用的 API 的版本 。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
Body
所发送的 JSON 正文类似于以下示例。 有关 JSON 对象的详细信息,请参阅 参考文档。
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Conversation",
"settings": {
"confidenceThreshold": 0.7
},
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Trying out CLU",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Conversation",
"intents": [
{
"category": "intent1"
},
{
"category": "intent2"
}
],
"entities": [
{
"category": "entity1"
}
],
"utterances": [
{
"text": "text1",
"dataset": "{DATASET}",
"intent": "intent1",
"entities": [
{
"category": "entity1",
"offset": 5,
"length": 5
}
]
},
{
"text": "text2",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"intent": "intent2",
"entities": []
}
]
}
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
{API-VERSION} |
要调用的 API 的版本 。 | 2023-04-01 |
|
projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | EmailAppDemo |
language |
{LANGUAGE-CODE} |
一个字符串,用于指定项目中所用语句的语言代码。 如果你的项目是多语言项目,请选择大多数话语 的语言代码 。 | en-us |
multilingual |
true |
一个布尔值,可用于在数据集中使用多种语言的文档。 部署模型后,可以使用任何 受支持的语言查询模型,包括训练文档中不包含的语言。 | true |
dataset |
{DATASET} |
有关如何将数据分割成测试集和训练集的信息,请参阅 在 Foundry 中标记语句。 此字段的可能值为 Train 和 Test。 |
Train |
成功请求后,API 响应包含 URL operation-location 标头,可用于检查导入作业的状态。 标头的格式如下例所示:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
获取导入作业状态
发送成功的项目导入请求后,用于检查导入作业状态的完整请求 URL(包括终结点、项目名称和作业 ID)会包含在响应的 operation-location 标头中。
使用以下 GET 请求来查询导入作业的状态。 可以使用在上一步中收到的 URL,或者将占位符值替换为自己的值。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
{JOB-ID} |
用于查找导入作业状态的 ID。 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 说明 | 值 |
|---|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 | {YOUR-PRIMARY-RESOURCE-KEY} |
响应正文
发送请求后,会收到以下响应。 继续轮询此终结点,直到状态参数更改为“成功”。
{
"jobId": "xxxxx-xxxxx-xxxx-xxxxx",
"createdDateTime": "2022-04-18T15:17:20Z",
"lastUpdatedDateTime": "2022-04-18T15:17:22Z",
"expirationDateTime": "2022-04-25T15:17:20Z",
"status": "succeeded"
}
开始训练模型
通常,在创建项目后,应该生成架构并标记语句。 对于本快速入门,我们已导入一个生成了架构和标记了语句的现成项目。
使用以下 URL、标头和 JSON 正文创建 POST 请求以提交训练作业。
请求 URL
创建 API 请求时,请使用以下 URL。 将占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | EmailApp |
{API-VERSION} |
要调用的 API 的版本。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
请求正文
在请求中使用以下对象。 训练完成后,模型将以用于 modelLabel 参数的值命名。
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
模型名称。 | Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
训练配置模型版本。 默认情况下将使用最新的模型版本。 | 2022-05-01 |
trainingMode |
{TRAINING-MODE} |
用于训练的训练模式。 支持的模式为“标准训练”(训练速度更快,但仅适用于英语)和“高级训练”(受其他语言和多语言项目的支持,但训练时间更长)。 详细了解训练模式。 | standard |
kind |
percentage |
拆分方法。 可能的值为 percentage 或 manual。 有关详细信息,请参阅如何训练模型。 |
percentage |
trainingSplitPercentage |
80 |
要包含在训练集中的已标记数据的百分比。 建议的值为 80。 |
80 |
testingSplitPercentage |
20 |
要包含在测试集中的已标记数据的百分比。 建议的值为 20。 |
20 |
注意
仅当 trainingSplitPercentage 设置为 testingSplitPercentage 时 Kind 和 percentage 才是必需的,并且两个百分比的总和应等于 100。
发送 API 请求后,会收到指示 202 成功的响应。 在响应标头中,提取 operation-location 格式如下的值:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
可以使用此 URL 获取训练作业状态。
获取训练作业状态
训练可能需要一段时间才能完成 - 有时在 10 到 30 分钟之间。 可以使用以下请求继续轮询训练作业的状态,直到成功完成。
发送成功的训练请求后,用于检查作业状态的完整请求 URL(包括终结点、项目名称和作业 ID)会包含在响应的 operation-location 标头中。
使用以下 GET 请求来获取模型训练过程的状态。 将占位符值替换为你自己的值。
请求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{YOUR-ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | EmailApp |
{JOB-ID} |
用于查找模型训练状态的 ID。 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
响应正文
发送请求后,会收到以下响应。 继续轮询此终结点,直到“状态”参数变为“已成功”。
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| 密钥 | 值 | 示例 |
|---|---|---|
modelLabel |
模型名称 | Model1 |
trainingConfigVersion |
训练配置版本。 默认情况下将使用最新版本。 | 2022-05-01 |
trainingMode |
你选择的训练模式。 | standard |
startDateTime |
开始训练的时间 | 2022-04-14T10:23:04.2598544Z |
status |
训练作业的状态 | running |
estimatedEndDateTime |
预计的训练作业完成时间 | 2022-04-14T10:29:38.2598544Z |
jobId |
训练作业 ID | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
训练作业创建日期和时间 | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
训练作业上次更新日期和时间 | 2022-04-14T10:23:45Z |
expirationDateTime |
训练作业过期日期和时间 | 2022-04-14T10:22:42Z |
部署模型
一般情况下,在训练模型后,你会查看其评估详细信息。 在本快速入门中,你会部署模型,并调用预测 API 来查询结果。
提交部署作业
使用以下 URL、标头和 JSON 正文创建 PUT 请求,开始部署对话语言理解模型。
请求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
{DEPLOYMENT-NAME} |
部署名称。 此值区分大小写。 | staging |
{API-VERSION} |
要调用的 API 的版本。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
请求正文
{
"trainedModelLabel": "{MODEL-NAME}",
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
分配给您部署的模型名称。 只能分配已成功训练的模型。 此值区分大小写。 | myModel |
发送 API 请求后,会收到指示 202 成功的响应。 在响应标头中,提取 operation-location 格式如下的值:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
可使用此 URL 获取部署作业状态。
获取部署作业状态
发送成功的部署请求后,用于检查作业状态的完整请求 URL(包括终结点、项目名称和作业 ID)会包含在响应的 operation-location 标头中。
使用以下 GET 请求来获取部署作业的状态。 将占位符值替换为你自己的值。
请求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
{DEPLOYMENT-NAME} |
部署名称。 此值区分大小写。 | staging |
{JOB-ID} |
用于查找模型训练状态的 ID。 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
响应正文
发送请求后,你将获取以下响应。 继续轮询此终结点,直到“状态”参数变为“已成功”。
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
查询模型
部署模型后,可以开始使用该模型通过预测 API 进行预测。
部署成功后,可以开始查询已部署的模型以进行预测。
使用以下 URL、标头和 JSON 正文创建 POST 请求,以开始测试对话语言理解模型。
请求 URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
要调用的 API 的版本。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
请求正文
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
participantId |
{JOB-NAME} |
"MyJobName |
|
id |
{JOB-NAME} |
"MyJobName |
|
text |
{TEST-UTTERANCE} |
你要预测其意向并从中提取实体的语句。 | "Read Matt's email |
projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
deploymentName |
{DEPLOYMENT-NAME} |
部署的名称。 此值区分大小写。 | staging |
发送请求后,你会收到以下预测响应
响应正文
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| 密钥 | 示例值 | 说明 |
|---|---|---|
| 查询 | 阅读马特的电子邮件 | 提交以供查询的文本。 |
| topIntent | "Read" | 置信度分数最高的预测意向。 |
| 意向 | [] | 针对查询文本所预测的所有意向的列表,每个意向有一个置信度分数。 |
| 实体 | [] | 一个数组,包含从查询文本中提取的实体列表。 |
会话项目的 API 响应
在会话项目中,你将获得对项目中的意图和实体的预测。
- 意图和实体包括一个介于 0.0 到 1.0 之间的置信度分数,该分数与模型对于预测项目中某个元素的信心程度相关。
- 评分最高的意图包含在其自己的参数内。
- 仅有预测的实体会出现在您的响应中。
- 实体指示:
- 提取的实体的文本
- 用偏移值表示的开始位置
- 用长度值表示的实体文本的长度。
清理资源
如果你不再需要项目,可以使用 API 删除该项目。
使用以下 URL、标头和 JSON 正文创建 DELETE 请求,以删除对话语言理解项目。
请求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
{API-VERSION} |
要调用的 API 的版本 。 | 2023-04-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
发送 API 请求后,会收到指示 202 成功(这意味着项目已删除)的响应。