你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Microsoft Fabric
Azure 数据工厂
组织通常需要以各种格式从多个源收集数据,并将其移动到一个或多个数据存储。 目标可能不是与源相同的数据存储类型,并且数据通常需要在加载之前进行形状、清理或转换。
各种工具、服务和流程有助于应对这些挑战。 无论采用哪种方法,都需要协调工作并在数据管道中应用数据转换。 以下部分重点介绍了这些任务的常见方法和做法。
提取、转换、加载 (ETL) 过程
提取、转换、加载(ETL)是一个数据集成过程,可将来自不同源的数据合并到统一数据存储中。 在转换阶段,使用专用引擎根据业务规则修改数据。 这通常涉及临时保存数据的暂存表,因为它被处理,并最终加载到其目标。

数据转换通常涉及到各种操作,例如筛选、排序、聚合、联接数据、清理数据、删除重复数据和验证数据。
通常,三个 ETL 阶段并行运行,以节省时间。 例如,在提取数据时,转换过程可以处理已收到并准备加载的数据,加载过程可以开始处理已准备的数据,而不是等待整个提取过程完成。 通常围绕数据分区边界(日期、租户、分片键)设计并行化,以避免写入争用并启用幂等重试。
相关服务:
其他工具:
提取、加载、转换 (ELT)
提取、加载、转换 (ELT) 与 ETL 的唯一不同之处在于转换的发生位置。 在 ELT 管道中,转换发生在目标数据存储中。 在不使用单独转换引擎的情况下,将使用目标数据存储的处理功能来转换数据。 这就从管道中删除了转换引擎,从而简化了体系结构。 此方法的另一个好处是,缩放目标数据存储也会缩放 ELT 管道性能。 但是,仅当目标系统足够强大,可以有效转换数据时,ELT 才能正常工作。

ELT 的典型用例属于大数据领域。 例如,可以首先将源数据提取到可缩放存储中的平面文件,例如 Hadoop 分布式文件系统(HDFS)、Azure Blob 存储或 Azure Data Lake Storage Gen2。 然后,可以使用 Spark、Hive 或 PolyBase 等技术来查询源数据。 ELT 的关键之处在于,用于执行转换的数据存储是最终要在其中使用数据的同一数据存储。 此数据存储直接从可缩放存储中读取数据,而不是将数据加载到其自己的独立存储中。 此方法跳过 ETL 中存在的数据复制步骤,这对于大型数据集来说通常很耗时。 某些工作负荷具体化转换后的表或视图以提高查询性能或强制实施治理规则;ELT 并不总是暗示纯粹虚拟化的转换。
ELT 管道的最后阶段通常将源数据转换为对需要支持的查询类型更高效的格式。 例如,数据可能按常用的筛选键进行分区。 ELT 还可以使用优化的存储格式(如 Parquet),这是按列组织数据的列式存储格式,以启用压缩、 谓词下推和高效的分析扫描。
相关Microsoft服务:
选择 ETL 或 ELT
这些方法之间的选择取决于你的要求。
在以下情况下选择 ETL:
- 需要从受约束的目标系统卸载大量转换
- 复杂的业务规则需要专用转换引擎
- 在加载之前,法规或符合性要求要求要求强制进行暂存审核
在以下情况下选择 ELT:
- 目标系统是具有弹性计算缩放的新式数据仓库或 Lakehouse
- 需要保留原始数据,以便进行探索分析或将来的架构演变
- 转换逻辑受益于目标系统的本机功能
数据流和控制流
在数据管道的上下文中,控制流确保有序处理一组任务。 要实施这些任务的正确处理顺序,可以使用优先约束。 可以将这些约束视为工作流关系图中的连接器,如下图所示。 每个任务都有结果,例如成功、失败或完成。 任何后续任务都不会启动处理,直到其前置任务已完成其中一个结果。
控制流以任务的形式执行数据流。 在数据流任务中,会从源提取数据、转换数据,或将数据载入数据存储。 一个数据流任务的输出可以是下一个数据流任务的输入,数据流可以并行运行。 与控制流不同,无法在数据流中的任务之间添加约束。 但是,可以添加数据查看器来观察每个任务处理的数据。
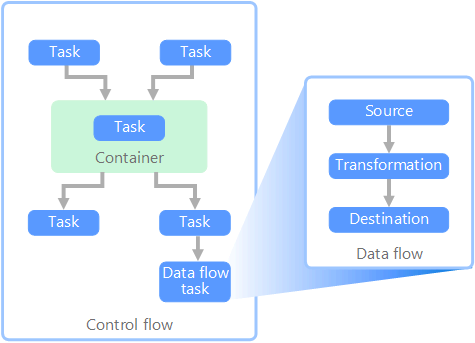
在关系图中,控制流中有多个任务,其中一个任务是数据流任务。 有一个任务嵌套在容器中。 可以使用容器来提供任务结构和工作单元。 一个例子是使用容器来重复集合中的元素,例如文件夹中的文件,或数据库语句。
相关服务:
反向 ETL
反向 ETL 是将转换的数据模型化数据从分析系统移动到作工具和应用程序的过程。 与传统的 ETL(将数据从作系统流向分析)不同,反向 ETL 通过将特选数据推送回业务用户可对其执行作来激活见解。 在反向 ETL 管道中,数据流从数据仓库、Lakehouses 或其他分析存储流向作系统,例如:
- 客户关系管理 (CRM) 平台
- 营销自动化工具
- 客户支持系统
- 工作负荷数据库
此方法仍遵循提取、转换和加载过程。 转换步骤是从数据仓库或其他分析系统用来与目标系统保持一致的特定格式进行转换的位置。
有关示例 ,请参阅 Azure Cosmos DB for NoSQL 的反向提取、转换和加载(ETL )。
流数据和热路径体系结构
如果需要 Lambda 热路径或 Kappa 体系结构,可以在生成数据时订阅数据源。 与 ETL 或 ELT 不同,它在计划的批处理中对数据集进行作,实时流式处理在到达时处理数据,从而实现即时见解和作。

在流式处理体系结构中,数据从事件源引入消息代理或事件中心(例如 Azure 事件中心或 Kafka),然后由流处理器(例如 Fabric Real-Time Intelligence、Azure 流分析或 Apache Flink)进行处理。 在将结果路由到下游系统(如仪表板、警报或数据库)之前,处理器应用转换,例如筛选、聚合、扩充或联接引用数据(全部动态)。
此方法非常适合低延迟和持续更新至关重要的方案,例如:
- 监视异常的制造设备
- 检测金融交易中的欺诈行为
- 为物流或运营提供实时仪表板
- 基于传感器阈值触发警报
流式处理的可靠性注意事项
- 使用检查点保证至少处理一次并从故障中恢复
- 设计要幂等的转换来处理潜在的重复处理
- 实现延迟到达事件和无序处理的水印
- 对无法处理的消息使用死信队列
技术选择
数据存储:
管道和业务流程:
- 管道业务流程
- Microsoft结构数据工厂 (新式业务流程)
- Azure 数据工厂 (混合和非构造方案)
Lakehouse 和新式分析: