你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
数据管理登陆区域部署过程
数据平台运营团队负责部署数据管理登陆区域。 数据管理登陆区域应有自己的存储库由数据平台运营团队维护。
注意
在部署任何数据登陆区域之前创建和部署数据管理登陆区域。
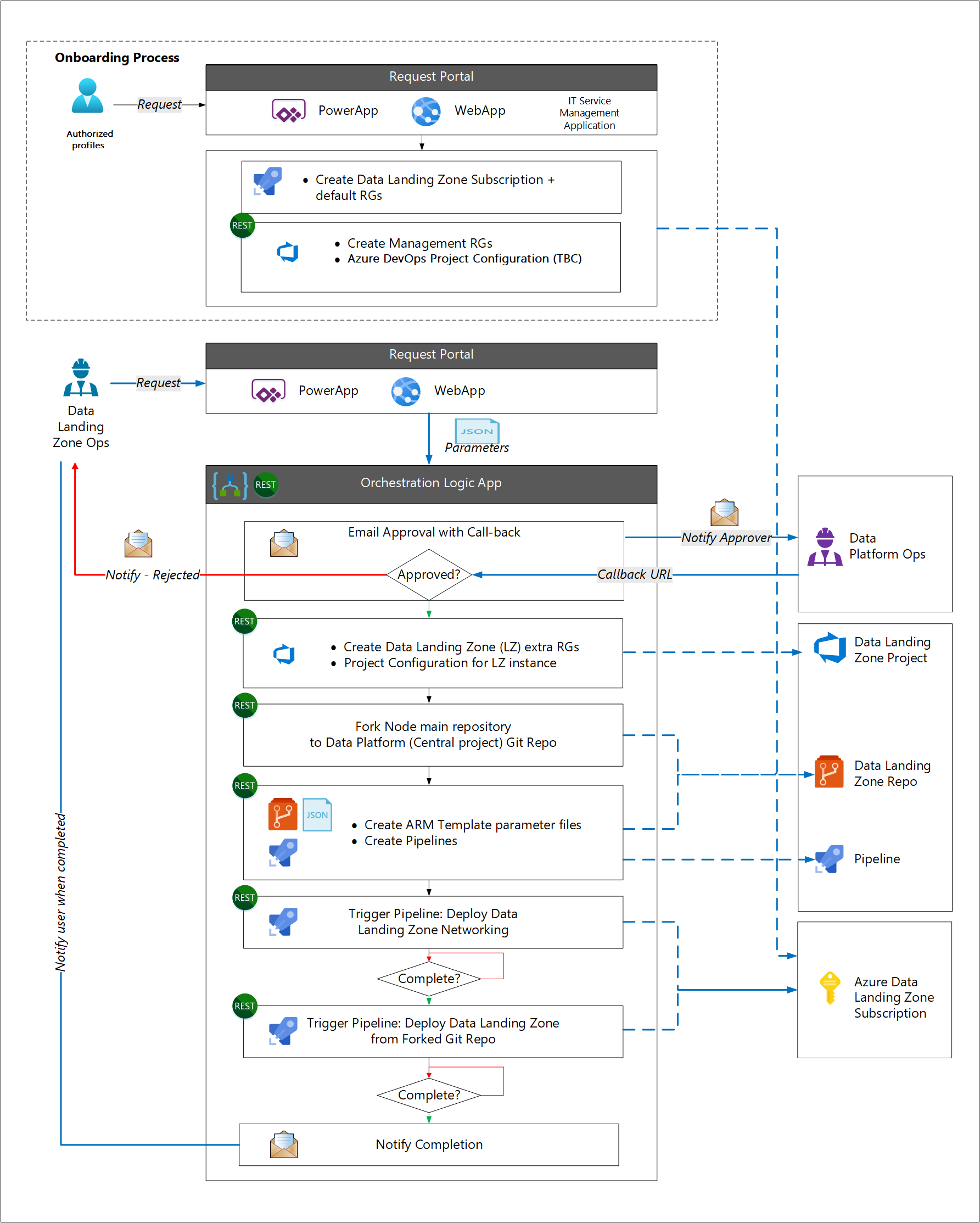
数据登陆区域部署过程
团队可以使用数据平台运营团队提供的模板,以避免每个资产从头开始。 建议使用分叉模式来自动部署新的登陆区域。
例如,数据登陆区域运营团队使用 IT 管理工具或 Power Apps 请求新的数据登陆区域。 批准请求后,使用请求中的参数启动以下工作流:
- 为新的数据落地区域部署新订阅。
- 从数据登陆区模板的主分支中分叉以创建新的存储库。
- 在新存储库中创建服务连接。
- 根据请求中的参数更新新存储库中的参数。
- 创建一个部署管道,用于在更新参数签入时触发服务的部署。
- 通知数据着陆区运营团队新的着陆区已可用。
数据登陆区域运营团队现在可以更改或添加 Azure 资源管理器模板。
可以在 Azure 平台上使用多个服务集自动执行此工作流。 使用 CI/CD 管道处理某些步骤,例如重命名参数文件中的参数。 可以使用其他工作流业务流程工具(如逻辑应用)执行其他步骤。

分叉模式允许团队从用于分叉的原始模板更新其模板。 此外,如果在模板存储库中实现了改进或新功能,运营团队可以将这些功能拉入其分支。
采用存储库的最佳做法,例如:
- 保护主分支。
- 采用分支来进行更改、更新和改进。
- 定义在将更改合并到主分支之前批准拉取请求的代码所有者。
- 通过自动测试验证分支。
- 限制团队中的操作和人员数,例如可以触发构建和发布管道的人员。
小窍门
协调团队之间的活动,以确保在所有数据登陆区域实例中复制原始模板中的改进或新功能。 运营团队可以将原始模板更改合并到其子项目中。
载入过程独立于数据登陆区域部署过程。 这种分离基于大多数组织在其云运营模型中具有标准 Azure 订阅部署过程的假设。 载入过程部署标准公司组件(如第三方 IT 服务管理工具)。 随后会部署数据登陆区相关的特定组件。
建议的自动化解决方案中没有可用于克隆/更新/提交/推送的 Git API。 因此,我们的方法是使用包含 PowerShell Runbook 的 Azure 自动化帐户 ,该帐户包括:
- 设置数据着陆区
- 将主存储库分支到数据平台 Git 存储库
- 为数据登陆区域设置子网配置
- 设置Microsoft Entra ID
运行簿使用 PowerShell 模块中的 GitAutomation Git 函数来处理 Git 存储库。 通过在 Azure 自动化帐户中安装此模块,用户可以在 Git 存储库中创建、克隆、查询、推送、拉取和提交作。 下图显示了 GitAutomation Azure 自动化帐户中安装的模块:

在模块GitAutomation中使用Copy-GitRepository函数,将主 Git 存储库从URL指定的 URL 克隆到DestinationPath指定的数据平台 Git 路径。
数据着陆区部署方法非常灵活,同时以确保其行为符合组织要求。 通过从原始模板应用新功能或优化来启用生命周期管理。
数据应用程序部署过程
创建数据登陆区域后,可以启动数据应用程序团队的载入。 数据平台或数据登陆区域运营团队授予部署批准。
部署是直接使用 DevOps 工具完成的,也可以通过公开为 API 的管道/工作流调用。 与数据着陆区类似,部署从分叉原始数据应用程序存储库开始。

- 用户向新数据应用程序服务发出请求。
- 工作流流程请求数据平台或数据登陆区域运营团队的批准。
- 工作流调用 IT 服务管理 API 来创建所需的资源组,并创建 Azure DevOps 服务连接。 工作流将团队分配到 Azure DevOps 项目。
- 工作流分叉原始数据应用程序存储库以创建目标 Azure DevOps 项目。
- 工作流创建 Azure 资源管理器模板参数文件和管道。
- 然后,工作流启动一个 Azure 管道来创建网络要求,另一个 Azure 管道用于部署数据应用程序服务。
- 工作流在完成时通知用户。
小窍门
如果您不熟悉 DataOps,请查看 Azure 架构中心提供的有关现代数据仓库的 DataOps 动手实验。 实验室的方案描述了一个虚构的城市规划办公室,该办公室可以使用此部署解决方案。 部署解决方案提供一个端到端的数据管道,该管道遵循现代数据仓库体系结构模式以及相应的 DevOps 和 DataOps 流程,以评估停车使用情况并做出明智的业务决策。
概要
上述模式提供策略的控制、敏捷性、自助服务和生命周期管理。

项目开始时,数据平台有一个包含一个或多个 Azure Boards 的 Azure DevOps 项目。 单个 DevOps 团队专注于:
- 一个用于数据管理着陆区、管道及云环境服务连接的存储库。
- 数据登陆区域的一个模板存储库、用于部署数据登陆区域实例的管道,以及与云环境的服务连接。
- 一个用于数据产品服务的模板存储库、用于部署数据产品实例的管道,以及与云环境的服务连接。 这些连接是从数据登陆区域 Azure DevOps Projects 分叉的。
部署数据着陆区后,云规模分析建议:
- 每个数据登陆区域将有自己的 Azure DevOps 项目,其中包含一个或多个 Azure Boards。
- 对于每个数据应用程序,在请求批准后会为其创建一个数据着陆区的 Azure DevOps 项目分支。
- 每个数据应用程序包括:
- 服务连接。
- 已注册的管道。
- 有权访问其 Azure 开发板和存储库的 DevOps 团队。
- 分支存储库的不同策略集。
若要控制数据应用程序的部署,请遵循以下做法:
- 数据登陆区域运营团队拥有和保护主存储库分支。
- 只有主分支用于部署到测试和生产环境。
- 功能分支可以部署到开发环境。
- 功能分支由 DataOps 团队拥有。 它们用于测试新功能或修改的功能。
- DataOps 团队可以在未经批准的情况下将功能分支合并到其他功能分支中。
- DataOps 团队创建合并请求,将功能分支合并到主分支,数据着陆区运营团队进行审批。
- 对原始模板的新功能或改进将合并到分叉存储库中,以使其保持更新。