可以在作业中将 dbt Core 项目作为任务运行。 通过将 dbt Core 项目作为作业任务运行,可以从以下 Lakeflow 作业功能中受益:
- 自动执行 dbt 任务并安排包含 dbt 任务的工作流。
- 监视 dbt 转换并发送有关转换状态的通知。
- 将 dbt 项目包含在具有其他任务的工作流中。 例如,工作流可以使用自动加载程序引入数据,使用 dbt 转换数据,并使用笔记本任务分析数据。
- 自动归档来自作业运行的项目,包括日志、结果、清单和配置。
要了解有关 dbt Core 的更多信息,请参阅 dbt 文档。
开发和生产工作流程
Databricks 建议针对 Databricks SQL 仓库开发 dbt 项目。 使用 Databricks SQL 仓库,可以测试 dbt 生成的 SQL,并使用 SQL 仓库查询历史来调试 dbt 生成的查询。
要在生产中运行 dbt 转换,Databricks 建议在 Databricks 作业中使用 dbt 任务。 默认情况下,dbt 任务将使用 Azure Databricks 计算和针对所选 SQL 仓库生成的 SQL 生成 SQL 来运行 dbt Python 进程。
可以在无服务器 SQL 仓库或 pro SQL 仓库、Azure Databricks 计算或任何其他 dbt 支持的仓库上运行 dbt 转换。 本文通过示例介绍前两个选项。
如果工作区启用了 Unity Catalog,并且启用了无服务器作业,则默认情况下作业会在无服务器计算上运行。
注意
针对 SQL 仓库开发 dbt 模型,并在 Azure Databricks 计算中运行它们可能会导致性能和 SQL 语言支持方面的细微差异。 Databricks 建议对计算和 SQL 仓库使用相同的 Databricks Runtime 版本。
要求
要了解如何使用 dbt Core 和
dbt-databricks包在开发环境中创建和运行 dbt 项目,请参阅连接到 dbt Core。Databricks 建议使用 dbt-databricks 包,而不是 dbt-spark 包。 dbt-databricks 包是针对 Databricks 优化的 dbt-spark 分支。
若要在 Azure Databricks 作业中使用 dbt 项目,必须设置 Azure Databricks Git 文件夹。 不能从 DBFS 运行 dbt 项目。
- 必须启用无服务器或专业版 SQL 仓库。
- 必须具有 Databricks SQL 权利。
创建并运行第一个 dbt 作业
以下示例使用 jaffle_shop 项目,这是一个演示核心 dbt 概念的示例项目。 若要创建运行煎饼商店项目的作业,请执行以下步骤。
在工作区中,单击
 ,然后在边栏中选择作业和管道。
,然后在边栏中选择作业和管道。单击创建,然后选择作业。
“ 任务 ”选项卡显示空任务窗格。
注意
如果 Lakeflow 作业 UI 为 ON,请单击 dbt 磁贴以配置第一个任务。 如果 dbt 磁贴不可用,请单击“ 添加其他任务类型 ”并搜索 dbt。
(可选)将默认为
New Job <date-time>作业名称的作业名称替换为作业名称。在“任务名称”中,输入任务的名称。
如有必要,请从“类型”下拉菜单中选择 dbt。
在 “源 ”下拉菜单中,选择 Git 提供程序 ,因为此示例使用 Git 存储库中的 jaffle 商店项目。
在 Project 目录中,输入 Git 存储库 URL:
https://github.com/dbt-labs/jaffle_shop.git。
在“dbt 命令”文本框中,指定要运行的 dbt 命令(deps、seed 和 run)。 这些应为默认值。 必须在每个命令前加上
dbt。 命令按指定顺序运行。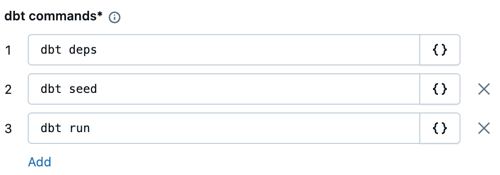
在“SQL 仓库”中,选择要运行 dbt 生成的 SQL 的 SQL 仓库。 “SQL 仓库”下拉菜单仅显示无服务器和专业 SQL 仓库。
(可选)可以为任务输出指定目录和架构。 默认情况下,
default使用目录和架构。(可选)如果要更改运行 dbt Core 的计算配置,请单击 dbt CLI 计算。 选择现有的计算选项,或单击“ 添加新作业群集 ”以创建新的作业群集。
在 “环境和库 ”下拉列表中,保持
dbt-default选中状态。单击“创建任务”。
要立即运行作业,请单击
 。
。
查看 dbt 作业任务的结果
作业完成后,可以通过从 笔记本 运行 SQL 查询或在 SQL 仓库中运行 查询 来测试结果。 例如,请参阅以下示例查询:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
将 <schema> 替换为任务配置中配置的架构名称。
API 示例
还可以使用 Jobs API 创建和管理包含 dbt 任务的作业。 以下示例使用单个 dbt 任务创建作业:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": ["dbt deps", "dbt seed", "dbt run"],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(高级)使用自定义配置文件运行 dbt
若要使用 SQL 仓库(建议)或全用途计算运行 dbt 任务,请使用自定义 profiles.yml 定义要连接到的仓库或 Azure Databricks 计算。 若要创建使用仓库或全用途计算运行 jaffle 商店项目的作业,请执行以下步骤。
注意
只能将 SQL 仓库或全用途计算用作 dbt 任务的目标。 不能将作业计算用作 dbt 的目标。
创建 jaffle_shop 存储库的分支。
将分支的存储库克隆到桌面。 例如,可以运行以下命令:
git clone https://github.com/<username>/jaffle_shop.git将
<username>替换为 GitHub 句柄。在
profiles.yml目录中创建一个名为jaffle_shop的新文件,其中包含以下内容:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: '<schema>' host: '<http-host>' http_path: '<http-path>' token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- 将
<schema>替换为项目表的架构名称。 - 若要使用 SQL 仓库运行 dbt 任务,请将
<http-host>替换为 SQL 仓库的“连接详细信息”选项卡中的“服务器主机名”值。 若要使用全用途计算运行 dbt 任务,请将<http-host>替换为 Azure Databricks 计算的高级选项、JDBC/ODBC选项卡中的服务器主机名值。 - 若要使用 SQL 仓库运行 dbt 任务,请将
<http-path>替换为 SQL 仓库的“连接详细信息”选项卡中的“HTTP 路径”值。 若要使用全用途计算运行 dbt 任务,请将<http-path>替换为 Azure Databricks 计算的高级选项、JDBC/ODBC 选项卡中的 HTTP 路径值。
不要在文件中指定访问令牌等机密,因为稍后要将此文件签入源代码管理。 此文件使用 dbt 模板功能在运行时动态插入凭据。
注意
生成的凭据在运行持续时间内有效,有效期最长为 30 天,在运行完成后会自动撤销。
- 将
将此文件签入 Git 并将其推送到分支存储库。 例如,可以运行以下命令:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git push单击
,在 Databricks UI 边栏中找到 作业与流水线。选择 dbt 作业并单击“任务”选项卡。
在“源”中,单击“编辑”并输入分支煎饼商店 GitHub 存储库详细信息。
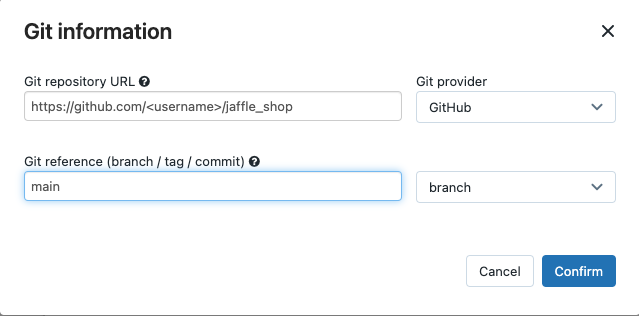
在“SQL 仓库”中,选择“无(手动)”。
在“配置文件目录”中,输入包含 文件的目录的相对路径。 将路径值留空以使用存储库根路径的默认值。
(高级)在工作流中使用 dbt Python 模型
注意
对 Python 模型的 dbt 支持以 beta 版本提供,需要 dbt 1.3 或更高版本。
dbt 现在支持特定数据仓库(包括 Databricks)上的 Python 模型。 借助 dbt Python 模型,可以使用 Python 生态系统中的工具实现难以用 SQL 实现的转换。 可以创建一个 Azure Databricks 作业,使用 dbt Python 模型运行单个任务,也可以将 dbt 任务纳入包含多个任务的工作流中。
不能在使用 SQL 仓库的 dbt 任务中运行 Python 模型。 有关将 dbt Python 模型与 Azure Databricks 配合使用的详细信息,请参阅 dbt 文档中的特定数据仓库。
错误和故障排除
“配置文件不存在错误”错误
错误消息:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
可能的原因:
在指定的 $PATH 中找不到 profiles.yml 文件。 确保 dbt 项目的根目录包含 profile.yml 文件。