本文介绍如何使用 Databricks 模型服务来创建为自定义模型提供服务的模型服务终结点。
该模型服务提供了下列用于为终结点创建提供服务的选项:
- 服务 UI
- REST API
- MLflow 部署 SDK
有关创建提供生成 AI 模型的终结点,请参阅 创建为终结点提供服务的基础模型。
要求
- 工作区必须位于受支持的区域。
- 如果将自定义库或来自专用镜像服务器的库与模型配合使用,请在创建模型终结点之前,参阅将自定义 Python 库与模型服务配合使用。
- 若要使用 MLflow 部署 SDK 创建这些终结点,必须安装 MLflow 部署客户端。 要安装它,请运行:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
访问控制
若要了解用于终结点管理的模型服务的终结点的访问控制选项,请参阅 管理模型服务终结点的权限。
模型服务终结点的运行身份与终结点的原始创建者相关联。 创建终结点后,无法在终结点上更改或更新关联的标识。 此标识及其关联权限用于访问用于部署的 Unity 目录资源。 如果标识没有访问所需 Unity 目录资源的相应权限,则必须删除终结点,并在可访问这些 Unity 目录资源的用户或服务主体下重新创建该终结点。
还可以添加环境变量来存储模型服务的凭据。 请参阅配置从模型服务终结点对资源的访问权限
创建终结点
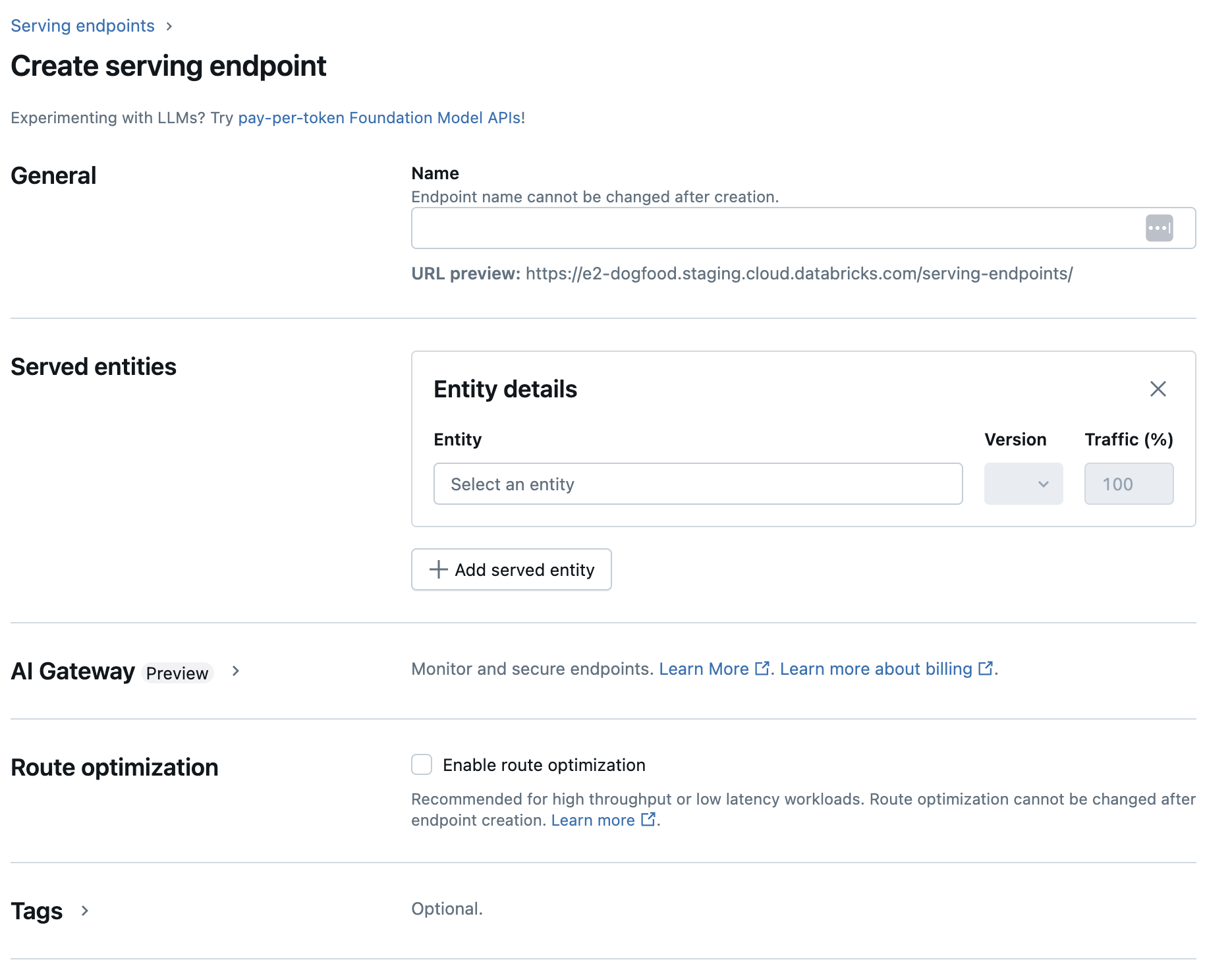
服务 UI
可以使用服务 UI 为模型服务创建终结点。
单击边栏中的“服务”以显示服务 UI。
单击“创建服务终结点”。

对于在工作区模型注册表中注册的模型,或 Unity 目录中的模型:
在“名称”字段中,提供终结点的名称。
- 终结点名称不能使用
databricks-前缀。 此前缀是为 Databricks 预配置终结点保留的。
- 终结点名称不能使用
在“服务的实体”部分中
- 单击“实体”字段以打开“选择服务的实体”窗体。
- 根据模型注册位置选择 “我的模型-Unity 目录 ”或 “我的模型-模型注册表 ”。 窗体会根据所选内容动态更新。
- 选择要服务的模型和模型版本。
- 选择要路由到服务的模型的流量百分比。
- 选择要使用的计算大小。 可以将 CPU 或 GPU 计算用于工作负荷。 有关可用 GPU 计算的详细信息,请参阅 GPU 工作负载类型。
- 在 “计算横向扩展”下,选择与此服务模型可以同时处理的请求数相对应的计算横向扩展的大小。 此数字应大致等于 QPS x 模型运行时。 有关客户定义的计算设置,请参阅 模型服务限制。
- 可用大小包括:小(适用于 0-4 个请求)、中(适用于 8-16 个请求)、大(适用于 16-64 个请求)。
- 指明终结点是否应在不使用时缩放为零。 不建议将生产端点缩放到零,因为一旦缩放到零,容量无法得到保证。 当终结点缩放到零时,当终结点纵向扩展以处理请求时,还会有额外的延迟(也称为冷启动)。
- 在 “高级配置”下,可以:
- 重命名服务实体以自定义它在终结点中的显示方式。
- 添加环境变量以 从端点连接到资源,或将你的功能查找数据帧记录到端点的推理表。 要记录特征查找数据帧,需要 MLflow 2.14.0 或更高版本。
- (可选)若要将其他服务实体添加到终结点,请单击“ 添加服务实体 ”并重复上述配置步骤。 可以从单个终结点为多个模型或模型版本提供服务,并控制它们之间的流量拆分。 有关详细信息,请参阅 提供多个模型 。
在 “路由优化 ”部分中,可以为终结点启用路由优化。 建议对满足高 QPS 和吞吐量要求的终结点进行路由优化。 请参阅 在服务端点上进行路由优化。
在 “AI 网关 ”部分中,可以选择在终结点上启用哪些治理功能。 请参阅 Mosaic AI 网关简介。
单击 “创建” 。 此时将显示“服务终结点”页,其中“服务终结点状态”显示为“未就绪”。
REST API
可以使用 REST API 创建终结点。 有关终结点配置参数,请参阅 POST /api/2.0/serving-endpoints。
以下示例创建一个终结点,该终结点为 Unity Catalog 模型注册表中注册的 my-ads-model 模型的第三个版本提供服务。 若要从 Unity 目录指定模型,请提供完整的模型名称,包括父目录和架构, catalog.schema.example-model例如。 此示例使用自定义的并发,min_provisioned_concurrency 和 max_provisioned_concurrency。 并发值必须是 4 的倍数。
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
以下是示例响应。 终结点 config_update 的状态是 NOT_UPDATING 且服务模型处于 READY 状态。
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow 部署 SDK
MLflow 部署 提供用于创建、更新和删除任务的 API。 这些任务的 API 接受的参数与用于提供终结点的 REST API 相同。 有关终结点配置参数,请参阅 POST /api/2.0/serving-endpoints。
以下示例创建一个终结点,该终结点为 Unity Catalog 模型注册表中注册的 my-ads-model 模型的第三个版本提供服务。 必须提供完整的模型名称,包括父目录和架构, catalog.schema.example-model例如。 此示例使用自定义的并发,min_provisioned_concurrency 和 max_provisioned_concurrency。 并发值必须是 4 的倍数。
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
工作区客户端
以下示例演示如何使用 Databricks 工作区客户端 SDK 创建终结点。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
也可执行以下操作:
GPU 工作负载类型
GPU 部署与以下包版本兼容:
- PyTorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 及更高版本
以下示例演示如何使用不同的方法创建 GPU 终结点。
服务 UI
若要使用 服务 UI 为 GPU 工作负载配置终结点,请在创建终结点时从 “计算类型” 下拉列表中选择所需的 GPU 类型。 按照“ 创建终结点”中的相同步骤作,但选择 GPU 工作负荷类型而不是 CPU。
REST API
若要使用图形处理单元(GPU)部署模型,请在终结点配置中包含workload_type字段。
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
MLflow 部署 SDK
以下示例演示如何使用 MLflow 部署 SDK 创建 GPU 终结点。
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
工作区客户端
以下示例演示如何使用 Databricks 工作区客户端 SDK 创建 GPU 终结点。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
下表汇总了支持的可用 GPU 工作负荷类型。
| GPU 工作负载类型 | GPU 实例 | GPU 内存 |
|---|---|---|
GPU_SMALL |
1xT4 | 16GB |
GPU_LARGE |
1xA100 | 80GB |
GPU_LARGE_2 |
2xA100 | 160GB |
修改自定义模型终结点
启用自定义模型终结点后,可以根据需要更新计算配置。 如果需要模型的其他资源,此配置将尤其有用。 在为模型服务分配哪些资源方面,工作负载大小和计算配置起着关键作用。
在新配置准备就绪之前,旧配置会一直为预测流量提供服务。 正在进行更新时,无法进行其他更新。 但是,可以从服务 UI 取消正在进行的更新。
服务 UI
启用模型终结点后,选择 “编辑终结点 ”以修改终结点的计算配置。

可以更改终结点配置的大部分方面,但终结点名称和某些不可变属性除外。
可以通过在终结点的详细信息页上选择 “取消更新 ”来取消正在进行的配置更新。
REST API
下面是使用 REST API 的终结点配置更新示例。 请参阅 PUT /api/2.0/service-endpoints/{name}/config。
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow 部署 SDK
MLflow 部署 SDK 使用与 REST API 相同的参数,请参阅 PUT /api/2.0/service-endpoints/{name}/config 以获取请求和响应架构详细信息。
以下代码示例使用 Unity 目录模型注册表中的模型:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
为模型终结点评分
若要为模型评分,可以将请求发送到模型服务终结点。
- 请参阅查询自定义模型的服务终结点。
- 请参阅使用基础模型。
其他资源
- 管理模型服务终结点。
- Mosaic AI Model Serving 中的外部模型。
- 如果想要使用 Python,可以使用 Databricks 实时服务 Python SDK。
笔记本示例
以下笔记本包含可用于启动和运行模型服务终结点的不同 Databricks 注册模型。 有关其他示例,请参阅 教程:部署和查询自定义模型。
可以按照导入笔记本中的说明将模型示例导入工作区。 从其中一个示例中选择并创建模型后, 将其注册到 Unity 目录中,然后按照模型服务的 UI 工作流 步骤进行作。