你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文将引导你完成在 Azure 机器学习工作室中使用提示流的主要用户旅程。 了解如何在 Azure 机器学习工作区中启用提示流、创建和开发提示流、测试和评估流,然后将其部署到生产环境。
Prerequisites
- 一个 Azure 机器学习工作区。 工作区的默认存储必须是 Blob 类型。
- Azure OpenAI 帐户,或已有部署的 Azure OpenAI 连接。 有关详细信息,请参阅 使用 Azure OpenAI 创建资源并部署模型。
Note
如果要使用虚拟网络保护提示流,请遵循 工作区托管虚拟网络的安全提示流中的说明。
设置连接
连接有助于安全地存储和管理与大型语言模型(LLM)和其他外部工具(例如 Azure 内容安全)交互所需的机密密钥或其他敏感凭据。 连接资源与工作区中的所有成员共享。
Note
提示流中的 LLM 工具不支持推理模型(如 OpenAI o1 或 o3)。 为了推理模型的集成,使用 Python 工具直接调用模型 API。 有关详细信息,请参阅 从 Python 工具调用推理模型。
若要检查是否已建立 Azure OpenAI 连接,请从 Azure 机器学习工作室左侧菜单中选择“提示流”,然后选择“提示流”屏幕上的“连接”选项卡。

如果已看到其提供程序为 AzureOpenAI 的连接,则可以跳过此设置过程的其余部分。 请注意,此连接必须有一个部署,以便能够在示例流程中运行 LLM 节点。 有关详细信息,请参阅 部署模型。
如果没有 Azure OpenAI 连接,请选择“ 创建 ”,然后从下拉菜单中选择 “AzureOpenAI ”。
在 “添加 Azure OpenAI 连接 ”窗格中,提供连接的名称,选择 订阅 ID 和 Azure OpenAI 帐户名称,并提供 身份验证模式 和 API 信息。
提示流支持 Azure OpenAI 资源的 API 密钥 或 Microsoft Entra ID 身份验证。 对于本教程,请在身份验证模式下选择 API 密钥。
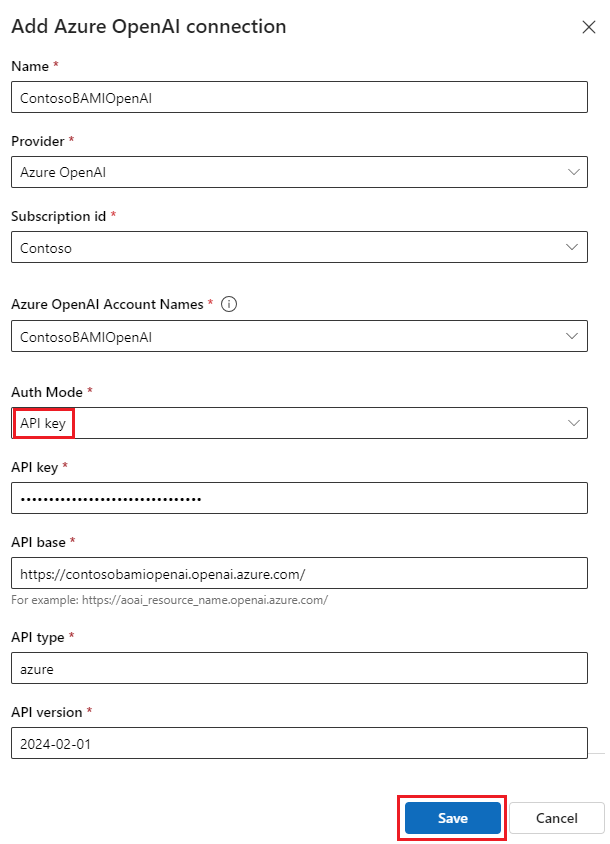
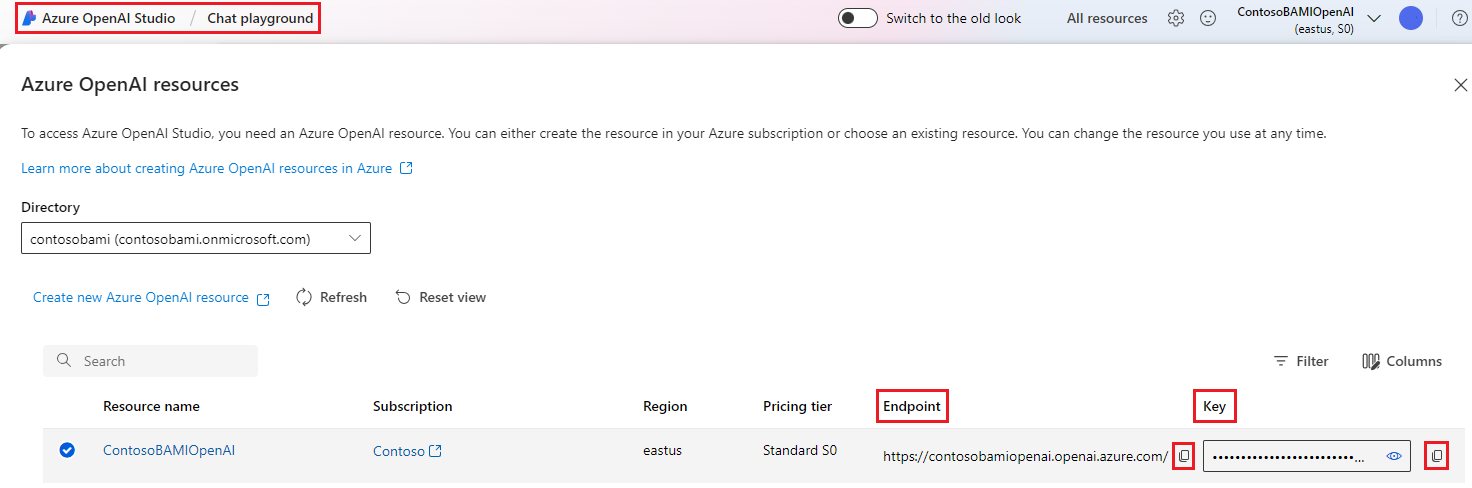
若要获取 API 信息,请转到 Azure OpenAI 门户中的 聊天场 并选择 Azure OpenAI 资源名称。 复制密钥并将其粘贴到“添加 Azure OpenAI 连接”窗体中的 API 密钥字段中,复制终结点并将其粘贴到表单中的 API 基字段。
有关 Microsoft Entra ID 身份验证的信息,请参阅 如何使用 Microsoft Entra ID 身份验证在 Microsoft Foundry 模型中配置 Azure OpenAI。
填写所有字段后,选择“ 保存 ”以创建连接。
连接必须与部署相关联,然后才能在示例流中运行 LLM 节点。 若要创建部署,请参阅 “部署模型”。



创建和开发提示流
在提示流主页的“流”选项卡中,选择“创建”以创建提示流。 “创建新流”页显示可以创建的流类型、可以克隆以创建流的内置示例,以及导入流的方法。
从样本中克隆
在 “探索图库” 中,你可以浏览内置示例,并选择任何磁贴上的 “View detail” 以预览它是否适合你的场景。
本教程使用 Web 分类 示例演练主要用户旅程。 Web 分类是使用 LLM 演示多类分类的流。 给定 URL 后,流只需几个镜头、简单的摘要和分类提示即可将 URL 分类到 Web 类别。 例如,给定 URL https://www.imdb.com,它将 URL 分类为 Movie。
若要克隆示例,请在Web 分类磁贴上选择克隆。

“克隆流”窗格显示将流存储在工作区文件共享存储中的位置。 如果需要,可以自定义文件夹。 然后选择“克隆”。
克隆的流将在创作用户界面中打开。 可以选择 “编辑 铅笔”图标来编辑流详细信息,例如名称、说明和标记。
启动计算会话
流执行需要使用计算会话。 计算会话管理运行应用程序所需的计算资源,例如包含所有必要的依赖项包的 Docker 映像。
在流创作页上,通过选择“启动计算会话”来开始计算会话。

检查工作流程编辑页
计算会话可能需要几分钟才能启动。 在计算会话启动时,查看流创作页的各个部分。
页面左侧的 Flow 或 平展 视图是主要工作区,可以通过添加或删除节点、编辑和运行内联节点或编辑提示来创作流。 在“输入”和“输出”部分,可以查看、添加或删除以及编辑输入和输出。
克隆当前 Web 分类示例时,已设置输入和输出。 流的输入架构是
name: url; type: string字符串类型的 URL。 可以将预设输入值更改为其他值,例如https://www.imdb.com手动。右上角的“文件”显示流的文件夹和文件结构。 每个流文件夹都包含 flow.dag.yaml 文件、源代码文件和系统文件夹。 可以创建、上传或下载用于测试、部署或协作的文件。
右下角的 图形 视图用于可视化流的外观。 可以放大或缩小,或使用自动布局。
可以在“流”或平展视图中内联编辑文件,也可打开“原始文件模式”切换按钮,并从“文件”中选择一个文件,在选项卡中打开该文件进行编辑。

对于此示例,输入是一个要分类的 URL。 该流使用 Python 脚本从 URL 中提取文本内容,使用 LLM 以 100 个单词汇总文本内容,并根据 URL 和汇总的文本内容进行分类。 然后,Python 脚本将 LLM 输出转换为字典。 prepare_examples节点向分类节点的提示提供几个示例镜头。
设置 LLM 节点
对于每个 LLM 节点,需要选择一个 连接 来设置 LLM API 密钥。 选择 Azure OpenAI 连接。
根据连接类型,必须从下拉列表中选择 deployment_name 或模型。 对于 Azure OpenAI 连接,请选择部署。 如果您没有部署,请按照在 Azure OpenAI 门户中部署模型的说明创建一个部署。
Note
如果使用 OpenAI 连接而不是 Azure OpenAI 连接,则需要在 “连接” 字段中选择模型而不是部署。
对于此示例,请确保 API 类型为 聊天,因为提供的提示示例适用于聊天 API。 有关聊天 API 与完成 API 之间的差异的详细信息,请参阅 “开发流”。

为流中的两个 LLM 节点设置连接, summarize_text_content 和 classify_with_llm。
运行单个节点
若要测试和调试单个节点,请选择流视图中节点顶部的“运行”图标。 可以展开 “输入 ”并更改流输入 URL 以测试不同 URL 的节点行为。
运行状态显示在节点顶部。 运行完成后,“ 输出 ”部分会显示运行输出。

Graph 视图还显示单个运行节点状态。
运行 fetch_text_content_from_url ,然后运行 summarize_text_content 以检查流是否可以从 Web 成功提取内容并汇总 Web 内容。
运行整个流
若要测试和调试整个流,请选择屏幕顶部的 “运行 ”。 可以更改流输入 URL 以测试流对不同 URL 的行为方式。

检查每个节点的运行状态和输出。
查看流输出
还可以设置流输出来检查多个节点的输出。 流输出可帮助你:
- 在单个表中检查批量测试结果。
- 定义评估接口映射。
- 设置部署响应架构。
在克隆的示例中,类别 和 证据 的流式输出已设置。
选择顶部横幅或顶部菜单栏中的“查看输出”,查看详细的输入、输出、流执行和业务流程信息。

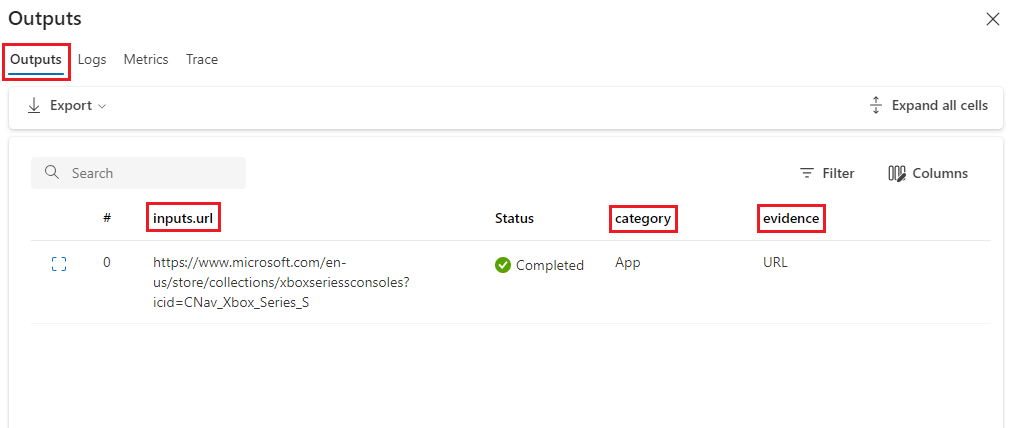
在“输出”屏幕的“输出”选项卡上,请注意,流可以根据类别和证据预测输入 URL。
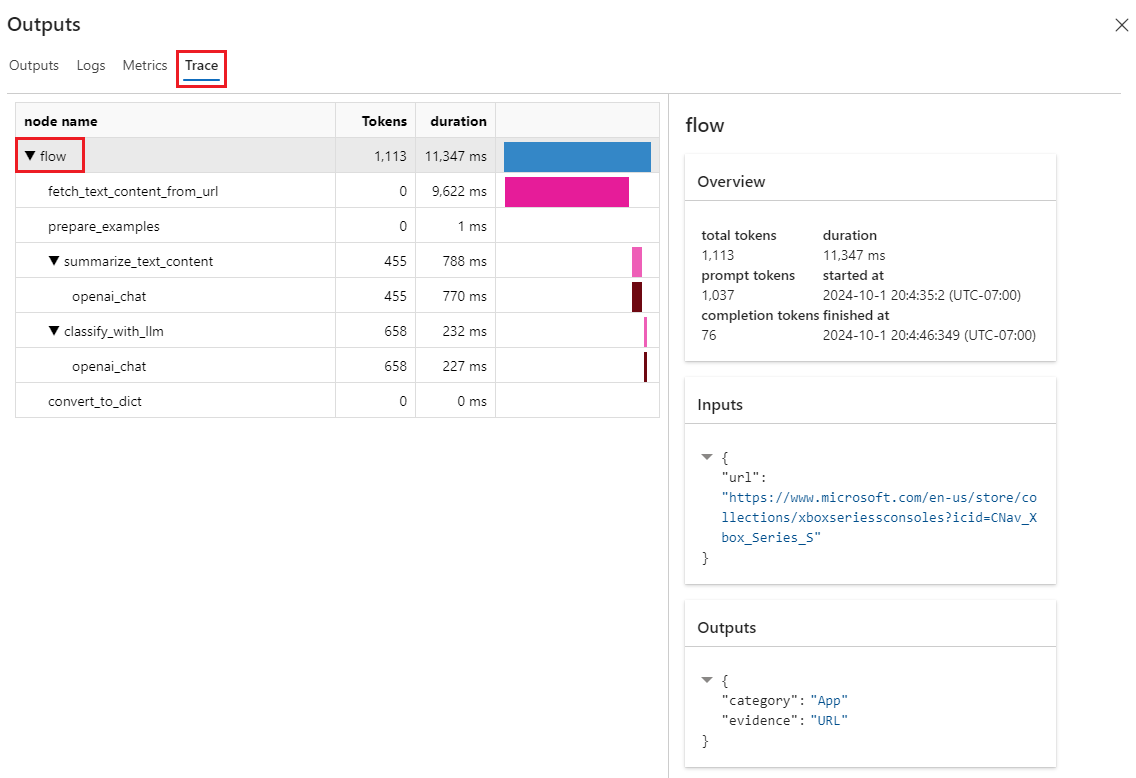
在“输出”屏幕上选择“跟踪”选项卡,然后在节点名称下选择流以查看右侧窗格中的详细流概述信息。 展开流并选择任意步骤以查看该步骤的详细信息。



测试和评估
在流使用单行数据成功运行后,测试它在大量数据下的表现。 可以运行批量测试并选择性地添加评估流,然后检查结果。
首先需要准备测试数据。 Azure 机器学习支持用于数据的 CSV、TSV 和 JSONL 文件格式。
- 转到 GitHub 并下载 web 分类示例的黄金数据集 data.csv。
使用 批量运行和评估 向导来配置和提交批量运行,也可以选择评估方法。 评估方法也是流,它们使用 Python 或 LLM 来计算准确性和相关性分数等指标。
从流创作页面的顶部菜单中选择“ 评估 ”。
在 “基本设置” 屏幕上,根据需要更改 “运行”显示名称 ,添加可选的 “运行说明 ”和“ 标记”,然后选择“ 下一步”。
在 “Batch 运行设置” 屏幕上,选择“ 添加新数据”。 在 添加数据 屏幕上,输入数据集的 名称,选择 浏览 以上传您下载的 data.csv 文件,然后选择 添加。
上传数据后,或者工作区具有要使用的另一个数据集,请从下拉列表中搜索并选择数据集,以预览前五行。
输入映射功能支持将流输入映射到数据集中的任何数据列,即使列名不匹配也是如此。
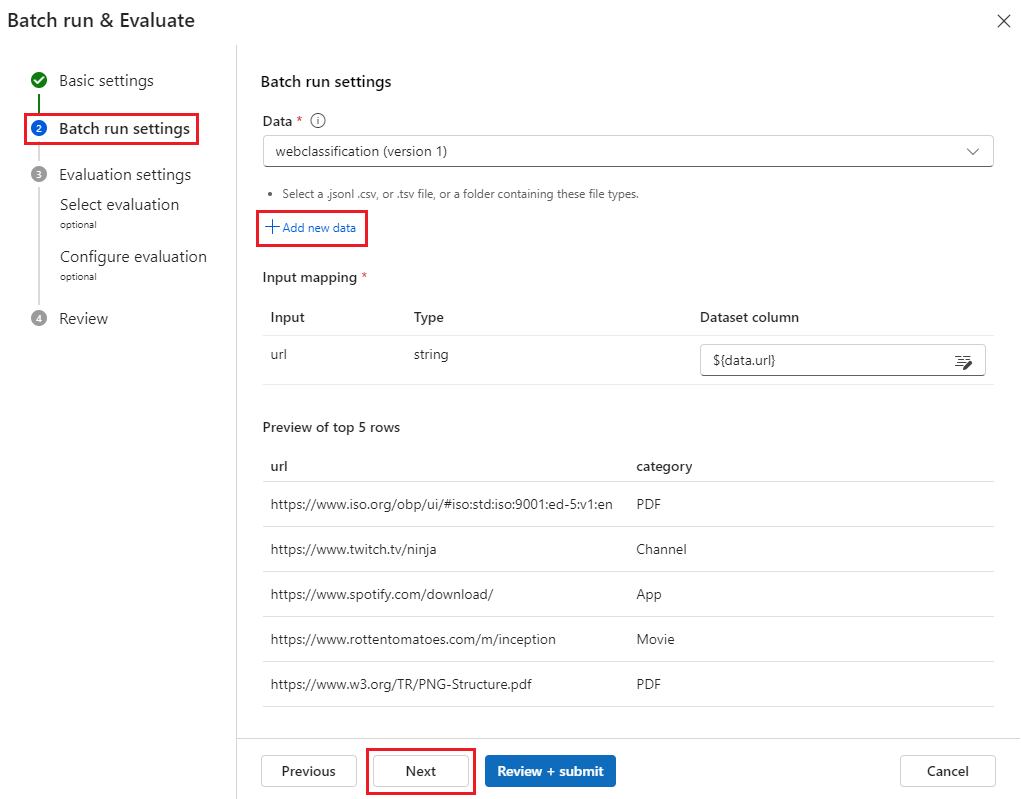
选择“ 下一步 ”可选择选择一个或多个评估方法。 “选择评估”页显示内置和自定义的评估流。 若要查看为内置评估方法定义指标的方式,您可以在方法的图块中选择更多详细信息。
Web 分类是一种分类方案,因此请选择“ 分类准确性评估 ”以用于评估,然后选择“ 下一步”。

在“配置评估”屏幕上,将评估输入映射设置为将 groundtruth 映射到流程输入 ${data.category} 并将 预测 映射到流程输出 ${run.outputs.category}。

选择 “查看 + 提交 ”,然后选择“ 提交 ”以提交批处理运行和所选评估方法。



检查结果
成功提交运行后,选择“ 查看运行列表 ”以查看提示流 运行 页上的运行状态。 批处理运行可能需要一段时间才能完成。 可以选择“ 刷新 ”以加载最新状态。
批处理运行完成后,选择运行旁的复选框,然后选择“可视化输出”以查看批处理运行的结果。

在 “可视化输出 ”屏幕上,启用子运行旁边的眼睛图标,将评估结果追加到批处理运行结果表中。 可以看到令牌总数和总体准确性。 “ 输出 ”表显示每行数据的结果:输入、流输出、系统指标和 正确 或 不正确的评估结果。

在 “输出 ”表中,可以:
- 调整列宽、隐藏或取消隐藏列或更改列顺序。
- 选择导出以将当前页面下载为CSV文件,或将数据导出脚本下载为可以运行的Jupyter笔记本文件来在本地下载输出。
- 选择任意行旁边的 “视图详细信息 ”图标,打开 “跟踪”视图 ,显示该行的完整详细信息。
准确性不是唯一可以评估分类任务的指标。 例如,还可以使用召回率进行评估。 若要运行其他评估,请选择“运行”页上可视化输出旁边的“评估”,然后选择其他评估方法。
部署为端点
生成并测试流后,可以将其部署为终结点,以便可以调用终结点进行实时推理。
配置终结点
在“批处理 运行 ”页上,选择运行名称链接,然后在运行详细信息页上,选择顶部菜单栏上的“ 部署 ”以打开部署向导。
在“基本设置”页上,指定终结点名称和部署名称,然后选择虚拟机类型和实例计数。
可以选择“ 下一步 ”以配置高级 终结点、 部署和 输出和连接 设置。 对于此示例,请使用默认设置。
选择 “查看 + 创建 ”,然后选择“ 创建 ”以启动部署。
测试终结点
可以从通知转到终结点详细信息页,也可以通过在工作室左侧导航中选择 “终结点 ”并从 “实时终结点 ”选项卡中选择终结点。部署终结点需要几分钟时间。 成功部署终结点后,可以在 “测试 ”选项卡中对其进行测试。
在输入框中放置要测试的 URL,然后选择“ 测试”。 你可以看到由您的终结点预测的结果。
清理资源
若要节省计算资源和成本,如果现已使用完计算会话,则可以停止计算会话。 选择正在运行的会话,然后选择“ 停止计算会话”。
还可以通过从工作室左侧导航中选择 “计算” 、在 “计算实例”列表中选择计算实例 ,然后选择“ 停止”来停止计算实例。
如果不打算使用在本教程中创建的任何资源,可以将其删除,以免产生费用。 在 Azure 门户中,搜索并选择“资源组”。 从列表中选择包含所创建资源的资源组,然后从资源组页上的顶部菜单中选择 “删除资源组 ”。