Plumsail 文档
Plumsail Documents 连接器允许设置自动化文档生成和转换。 连接器提供了各种作来作 PDF 文档和 PDF 表单。 从模板创建文档、转换为 PDF、拆分和合并 PDF 文件、保护文档、阅读 PDF 表单等 - 只需在一个连接器中自动执行文档。 有关详细信息,请参阅 https://plumsail.com/documents
此连接器在以下产品和区域中可用:
| 服务 | Class | 区域 |
|---|---|---|
| Copilot Studio | 标准 | 除以下各项外的所有 Power Automate 区域 : - 美国政府 (GCC High) - 由世纪互联运营的中国云 - 美国国防部(DoD) |
| 逻辑应用程序 | 标准 | 除以下各项外的所有 逻辑应用区域 : - Azure 中国区域 - 美国国防部(DoD) |
| Power Apps | 标准 | 除以下各项外的所有 Power Apps 区域 : - 美国政府 (GCC High) - 由世纪互联运营的中国云 - 美国国防部(DoD) |
| Power Automate | 标准 | 除以下各项外的所有 Power Automate 区域 : - 美国政府 (GCC High) - 由世纪互联运营的中国云 - 美国国防部(DoD) |
| 联系人 | |
|---|---|
| Name | Support |
| URL | https://plumsail.com |
| support@plumsail.com |
| 连接器元数据 | |
|---|---|
| 发布者 | Plumsail |
| Website | https://plumsail.com |
| 隐私策略 | https://plumsail.com/privacy-policy/ |
| 类别 | 生产力;内容和文件 |
在 Microsoft Power Automate、Azure 逻辑应用或 PowerApps 中生成文档
注册帐户
首先,需要 注册 Plumsail 帐户。 此帐户用于管理 Plumsail 文档、Plumsail Actions 和 Plumsail Forms 产品。
最好使用活动电子邮件地址。 订阅将链接到此地址。
如果已有帐户,只需登录 account.plumsail.com。
生成 API 密钥
需要导航到“API 密钥”部分,然后单击“添加新”。
创建 API 密钥后,可以在“机密”列中看到密钥。 还可以通过在“名称”列中单击键的名称来更改键的名称:
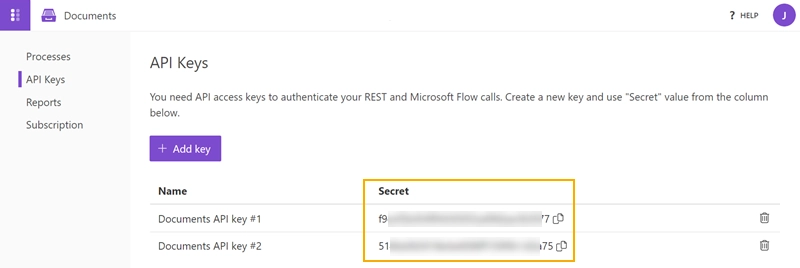
根据需要创建任意数量的密钥,例如,用于不同的 Power Automate (Microsoft Flow) 帐户。 如果不再需要密钥,可以将其删除,请确保不再使用该密钥。
现在,可以在以下环境中复制并使用它:
正在创建连接
连接器支持以下身份验证类型:
| 默认 | 用于创建连接的参数。 | 所有区域 | 可共享 |
违约
适用:所有区域
用于创建连接的参数。
这是可共享的连接。 如果 Power App 与其他用户共享,则连接也会共享。 有关详细信息,请参阅 画布应用的连接器概述 - Power Apps |Microsoft Docs
| Name | 类型 | Description | 必选 |
|---|---|---|---|
| API 密钥 | securestring | 在 account.plumsail.com 中创建 API 密钥 | True |
| 数据中心位置 | 字符串 |
限制
| 名称 | 调用 | 续订期 |
|---|---|---|
| 每个连接的 API 调用数 | 1200 | 60 秒 |
操作
Merge Docx
Merge Docx 采用 Docx 文档数组并将其合并到单个文件中。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#merge-docx
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
Content
|
documentsContents | True | array of binary |
Docx 文档的原始内容数组 |
|
应用页眉和页脚
|
applyHeaderAndFooter | True | boolean |
将第一个文档中的页眉和页脚应用于所有其他文档 |
返回
从 DOCX 模板创建文档
从 DOCX 模板创建文档。 详细信息:https://plumsail.com/docs/documents/v1.x/document-generation/docx/index.html
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
模板文件
|
documentContent | True | binary |
模板的内容 |
|
模板数据
|
data | True | object |
应用于模板的 JSON 数据 |
|
文档输出类型
|
outputType | True | string |
所需的文档类型 |
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
时区
|
timezone | string |
文档的时区 |
返回
- 结果文件
- binary
从 PDF 文档中提取文本
从 PDF 中提取文本采用 PDF 文档,并将文本提取为原始格式或 HTML 格式。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#extract-text-from-pdf-document
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
起始页
|
startPage | integer |
开始提取的第一页(基于 1) |
|
|
结束页
|
endPage | integer |
要提取的最后一页(含) |
|
|
结果类型
|
resultType | string |
原始或 HTML |
|
|
密码
|
password | string |
解密文档的密码 |
返回
从 PDF 获取表单
从 PDF 获取表单以 JSON 形式从 PDF 返回可填充的表单数据。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#get-form-from-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
密码
|
password | string |
解密文档的密码 |
返回
- response
- object
从 PPTX 模板创建文档
从 PPTX 模板创建文档。 详细信息:https://plumsail.com/docs/documents/v1.x/document-generation/pptx/index.html
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
模板文件
|
documentContent | True | binary |
模板的内容 |
|
模板数据
|
data | True | object |
应用于模板的 JSON 数据 |
|
文档输出类型
|
outputType | True | string |
所需的文档类型 |
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
时区
|
timezone | string |
文档的时区 |
返回
从 XLSX 模板创建文档
从 XLSX 模板创建文档。 详细信息:https://plumsail.com/docs/documents/v1.x/document-generation/xlsx/index.html
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
模板文件
|
documentContent | True | binary |
模板的内容 |
|
模板数据
|
data | True | object |
应用于模板的 JSON 数据 |
|
文档输出类型
|
outputType | True | string |
所需的文档类型 |
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
时区
|
timezone | string |
文档的时区 |
返回
- 结果文件
- binary
从模板创建 HTML
创建 HTML 采用输入 HTML 模板字符串或文件,并将特殊 {{Tokens}} 替换为指定的数据。 我们在内部对模板使用 Mustache 框架。 有关 Mustache 文档中的模板的详细信息: http://mustache.github.io/mustache.5.html. 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#create-html-from-template
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
源 HTML
|
html | True | byte |
文本 HTML 模板或 HTML 文件模板 |
|
模板数据
|
data | True | object |
应用于模板的 JSON 数据 |
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
时区
|
timezone | string |
文档的时区 |
返回
使用 json 启动文档生成过程
启动文档生成过程使用 JSON 数据填充与所选进程相关的 DOCX、XLSX、PPTX 或 PDF 模板。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html##start-process-json
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
进程名
|
processId | True | string |
要启动的进程的名称 |
|
|
object |
返回
- 结果文件
- binary
保护 PDF 文档
保护 PDF 文档将密码、复制、打印和其他保护添加到 PDF 文件。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#protect-pdf-document
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
启用打印
|
allowPrinting | True | boolean |
保护 PDF 文件不被打印出来 |
|
启用修改
|
allowModification | True | boolean |
保护 PDF 文件不被编辑 |
|
启用提取数据
|
allowExtract | True | boolean |
允许从 PDF 文件提取文本、图像和其他媒体 |
|
启用批注
|
allowAnnotate | True | boolean |
允许批注(例如批注、表单填写、签名)PDF 文件 |
|
PDF 所有者密码
|
newOwnerPassword | string |
在此处输入可选所有者密码。 此密码可用于禁用文档限制 |
|
|
PDF 用户密码
|
newUserPassword | string |
在此处输入可选用户密码。 每次用户打开 PDF 时,都会要求他输入此密码。 如果不希望输入密码提示,请将此字段留空 |
|
|
密码
|
password | string |
解密文档的密码 |
返回
分析 CSV
分析 CSV 的工作方式类似于分析 JSON,但适用于 CSV 文件。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#parse-csv
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
CSV 文档的内容
|
content | True | byte |
CSV 文档的内容 |
|
分隔符
|
delimiter | string |
列的分隔符(默认情况下只是逗号) |
|
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
限度
|
limit | integer |
返回第一个“n”行 |
|
|
Headers
|
headers | True | string |
以与 CSV 列相同的顺序分隔标头列表 |
|
跳过第一行
|
skipFirstLine | boolean |
如果 CSV 具有头作为第一行,请选择“是”。 |
返回
创建存档
压缩文件并将其添加到 ZIP 存档。
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文件名
|
fileName | True | string |
没有文件扩展名的存档的名称 |
|
文件名
|
fileName | string |
文件名(包括文件扩展名) |
|
|
文件内容
|
content | binary |
文档的内容 |
|
|
密码
|
password | string |
存档密码 |
返回
压缩 PDF 文档
如果可能,请压缩 PDF 文档大小并对其进行优化。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#compress-pdf-document
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
密码
|
password | string |
打开 PDF 文件的密码 |
返回
- 结果文件
- binary
合并 PDF
合并 PDF 采用 PDF 文档数组并将其合并为一个。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#merge-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
Content
|
documentsContents | True | array of binary |
PDF 文档的原始内容数组 |
返回
- 结果文件
- binary
合并 Xlsx
合并 Xlsx 采用 Xlsx 文档数组并将其合并到单个文件中。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#merge-xlsx
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
Content
|
documentsContents | True | array of binary |
Xlsx 文档的原始内容数组 |
返回
向 PDF 添加水印
将水印作为文本、图像或 PDF 添加到 PDF。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#add-watermark-to-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
类型
|
type | True | string |
水印的类型 |
|
申请
|
request | True | dynamic |
返回
启动文档生成过程
启动文档生成过程使用 JSON 数据填充与所选进程相关的 DOCX、XLSX、PPTX 或 PDF 模板。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#start-document-generation-process
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
进程名
|
processId | True | string |
要启动的进程的名称 |
|
数据
|
data | True | dynamic |
返回
- 结果文件
- binary
在 DOCX 文档中填充合并字段
在 DOCX 文档中填充合并字段使用包含合并字段的 DOCX 文档,并用指定数据替换它们。 数据对象中的键应与文档中 MergeFields(Express 块)的名称相同。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#fill-merge-fields-in-docx-document
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
DOCX 文档内容
|
docxDocument | True | byte |
docx 文档模板的原始内容。 MergeField 名称应与模板数据中的键相同 |
|
模板数据
|
data | True | object |
应用于模板的 JSON 数据 |
返回
填写 PDF 表单
填写 PDF 表单,填写提供的数据的 PDF。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#fill-in-pdf-form
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
JSON 数据
|
jsonData | True | object |
将用于填写表单的数据 |
|
锁定窗体字段
|
lockFormFields | boolean |
在填写字段后禁用字段编辑 |
|
|
密码
|
password | string |
打开 PDF 文件的密码 |
返回
将 CSV 转换为 Excel
将 CSV 转换为 Excel 文件(XLSX)。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#csv-to-excel
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
CSV 文档的内容
|
content | True | byte |
CSV 文档的内容 |
|
分隔符
|
delimiter | string |
列的分隔符(默认情况下只是逗号) |
|
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
限度
|
limit | integer |
返回第一个“n”行 |
|
|
使用第一行作为标题
|
hasHeaderRecords | boolean |
如果设置为“是”,则将从第一行读取标头。 |
|
|
CSV 列名称或索引
|
csvColumnIndexOrName | True | string |
CSV 列名或列索引(1、2 等) |
|
XLSX 列类型
|
xlsxColumnType | string |
可选。 列类型(ShortDateTime、TwoDecimal 等) |
|
|
XLSX 列名称
|
xlsxColumnName | string |
可选。 将 CSV 列重命名为此名称 |
返回
- 结果文件
- binary
将 DOC 转换为 DOCX
将 DOC 转换为 DOCX 文件。 此作采用 DOC 文档并将其转换为 DOCX。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-doc-to-docx
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
应转换的文档的内容 |
返回
- 结果文件
- binary
将 DOCX 转换为 PDF
将 DOCX 转换为 PDF 文件。 此作采用 DOCX 文档并将其转换为 PDF。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-docx-to-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
应转换的文档的内容 |
返回
将 HTML 转换为 DOCX
将 HTML 转换为 DOCX 文档。 此作采用 HTML 标记,将其呈现并转换为 DOCX 文档。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-html-to-docx
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文件内容
|
fileContent | binary |
要转换为 DOCX 的 HTML 文件的二进制内容 |
|
|
HTML 数据
|
rawHtml | string |
要转换为 DOCX 的 HTML 数据 |
|
|
HTML URL
|
htmlUrl | string |
要转换为 DOCX 的网页的 URL |
|
|
纸张大小
|
paperSize | string |
可以是 A4、A5 等... |
|
|
方向
|
orientation | string |
纵向或横向 |
|
|
解码 HTML
|
decodeHtml | boolean |
是否应在转换之前解码 HTML |
|
|
边距
|
margins | string |
pt 中的页边距。 语法与 CSS 中的语法相同。 示例:25 50 75 100。 |
返回
将 HTML 转换为 PDF
将 HTML 转换为 PDF 文件。 此作采用 HTML 标记,呈现并转换为 PDF 文档。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-html-to-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
源 HTML
|
html | True | string |
应转换为 PDF 的 HTML 标记 |
|
Engine
|
engine | string |
转换引擎 |
|
|
纸张大小
|
size | string |
可以是 A4、A5 等... |
|
|
方向
|
orientation | string |
纵向或横向 |
|
|
边距
|
margins | string |
页边距。 语法与 CSS 中的语法相同。 示例:25 50 75 100。 |
|
|
标头 HTML
|
headerHtml | string |
仅经典引擎 - 应添加为标头的 HTML 标记 |
|
|
页脚 HTML
|
footerHtml | string |
仅经典引擎 - 应添加为页脚的 HTML 标记 |
返回
将 JSON 转换为 CSV
将 JSON 转换为 CSV 文件。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#json-to-csv
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
JSON 文件内容
|
content | byte |
可选。 JSON 文件的内容 |
|
|
JSON 数据
|
jsonData | string |
可选。 要处理的 JSON 数据 |
|
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
JSON 数组的路径
|
pathToJsonArray | string |
JSON 中数组的点分隔路径。 例如:“data”或“prop1.prop2.prop3” |
|
|
分隔符
|
delimiter | string |
CSV 中列的分隔符。 默认值为逗号 |
返回
- 结果文件
- binary
将 JSON 转换为 Excel
将 JSON 转换为 Excel 文件(XLSX)。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#json-to-excel
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
JSON 文件内容
|
content | byte |
可选。 JSON 文件的内容 |
|
|
JSON 数据
|
jsonData | string |
可选。 要处理的 JSON 数据 |
|
|
区域设置
|
locale | string |
将应用于文档的区域设置 |
|
|
JSON 数组的路径
|
pathToJsonArray | string |
JSON 中数组的点分隔路径。 例如:“data”或“prop1.prop2.prop3” |
|
|
JSON 属性
|
jsonProperty | True | string |
JSON 属性的名称 |
|
XLSX 列类型
|
xlsxColumnType | string |
可选。 列类型(ShortDateTime、TwoDecimal 等) |
|
|
XLSX 列名称
|
xlsxColumnName | string |
可选。 将 JSON 属性重命名为此名称 |
返回
- 结果文件
- binary
将 PDF 转换为图像
将 PDF 转换为图像。 此作采用 PDF 文档并将其转换为图像(jpeg、png、gif、bmp 等)。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-pdf-to-image
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
文件名前缀
|
filenamePrefix | string |
可选。 输出文件将具有此前缀,后跟名称的索引号 |
|
|
起始页
|
startPage | integer |
开始提取的第一页(基于 1) |
|
|
结束页
|
endPage | integer |
要提取的最后一页(含) |
|
|
页
|
pages | string |
用于提取的页码,用“;”分隔(仅提取此页) |
|
|
图像格式
|
format | string |
结果图像的格式 |
|
|
DPI
|
dpi | integer |
结果图像的分辨率 |
|
|
密码
|
password | string |
解密文档的密码 |
返回
将 PDF 转换为图像 (已弃用) [已弃用]
此作已弃用。 请改用 “将 PDF 转换为图像 ”。
将 PDF 转换为图像。 此作采用 PDF 文档并将其转换为图像(jpeg、png、gif、bmp 等)。 文档 - https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-pdf-to-image (已弃用)
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
起始页
|
startPage | integer |
开始提取的第一页(基于 1) |
|
|
结束页
|
endPage | integer |
要提取的最后一页(含) |
|
|
页
|
pages | string |
用于提取的页码,用“;”分隔(仅提取此页) |
|
|
图像格式
|
format | string |
结果图像的格式 |
|
|
DPI
|
dpi | integer |
结果图像的分辨率 |
|
|
密码
|
password | string |
解密文档的密码 |
返回
将 PPT 转换为 PPTX
将 PPT 转换为 PPTX 文件。 此作采用 PPT 文档并将其转换为 PPTX。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-ppt-to-pptx
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
应转换的文档的内容 |
返回
- 结果文件
- binary
将 PPTX 转换为 PDF
将 PPTX 转换为 PDF 文件。 此作采用 PPTX 文档并将其转换为 PDF。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-pptx-to-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
应转换的文档的内容 |
返回
- 结果文件
- binary
将 XLS 转换为 XLSX
将 XLS 转换为 XLSX 文件。 此作采用 XLS 文档并将其转换为 XLSX。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-xls-to-xlsx
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
应转换的文档的内容 |
返回
- 结果文件
- binary
将 XLSX 转换为 PDF
将 XLSX 转换为 PDF 文件。 此作采用 XLSX 文档并将其转换为 PDF。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#convert-xlsx-to-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
应转换的文档的内容 |
返回
- 结果文件
- binary
将图像转换为 PDF
它获取图像并将其转换为 PDF 文档
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
每页单个图像
|
imagePerPage | boolean |
如果不希望每个图像位于单独的页面上,请选择“否”。 默认值为“是” |
|
|
图像内容
|
imageContent | True | array of byte |
图像的原始内容 |
返回
- 结果文件
- binary
拆分 PDF
拆分 PDF 采用 PDF 文档并将其拆分。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#split-pdf
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
拆分类型
|
type | True | string |
如何拆分文件 |
|
申请
|
request | True | dynamic |
返回
拆分 PDF (已弃用) [已弃用]
此作已弃用。 请改用 拆分 PDF 。
它采用 PDF 文档并将其拆分(已弃用)
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
|
起始页
|
startPage | integer |
要开始拆分的第一页(基于 1) |
|
|
结束页
|
endPage | integer |
要拆分的最后一页(含) |
|
|
分页拆分
|
splitAtPage | integer |
每个分区的页数 |
|
|
密码
|
password | string |
解密文档的密码 |
返回
提取存档
从存档中提取文件。
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
存档 文件
|
fileContent | byte |
存档文件的内容 |
|
|
包括文件夹
|
includeFolders | boolean |
如果文件夹中包含的“true”文件将被提取 |
|
|
密码
|
password | string |
存档密码 |
返回
正则表达式匹配
正则表达式匹配搜索输入字符串,查找正则表达式的所有匹配项,并返回所有匹配项。 建议使用正则表达式 Hero 测试表达式。 它支持与作相同的语法。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#regular-expression-match
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
图案
|
pattern | True | string |
正则表达式模式 |
|
文本
|
text | True | string |
用于搜索匹配项的字符串 |
返回
正则表达式替换
正则表达式替换将匹配正则表达式模式的所有字符串替换为指定输入字符串中的指定替换字符串。 建议使用正则表达式 Hero 测试表达式。 它支持与作相同的语法。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#regular-expression-replace
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
图案
|
pattern | True | string |
正则表达式模式 |
|
文本
|
text | True | string |
用于搜索匹配项的字符串 |
|
Replacement
|
replacement | string |
替换字符串 |
返回
- Body
- StringResultResponse
正则表达式测试
正则表达式测试指示正则表达式在 Regex 构造函数中指定的正则表达式是否在指定的输入字符串中找到匹配项。 建议使用正则表达式 Hero 测试表达式。 它支持与作相同的语法。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#regular-expression-test
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
图案
|
pattern | True | string |
正则表达式模式 |
|
文本
|
text | True | string |
用于搜索匹配项的字符串 |
返回
获取有关 PDF 保护的信息
获取有关 PDF 保护的信息将返回文档是否受密码保护的信息。 文档- https://plumsail.com/docs/documents/v1.x/flow/actions/document-processing.html#get-pdf-protection-information
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
文档内容
|
documentContent | True | byte |
PDF 文档的原始内容 |
返回
获取配置文件信息
触发器
| 进程已完成 |
创建在进程完成时运行的 Webhook |
进程已完成
创建在进程完成时运行的 Webhook
参数
| 名称 | 密钥 | 必需 | 类型 | 说明 |
|---|---|---|---|---|
|
进程名
|
processId | True | string |
要启动的进程的名称 |
返回
定义
ApplyHtmlTemplateResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
结果 HTML
|
htmlResult | string |
原始 HTML 结果 |
BooleanResultResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
IsSuccess
|
isSuccess | boolean |
DocumentContentWithFilenameResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
Filename
|
filename | string |
文件的名称 |
|
文件内容
|
fileContent | byte |
文件内容 |
DocumentProcessingResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
结果文件
|
fileContent | byte |
作为文件的结果 |
DocumentsArrayResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
结果文件
|
resultFilesContents | array of byte |
结果文件的原始内容数组 |
DocumentsWithFilenamesResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
结果文件
|
resultFiles | array of DocumentContentWithFilenameResponse |
结果文件的原始内容数组及其文件名 |
GetPdfProtectionInfoResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
isPasswordProtected
|
isPasswordProtected | boolean |
LicenseInfo
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
类型
|
type | integer | |
|
积分
|
credits | integer | |
|
additionalCredits
|
additionalCredits | integer | |
|
到期日期
|
expirationDate | date-time |
ProfileInfo
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
姓名
|
name | string | |
|
电子邮件
|
string | ||
|
licenseStatus
|
licenseStatus | string | |
|
teamName
|
teamName | string | |
|
licenseInfo
|
licenseInfo | LicenseInfo | |
|
shortUserId
|
shortUserId | string |
StringResultResponse
| 名称 | 路径 | 类型 | 说明 |
|---|---|---|---|
|
结果
|
result | string |
二进制
这是基本数据类型“binary”。
对象
这是类型“object”。