了解如何使用 ML.NET 通过Microsoft自定义视觉服务中训练的 ONNX 模型检测图像中的对象。
Microsoft自定义视觉服务是一种 AI 服务,基于上传的图像训练模型。 然后,可以将模型导出为 ONNX 格式,并将其用于 ML.NET 进行预测。
本教程中,您将学习如何:
- 使用自定义视觉服务创建 ONNX 模型
- 将 ONNX 模型合并到 ML.NET 管道中
- 训练 ML.NET 模型
- 检测测试图像中的停止标志
先决条件
- Visual Studio 2022 或更高版本。
- 下载 50 个停止签名图像的数据集。
- Azure AD 帐户。 如果没有帐户, 请创建一个免费的 Azure 帐户。
创建模型
创建自定义视觉项目
登录到 Microsoft自定义视觉服务 并选择 “新建项目”。
在 “新建项目 ”对话框中,填写以下必需项:
- 将自定义视觉项目 的名称 设置为 StopSignDetection。
- 选择要使用的 资源 。 这是将为自定义视觉项目创建的 Azure 资源。 如果未列出,可以通过选择 “创建新 ”链接来创建一个。
- 将 项目类型 设置为 对象检测。
- 将 分类类型 设置为 多类 ,因为每个图像都有一个类。
- 将 域 设置为 “常规”(compact) [S1]。 压缩域允许下载 ONNX 模型。
- 对于 导出功能,请选择 “基本平台 ”以允许导出 ONNX 模型。
填写上述字段后,选择“ 创建项目”。
添加图像
- 创建项目后,选择 “添加图像 ”以开始添加要训练的模型的图像。 选择您下载的停车标志图像。
- 选择显示的第一个图像。 可以选择希望模型检测的图像中的对象。 选择映像中的停止登录。 弹出窗口显示并将标记设置为 停止标志。
- 对所有剩余图像重复此步骤。 某些图像具有多个停车标志,因此请务必标记图像中的所有停车标志。
训练模型
上传并标记图像后,现在可以训练模型。 选择“训练”。
此时会显示一个弹出窗口,询问要使用的训练类型。 选择 “快速训练 ”,然后选择“ 训练”。
下载 ONNX 模型
训练完成后,单击“ 导出 ”按钮。 当弹出窗口显示时,选择 ONNX 以下载 ONNX 模型。
检查 ONNX 模型
解压缩下载的 ONNX 文件。 该文件夹包含多个文件,但本教程中使用的两个文件如下:
- labels.txt,它是包含自定义视觉服务中定义的标签的文本文件。
- model.onnx,它是用于在 ML.NET 中进行预测的 ONNX 模型。
若要构建 ML.NET 管道,需要输入列和输出列的名称。 若要获取此信息,请使用 Netron(一个 Web 和 桌面 应用)来分析 ONNX 模型并显示其体系结构。
使用 Netron 的 Web 或桌面应用时,请在应用中打开 ONNX 模型。 打开后,它会显示一个图形。 此图提供了一些你需要知道的信息,以用于生成 ML.NET 预测管道。
输入列名称 - 在 ML.NET 中应用 ONNX 模型时所需的输入列名称。
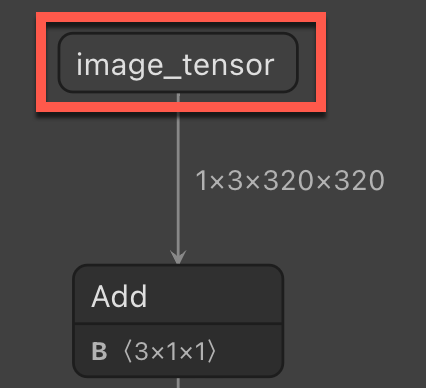
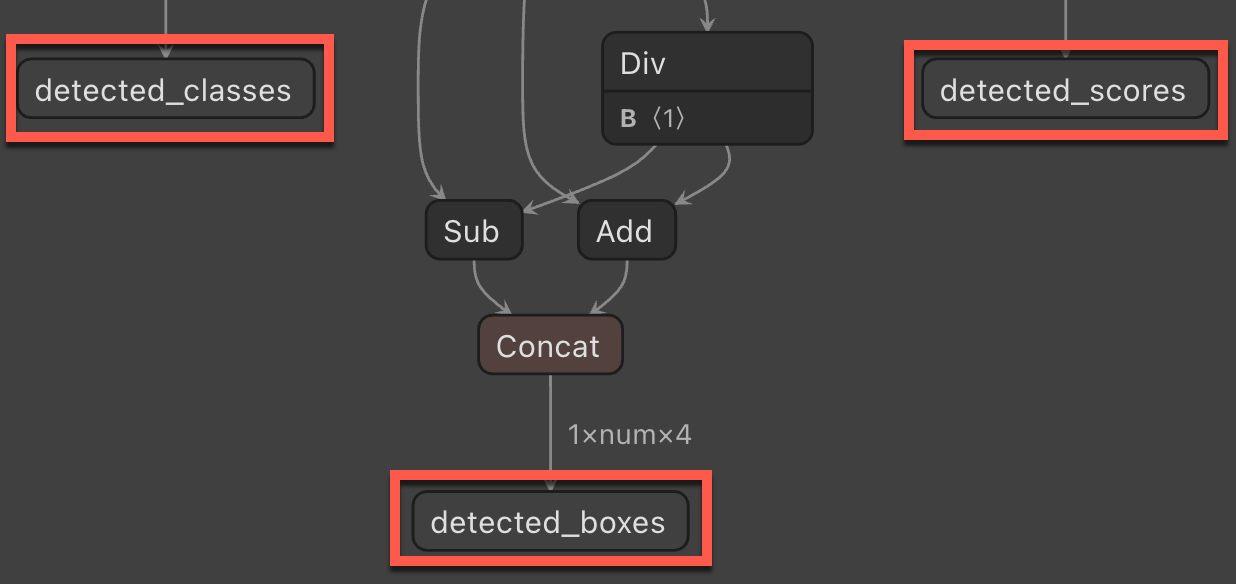
输出列名称 - 在 ML.NET 中应用 ONNX 模型时所需的输出列名称。
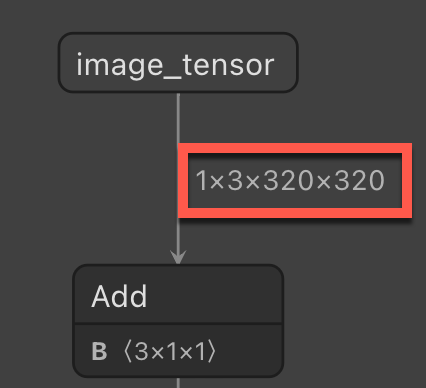
图像大小 - 在 ML.NET 管道中调整图像大小时所需的大小。
创建 C# 控制台项目
在 Visual Studio 中,创建一个名为“StopSignDetection”的 C# 控制台应用程序。 选择 .NET 8 作为目标框架。
为项目安装以下 NuGet 包:
- Microsoft.ML
- Microsoft.ML.ImageAnalytics
- Microsoft.Onnx.Transformer
注释
此示例使用提到的 NuGet 包的最新稳定版本,除非另有说明。
引用 ONNX 模型
在 Visual Studio 解决方案资源管理器中找到 ONNX 模型(labels.txt 和 model.onnx)中的两个文件。 右键单击它们,并在“属性”窗口中将“复制到输出目录”设置为“若有更新则复制”。
创建输入类和预测类
向项目添加新类并将其命名
StopSignInput。 然后,将以下结构添加到类:public struct ImageSettings { public const int imageHeight = 320; public const int imageWidth = 320; }接下来,将以下属性添加到类。
public class StopSignInput { [ImageType(ImageSettings.imageHeight, ImageSettings.imageWidth)] public Bitmap Image { get; set; } }该
Image属性包含用于预测的图像的位图。 该ImageType属性告诉 ML.NET,这是一个由 Netron 确定的尺寸为 320 x 320 的图像。向项目添加另一个类并将其命名
StopSignPrediction。 然后,将以下属性添加到类。public class StopSignPrediction { [ColumnName("detected_classes")] public long[] PredictedLabels { get; set; } [ColumnName("detected_boxes")] public float[] BoundingBoxes { get; set; } [ColumnName("detected_scores")] public float[] Scores { get; set; } }该
PredictedLabels属性包含每个检测到对象的标签预测。 该类型是浮点数组,因此数组中的每个项都是每个标签的预测。 该ColumnName属性告知 ML.NET 模型中的此列是给定的名称,即detected_classes。该
BoundingBoxes属性包含每个检测到的对象的边界框。 该类型是一个浮点数组,每个检测到的对象都附带了边界框的数组中的四个项。 该ColumnName属性告知 ML.NET 模型中的此列是给定的名称,即detected_boxes。该
Scores属性包含每个预测对象的置信度分数及其标签。 该类型是浮点数组,因此数组中的每个项都是每个标签的置信度分数。 该ColumnName属性告知 ML.NET 模型中的此列是给定的名称,即detected_scores。
使用模型进行预测
添加 using 指令
在 Program.cs 文件中,将以下 using 指令添加到文件顶部。
using Microsoft.ML;
using Microsoft.ML.Transforms.Image;
using System.Drawing;
using WeatherRecognition;
创建对象
MLContext创建对象。var context = new MLContext();使用新的空
IDataView列表创建一个StopSignInput。var data = context.Data.LoadFromEnumerable(new List<StopSignInput>());为了保持一致性,请将预测的图像保存到程序集路径。
var root = new FileInfo(typeof(Program).Assembly.Location); var assemblyFolderPath = root.Directory.FullName;
构建管道
创建空 IDataView 后,可以生成管道来预测任何新图像。 管道由几个步骤组成:
调整传入图像的大小。
要发送到模型进行预测的图像的纵横比通常与用于训练模型的图像不同。 若要使图像保持一致以便进行准确的预测,请将图像大小调整为 320x320。 为此,请使用
ResizeImages该方法并将该方法设置为imageColumnName属性的名称StopSignInput.Image。var pipeline = context.Transforms.ResizeImages(resizing: ImageResizingEstimator.ResizingKind.Fill, outputColumnName: "image_tensor", imageWidth: ImageSettings.imageWidth, imageHeight: ImageSettings.imageHeight, inputColumnName: nameof(StopSignInput.Image))提取图像的像素。
调整图像大小后,需要提取图像的像素。 将
ExtractPixels方法追加到管道中,并指定列的名称,以使用参数输出像素outputColumnName。.Append(context.Transforms.ExtractPixels(outputColumnName: "image_tensor"))将 ONNX 模型应用于图像进行预测。 这需要几个参数:
- modelFile - ONNX 模型文件的路径
- outputColumnNames - 包含所有输出列名称的名称的字符串数组,可在 Netron 中分析 ONNX 模型时找到这些名称。
- inputColumnNames - 包含所有输入列名称的名称的字符串数组,在 Netron 中分析 ONNX 模型时也可以找到该名称。
.Append(context.Transforms.ApplyOnnxModel(outputColumnNames: new string[] { "detected_boxes", "detected_scores", "detected_classes" }, inputColumnNames: new string[] { "image_tensor" }, modelFile: "./Model/model.onnx"));
拟合模型
定义管道后,可以使用它生成 ML.NET 模型。
Fit在管道上使用该方法并传入空 IDataView。
var model = pipeline.Fit(data);
接下来,若要进行预测,请使用模型创建预测引擎。 这是一个泛型方法,因此它采用StopSignInputStopSignPrediction之前创建的类。
var predictionEngine = context.Model.CreatePredictionEngine<StopSignInput, StopSignPrediction>(model);
提取标签
若要将模型输出映射到其标签,需要提取自定义视觉提供的标签。 这些标签位于带有 ONNX 模型的 zip 文件中包含的 labels.txt 文件中。
ReadAllLines调用该方法以读取文件中的所有标签。
var labels = File.ReadAllLines("./model/labels.txt");
预测测试图像
现在可以使用模型来预测新图像。 在项目中,有一个 测试 文件夹可用于进行预测。 此文件夹包含两个随机图像,其中一个来自 Unsplash 的停止登录。 一个图像有一个停止标志,而另一个图像有两个停止标志。
GetFiles使用该方法读取目录中图像的文件路径。
var testFiles = Directory.GetFiles("./test");
循环访问文件路径以使用模型进行预测并输出结果。
创建循环
foreach以循环遍历测试映像。Bitmap testImage; foreach (var image in testFiles) { }在
foreach循环中,根据原始测试映像的名称生成预测的图像名称。var predictedImage = $"{Path.GetFileName(image)}-predicted.jpg";在循环中
foreach,创建FileStream映像并将其转换为 .Bitmapusing (var stream = new FileStream(image, FileMode.Open)) { testImage = (Bitmap)Image.FromStream(stream); }此外,在
foreach循环中,对预测引擎调用Predict该方法。var prediction = predictionEngine.Predict(new StopSignInput { Image = testImage });通过预测,可以获取边界框。 使用该方法 Chunk 确定模型检测到的对象数。 为此,请计算预测边界框的总数,并将其除以预测出的标签数量。 例如,如果在图像中检测到三个对象,则
BoundingBoxes数组中有 12 个项,并预测了三个标签。 然后,该方法Chunk将为你提供三个每个包含四个元素的数组,以表示每个对象的边界框。var boundingBoxes = prediction.BoundingBoxes.Chunk(prediction.BoundingBoxes.Count() / prediction.PredictedLabels.Count());接下来,捕获用于预测的图像的原始宽度和高度。
var originalWidth = testImage.Width; var originalHeight = testImage.Height;计算图像中绘制框的位置。 为此,请基于边界框集合的数量创建一个
for循环。for (int i = 0; i < boundingBoxes.Count(); i++) { }在
for循环中,计算 x 坐标和 y 坐标的位置,以及绘制在图像上的框的宽度和高度。 首先,需要使用ElementAt方法获取一组边界框。var boundingBox = boundingBoxes.ElementAt(i);现在,使用当前边界框,可以计算绘制框的位置。 对边界框的第一个和第三个元素使用图像的原始宽度,对第二个和第四个元素使用图像的原始高度。
var left = boundingBox[0] * originalWidth; var top = boundingBox[1] * originalHeight; var right = boundingBox[2] * originalWidth; var bottom = boundingBox[3] * originalHeight;计算要围绕图像中检测到的对象绘制的框的宽度和高度。 x 和 y 项是上一个计算中的变量
left和top。 使用该方法Math.Abs从宽度和高度计算中获取绝对值,以防其为负值。var x = left; var y = top; var width = Math.Abs(right - left); var height = Math.Abs(top - bottom);接下来,从标签数组中获取预测的标签。
var label = labels[prediction.PredictedLabels[i]];使用
Graphics.FromImage该方法基于测试映像创建图形。using var graphics = Graphics.FromImage(testImage);使用边界框信息绘制图像。 首先,使用
DrawRectangle方法,该方法接受Pen对象来确定矩形的颜色和宽度,并传入x、y、width和height变量,以在检测到的对象周围绘制矩形。graphics.DrawRectangle(new Pen(Color.NavajoWhite, 8), x, y, width, height);然后,在框中显示预测的标签,其中包含
DrawString用于打印输出的方法和一个Font对象,以确定如何绘制字符串及其放置位置。graphics.DrawString(label, new Font(FontFamily.Families[0], 18f), Brushes.NavajoWhite, x + 5, y + 5);循环
for后,检查预测的文件是否已存在。 如果这样做,请将其删除。 然后,将其保存到定义的输出路径。if (File.Exists(predictedImage)) { File.Delete(predictedImage); } testImage.Save(Path.Combine(assemblyFolderPath, predictedImage));
后续步骤
尝试其他图像分类教程之一:
- 使用传输学习进行图像分类
- 使用模型生成器进行图像分类
- 使用 Tensorflow 模型进行图像分类