使用 Dataflow Gen2 清理和准备数据后,需要将其保存在有用位置。 数据流 Gen2 允许从多个目标中进行选择,例如 Azure SQL、Fabric Lakehouse 等。 选择目标后,Dataflow Gen2 会在那里写入数据,并可用于分析和报告。
以下列表包含支持的数据目标:
- Azure SQL 数据库
- Azure 数据资源管理器 (Kusto)
- Azure Datalake Gen2 (预览版)
- Fabric Lakehouse 数据表
- Fabric Lakehouse 文件(预览版)
- Fabric Warehouse
- Fabric KQL 数据库
- Fabric SQL 数据库
- SharePoint 文件
注意
若要将数据加载到 Fabric Warehouse,可以通过获取 SQL 连接字符串来使用 Azure Synapse Analytics (SQL DW) 连接器。 更多信息:连接到 Microsoft Fabric 中的数据仓库
入口点
Dataflow Gen2 中的每个数据查询都可以有一个数据目标。 只能将目标应用于表格查询 - 不支持函数和列表。 可以单独为每个查询设置数据目标,并且可以在同一数据流中使用不同的目标。
可通过三种方法设置数据目标:
通过顶部功能区。

通过查询设置。
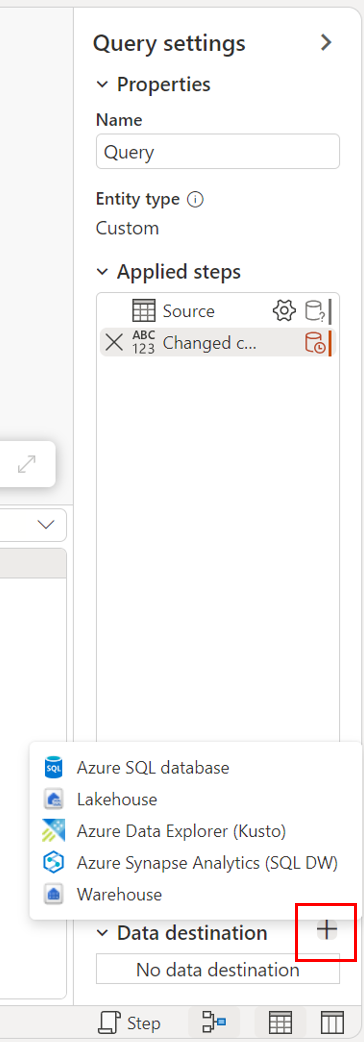
通过关系图视图。

连接到数据目标
连接到数据目标的工作方式类似于连接到数据源。 只要对数据源拥有适当的权限,就可以使用连接来读取和写入数据。 需要创建新的连接或选取现有连接,然后选择“ 下一步”。

设置基于文件的目标位置
选择基于文件的目标(例如 SharePoint)时,需要配置一些设置。 下面是需要设置的内容:
- 文件名:在目标中创建的文件的名称。 默认情况下,文件名与查询名称匹配。
- 文件格式:在目标中创建的文件的格式。
- 文件源:用于在目标中创建文件的编码。 默认情况下,这设置为 UTF-8。
- 文件分隔符:用于在目标中创建文件的分隔符。 默认情况下,这设置为 逗号。

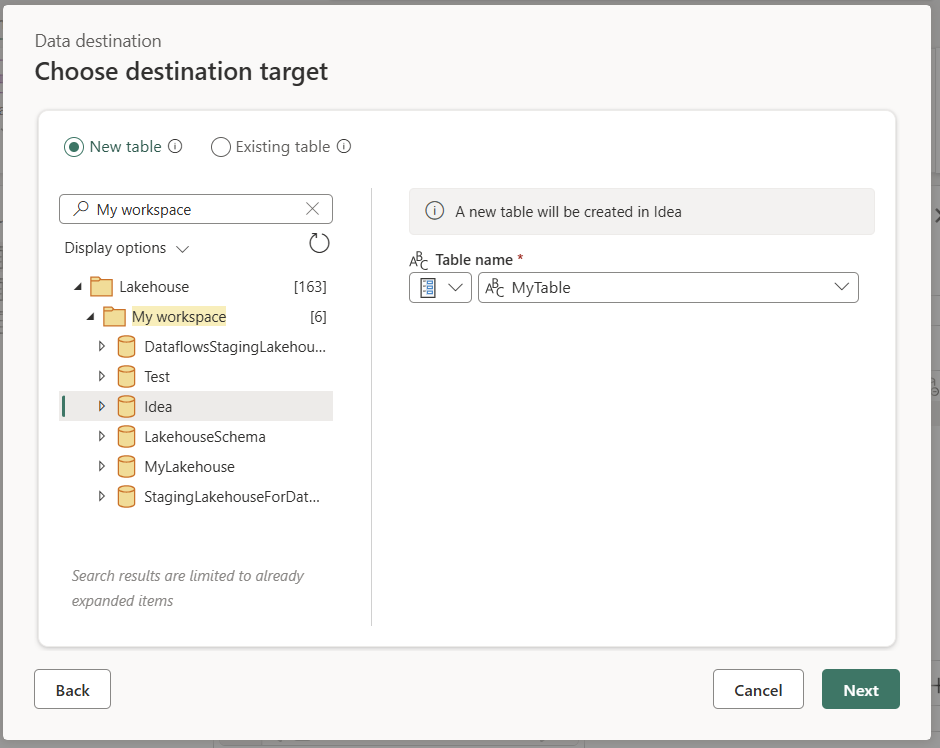
创建新表或选取现有表
加载到数据目标时,可以创建新表或选取现有表。
创建一个新表
选择创建新表时,Dataflow Gen2 会在刷新期间在数据目标中创建一个新表。 如果稍后删除该表(如果手动进入目标并删除该表),则数据流在下一次刷新期间会重新创建该表。
默认情况下,表名称与查询名称匹配。 如果表名包含目标不支持的任何字符,则会自动调整表名。 例如,许多目标不支持空格或特殊字符。

接下来,需要选择目标容器。 如果选择了任意一个 Fabric 数据目标,您可以使用导航器来选择要加载数据的 Fabric 项。 对于 Azure 目标,可以在创建连接期间指定数据库,也可以从导航器体验中选择数据库。
使用现有表
若要选择现有表,请使用导航器顶部的开关。 选择现有表时,您需要通过导航器选择 Fabric 项目/数据库和表。
使用现有表时,在任何情况下都无法重新创建该表。 如果从数据目标手动删除表,则数据流 Gen2 在下一次刷新时不会重新创建该表。

Lakehouse 文件或表
对于 Lakehouse,可以选择在 Lakehouse 中创建文件或表。 大多数目的地仅支持其中一个,因此这是独特的。 这样可以在您的湖仓中更灵活地组织数据结构。
若要在文件和表之间切换,可以在浏览 Lakehouse 时使用切换按钮。

新表的托管设置
加载到新表时,默认情况下会启用自动设置。 如果使用自动设置,则数据流 Gen2 会为你管理映射。 自动设置的功能如下:
更新方法替换:每次数据流刷新时都会替换数据。 目标中的任何数据都将被删除。 目标中的数据将替换为数据流的输出数据。
托管映射:映射由系统为您管理。 当需要对数据/查询进行更改以添加另一列或更改数据类型时,重新发布数据流时,会自动调整此更改的映射。 每次对数据流进行更改时,都无需进入数据目标体验,这会使重新发布数据流时架构更改变得容易。
删除并重新创建表:若要允许这些架构更改,表将在每次数据流刷新时删除并重新创建。 数据流刷新可能会导致删除以前添加到表的关系或度量值。
注意
目前,自动设置仅支持将 Lakehouse 和 Azure SQL 数据库作为数据目标。

手动设置
通过关闭 “使用自动设置”,可以完全控制如何将数据加载到数据目标。 可以通过更改源类型或排除数据目标中不需要的任何列来对列映射进行任何更改。

更新方法
大多数目标都支持将追加和替换作为更新方法。 但是,Fabric KQL 数据库和 Azure 数据资源管理器不支持将替换作为更新方法。
替换:每次数据流刷新时,数据将从目标中删除,并替换为数据流的输出数据。
追加:每次数据流刷新时,数据流的输出数据将追加到数据目标表中的现有数据。
发布时使用的架构选项
仅当 更新方法被替换时,发布上的架构选项才适用。 追加数据时,无法更改架构。
动态架构:选择动态架构时,允许在重新发布数据流时在数据目标中进行架构更改。 由于未使用托管映射,因此在对查询进行任何更改时,仍需要在数据流目标向导中更新列映射。 当刷新检测到目标架构与预期架构之间的差异时,将删除该表,然后重新创建以与预期架构保持一致。 数据流刷新可能会导致删除以前添加到表的关系或度量值。
固定架构:选择固定架构时,将无法更改架构。 刷新数据流时,仅删除表中的行,并将其替换为数据流中的输出数据。 表上的任何关系或度量值将保持不变。 如果对数据流中的查询进行了任何更改,并且检测到查询架构与数据目标架构不匹配,则数据流发布将会失败。 如果不打算更改架构并将关系或度量值添加到目标表,请使用此设置。
注意
将数据加载到仓库时,仅支持固定架构。

参数化
参数 是数据流 Gen2 中的核心功能。 创建参数或使用 Always allow 设置后,输入小组件将可用于定义目标的表或文件名。
注意
还可以通过为与数据目标相关的查询创建的 M 脚本直接应用数据目标中的参数。 可以手动更改数据目标查询的脚本,以应用参数以满足你的要求。 但是,用户界面当前仅支持表或文件名字段的参数化。
数据目标查询的 Mashup 脚本
使用数据目标功能时,加载数据到目标所需的设置是在数据流的混合文档中定义的。 数据流应用程序从根本上创建了两个组件:
- 包含目标导航步骤的查询。 它遵循初始查询名称的模式,后缀为 _DataDestination。 例如:
shared #"Orders by Region_DataDestination" = let
Pattern = Lakehouse.Contents([CreateNavigationProperties = false, EnableFolding = false]),
Navigation_1 = Pattern{[workspaceId = "cfafbeb1-8037-4d0c-896e-a46fb27ff229"]}[Data],
Navigation_2 = Navigation_1{[lakehouseId = "b218778-e7a5-4d73-8187-f10824047715"]}[Data],
TableNavigation = Navigation_2{[Id = "Orders by Region", ItemKind = "Table"]}?[Data]?
in
TableNavigation;
- DataDestinations 属性记录包含查询中用于将数据加载到目标的逻辑。 该记录具有指向查询的指针,该查询包含指向目标的导航步骤和总体目标设置,例如更新方法、架构选项以及目标的目标类型(如表或其他类型)。 例如:
[DataDestinations = {[Definition = [Kind = "Reference", QueryName = "Orders by Region_DataDestination", IsNewTarget = true], Settings = [Kind = "Automatic", TypeSettings = [Kind = "Table"]]]}]
这些 M 脚本在数据流应用程序中不可见,但可以通过以下方式访问此信息:
每个目标支持的数据源类型
| 每个存储位置支持的数据类型 | DataflowStagingLakehouse | Azure DB (SQL) 输出 | Azure 数据资源管理器输出 | Fabric 湖屋 (LH) 输出 | Fabric 仓库 (WH) 输出 | Fabric SQL 数据库 (SQL) 输出 |
|---|---|---|---|---|---|---|
| 操作 | 否 | 否 | 否 | 否 | 否 | 否 |
| 任意 | 否 | 否 | 否 | 否 | 否 | 否 |
| 二进制 | 否 | 否 | 否 | 否 | 否 | 否 |
| 货币 | 是 | 是 | 是 | 是 | 否 | 是 |
| 时区 | 是 | 是 | 是 | 否 | 否 | 是 |
| 持续时间 | 否 | 否 | 是 | 否 | 否 | 否 |
| 函数 | 否 | 否 | 否 | 否 | 否 | 否 |
| 无 | 否 | 否 | 否 | 否 | 否 | 否 |
| 零 | 否 | 否 | 否 | 否 | 否 | 否 |
| 时间 | 是 | 是 | 否 | 否 | 否 | 是 |
| 类型 | 否 | 否 | 否 | 否 | 否 | 否 |
| 结构化(列表、记录、表) | 否 | 否 | 否 | 否 | 否 | 否 |
使用货币或百分比等数据类型时,我们通常会将其转换为大多数目标的十进制等效项。 在重新连接到这些目的地并遵循现有数据表路径时,可能会遇到一些困难。例如,在将货币映射到小数列时,可能会出现问题。 在这种情况下,请尝试将编辑器中的数据类型更改为十进制,因为这样可以更轻松地映射到现有表和列。
高级主题
在加载到目标之前使用暂存
为了提高查询处理的性能,可以在 Dataflow Gen2 中使用暂存,以使用 Fabric 计算来执行查询。
在查询(默认行为)上启用暂存时,数据将加载到暂存位置,这是只能由数据流本身访问的内部 Lakehouse。
在某些情况下,使用中间存储位置可以提高性能,因为将查询发送到 SQL 分析端点进行折叠比内存中处理更快。
将数据加载到 Lakehouse 或其他非仓库目标时,我们默认禁用暂存功能以提高性能。 将数据加载到数据目标时,数据将直接写入数据目标,而无需使用暂存。 如果要为查询使用暂存,则可以再次启用。
要启用暂存,请右键单击查询,并通过选择“启用暂存”按钮来启用暂存。 然后,查询将变为蓝色。

将数据载入仓库
将数据加载到仓库时,在将数据写入到数据目标之前需要暂存。 此要求可改善性能。 目前,仅支持加载到与数据流相同的工作区。 确保为所有加载到仓库的查询启用暂存。
禁用暂存并选择 Warehouse 作为输出目标时,会收到一条警告,要求先启用暂存,然后才能配置数据目标。

如果已将仓库作为目标并尝试禁用暂存,则会显示警告。 可以移除作为目标的仓库,也可以关闭暂存操作。

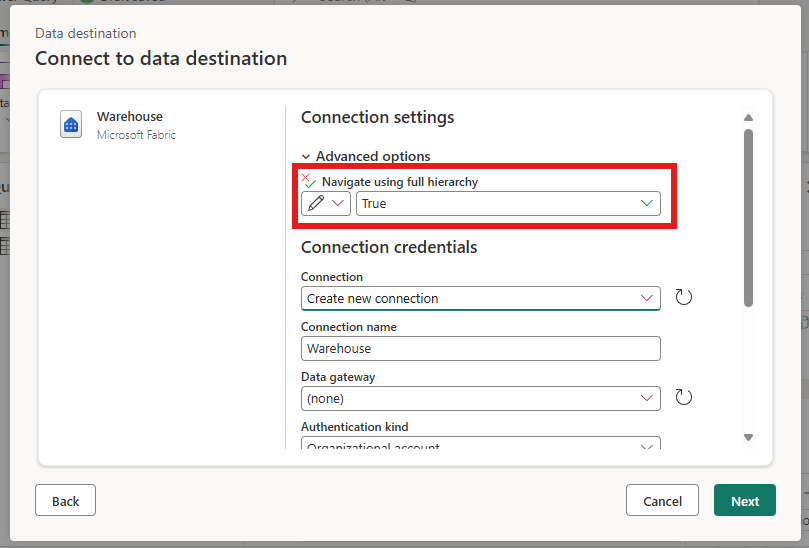
对 Lakehouse、Warehouse 和 SQL 数据库的架构支持(预览版)
Microsoft Fabric 中的 Lakehouse、Warehouse 和 SQL 数据库都支持为数据创建架构的功能。 这意味着,可以采用一种更易于管理和查询的方式构建数据。 为了能够在这些目标中写入架构,需要在设置连接时,在高级选项下启用“使用完整层次结构”选项进行导航。 如果未启用此选项,将无法选择或查看目标中的架构。 启用完整层次结构来导航的预览限制是快速复制功能可能无法正常工作。 若要将此功能与网关结合使用,我们至少需要 3000.290 版本的网关。
清空湖屋数据目标
在 Microsoft Fabric 中使用 Lakehouse 作为数据流 Gen2 的目标时,请务必定期执行维护,以保持最佳性能和高效的存储管理。 一项基本维护任务是清空数据目标。 此过程有助于删除 Delta 表日志不再引用的旧文件,从而优化存储成本并维护数据的完整性。
为什么清空很重要
- 存储优化:随着时间的推移,Delta 表会累积不再需要的旧文件。 清空有助于清理这些文件,释放存储空间并降低成本。
- 性能提升:移除不必要的文件可以通过减少读取操作期间需要扫描的文件数来提高查询性能。
- 数据完整性:确保仅保留相关文件有助于维护数据的完整性,防止未提交文件可能导致读取器故障或表损坏的潜在问题。
如何清空数据目标
若要清空湖屋中的 Delta 表,请执行以下步骤:
- 导航到湖屋:从 Microsoft Fabric 帐户中,转到所需的湖屋。
- 访问表维护:在湖屋资源管理器中,右键单击要维护的表或使用省略号访问上下文菜单。
- 选择维护选项:选择“维护”菜单项,然后选择“清空”选项。
- 运行清空命令:设置保留阈值(默认值为 7 天),并通过选择“立即运行”来执行清空命令。
最佳做法
- 保留期:设置至少七天的保留时间间隔,以确保不会过早删除旧快照和未提交文件,这可能会中断并发表读取表和写入表的操作。
- 定期维护:将定期清空安排为数据维护例程的一部分,以使 Delta 表保持优化并为分析做好准备。
- 增量刷新:如果使用增量刷新,请确保关闭清扫,因为它可能会干扰增量刷新过程。
通过将清理纳入您的数据维护策略,可以确保您的 Lakehouse 目标在数据流操作中保持高效、经济高效且可靠。
有关湖屋中的表维护的更多详细信息,请参阅 Delta 表维护文档。
可为 Null
在某些情况下,如果有可为 null 的列,Power Query 会将其检测为不可为 null,写入数据目标时,列类型不可为 null。 在刷新期间,会发生以下错误:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
若要强制实施可为 null 的列,可以尝试以下步骤:
从数据目标中删除表。
从数据流中删除数据目标。
转到数据流,使用以下 Power Query 代码更新数据类型:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )添加数据目标。
数据类型转换和纵向扩展
在某些情况下,数据流中的数据类型不同于数据目标中支持的内容。 下面是我们实施的一些默认转换,以确保你仍然可以在数据目标中获取数据:
| 目标 | 数据流数据类型 | 目标数据类型 |
|---|---|---|
| Fabric Warehouse | Int8.Type | Int16.Type |