适用于:✅Microsoft Fabric 中的 Warehouse
管道通过图形用户界面提供使用 COPY 命令的替代方法。 管道是由逻辑上分组的活动组成的,它们共同执行数据摄取任务。 可以使用管道来管理提取、转换和加载 (ETL) 活动,而不必单独管理每个活动。
在本教程中,你将创建一个新管道,用于将示例数据加载到 Microsoft Fabric 中的 Warehouse 中。
注意
Azure 数据工厂中的某些功能在 Microsoft Fabric 中不可用,但概念是互通的。 可以在 Azure 数据工厂和 Azure Synapse Analytics 中的 Pipelines 和活动中详细了解 Azure 数据工厂和 Pipelines。 如需快速入门,请访问快速入门:创建你的第一个用于复制数据的管道。
创建管道
若要创建新管道,请先导航至工作区,选择+ 新建项按钮,然后在获取数据部分中选择管道。
在“新建管道”对话框中,提供新管道的名称,然后选择“创建”。
你将进入管道画布区域,可在其中查看入门选项。

选择 “复制数据助手 ”选项以启动 复制助手。
复制数据助手的第一页可帮助你从各种数据源中选择自己的数据,或从所提供的示例之一中进行选择以开始使用。 从此页面的菜单栏中选择 示例数据 。 在本教程中,我们将使用 COVID-19 Data Lake 示例。 选择此选项,然后选择“下一页”。

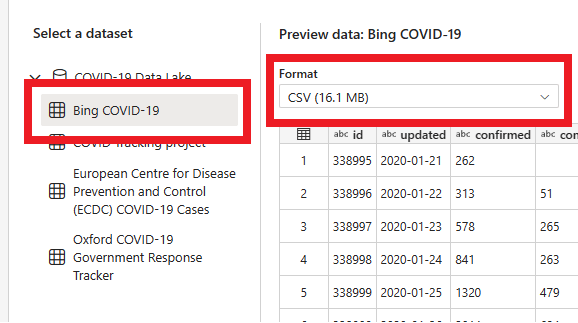
在下一页中,你可以选择数据集、源文件格式并预览所选数据集。 选择“必应 COVID-19”和 CSV 格式,然后选择“下一页”。
下一页“数据目标”让你能够配置目标工作区的类型。 我们将数据加载到工作区中的仓库。 在下拉列表中选择所需的仓库,然后选择“下一步”。
配置目标的最后一步是向目标表提供名称并配置列映射。 在这里,可以选择将数据加载到新表或现有表、提供架构和表名称、更改列名、删除列或更改其映射。 可以接受默认设置,也可以根据自己的偏好调整设置。

查看完选项后,选择“下一页”。
下一页提供使用 暂存的选项,或提供数据复制作的高级选项(使用 T-SQL COPY 命令)。 查看选项而不更改它们,然后选择“ 下一步”。
助手的最后一页提供了复制活动的摘要。 选择“立即开始数据传输”选项,然后选择“保存 + 运行”。

系统会定向到管道画布区域,在那里已为你配置好了新的“复制数据”活动。 管道开始自动运行。 可以在“输出”窗格中监视管道的状态:

几秒钟后,管道将成功完成。 导航回仓库后,可以选择你的表来预览数据并确认复制操作是否已结束。





后续步骤
数据引入选项
将数据引入仓库的其他方法包括: