适用于:Microsoft Fabric 中的✅ 仓库
本文详细介绍了将 Azure Synapse Analytics 专用 SQL 池中的数据仓库迁移到 Microsoft Fabric Warehouse 的方法。
小提示
有关迁移策略和规划的更多信息,请参阅迁移规划:从 Azure Synapse Analytics 专用 SQL 池迁移到 Fabric 数据仓库。
使用适用于数据仓库的 Fabric 迁移助手可实现从 Azure Synapse Analytics 专用 SQL 池迁移的自动化体验。 本文的其余部分包含更多手动迁移步骤。
此表总结了有关数据架构 (DDL)、数据库代码 (DML) 和数据迁移方法的信息。 我们将在本文后面进一步深入介绍每个场景,并在“选项”列中链接。
| 选项编号 | 选项 | 它的作用是什么 | 技能/首选项 | 方案 |
|---|---|---|---|---|
| 1 | 数据工厂 | 架构 (DDL) 转换 数据提取 数据引入 |
ADF/管道 | 简化的一体式架构 (DDL) 和数据迁移。 建议用于维度表。 |
| 2 | 具有分区的数据工厂 | 架构 (DDL) 转换 数据提取 数据引入 |
ADF/管道 | 使用分区选项增加读/写并行度,与选项 1(事实数据表的建议选项)相比,吞吐量是其 10 倍。 |
| 3 | 具有加速代码的数据工厂 | 架构 (DDL) 转换 | ADF/管道 | 首先转换并迁移架构(DDL),然后使用 CETAS 提取数据,并使用 COPY/数据工厂导入数据,以获得最佳的整体导入性能。 |
| 4 | 存储过程加速代码 | 架构 (DDL) 转换 数据提取 代码评估 |
T-SQL | 使用 IDE 的 SQL 用户可以更精细地控制要处理的任务。 使用 COPY/数据工厂导入数据。 |
| 5 | Visual Studio Code 的 SQL 数据库项目扩展 | 架构 (DDL) 转换 数据提取 代码评估 |
SQL 项目 | 用于部署的 SQL 数据库项目与选项 4 的集成。 使用 COPY 或数据工厂引入数据。 |
| 6 | 创建外部表 AS SELECT (CETAS) | 数据提取 | T-SQL | 将高性能数据提取到 Azure Data Lake Storage (ADLS) Gen2 中,经济高效。 使用 COPY/数据工厂导入数据。 |
| 7 | 使用 dbt 进行迁移 | 架构 (DDL) 转换 数据库代码 (DML) 转换 |
dbt | 现有 dbt 用户可以使用 dbt Fabric 适配器转换其 DDL 和 DML。 然后,必须使用此表中的其他选项迁移数据。 |
选择初始迁移的工作负载
决定从哪里开始 Synapse 专用 SQL 池到 Fabric Warehouse 迁移项目时,请选择一个工作负荷区域,以便你能够:
- 通过快速提供新环境的优势,证明迁移到 Fabric Warehouse 的可行性。 从小型和简单的迁移开始,准备多个小型迁移。
- 给予内部技术人员时间,以便他们在迁移到其他领域时能够积累使用相关流程和工具的经验。
- 为进一步的迁移创建模板,该模板需特定于源 Synapse 环境以及当前已有的有用工具和流程。
小提示
创建需要迁移的对象的清单,并记录从开始到结束的迁移过程,以便可以对其他专用 SQL 池或工作负荷重复此过程。
初始迁移中迁移的数据量应足够大,能够体现出 Fabric Warehouse 环境的功能和优势,但不应过大以至无法快速体现出价值。 典型的大小为 1-10 TB。
使用 Fabric 数据工厂进行迁移
在本部分中,我们将讨论对熟悉 Azure 数据工厂和 Synapse Pipeline 的低代码/无代码角色使用数据工厂的选项。 这种拖放式 UI 选项提供了一个简单的步骤来转换 DDL 并迁移数据。
Fabric 数据工厂可以执行以下任务:
- 将架构 (DDL) 转换为 Fabric Warehouse 语法。
- 在 Fabric Warehouse 上创建架构 (DDL)。
- 将数据迁移到 Fabric Warehouse。
选项 1. 架构/数据迁移 - 复制向导和 ForEach 复制活动
此方法使用数据工厂复制助手连接到源专用 SQL 池,将专用 SQL 池 DDL 语法转换为 Fabric,并将数据复制到 Fabric Warehouse。 可以选择一个或多个目标表(对于 TPC-DS 数据集,有 22 个表)。 这会生成 ForEach 以循环访问 UI 中选择的表清单,并生成 22 个并行的“复制活动”线程。
- 在专用 SQL 池中生成和执行 22 个 SELECT 查询(每个选中的表各有一个)。
- 请确保具有适当的 DWU 和资源类,以允许执行生成的查询。 在这种情况下,你至少需要 DWU1000 和
staticrc10,以允许最多 32 个查询来处理提交的 22 个查询。 - 数据工厂可直接将数据从专用 SQL 池复制到 Fabric Warehouse,但需要暂存。 引入过程由两个阶段组成。
- 第一个阶段包括将数据从专用 SQL 池提取到 ADLS 中,称为暂存。
- 第二个阶段包括将数据从暂存位置引入到 Fabric 仓库中。 大多数数据引入计时处于暂存阶段。 总之,暂存对引入性能有巨大影响。
建议用途
使用复制向导生成 ForEach 提供了一个简便的用户界面,用于转换 DDL 并在一个步骤中将所选表从专用 SQL 池引入到 Fabric Warehouse。
然而,从总体吞吐量来看,它并不是最佳的选择。 造成性能延迟的主要因素是需要使用暂存,并且在“源到阶段”步骤中需要进行读写并行化。 建议仅对维度表使用此选项。
选项 2. DDL/数据迁移 - 使用分区选项的管道
为了提高传输率以使用 Fabric 管道加载更大的事实数据表,建议对每个具有分区选项的事实数据表使用复制活动 (Copy Activity)。 这为复制活动提供了最佳性能。
你可以选择使用源表物理分区(如果可用)。 如果表没有物理分区,则必须指定分区列并提供最小/最大值才能使用动态分区。 在以下屏幕截图中,管道 源 选项根据 ws_sold_date_sk 列指定动态分区范围。
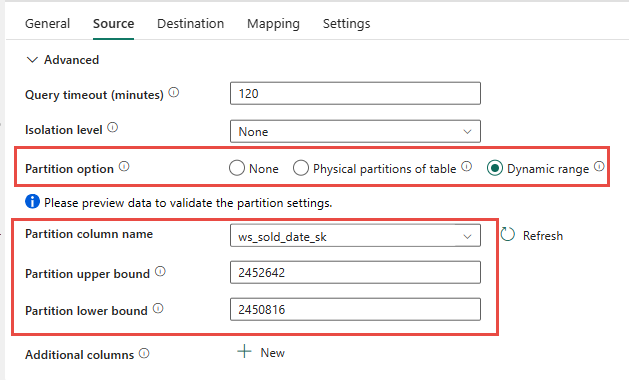
虽然使用分区可以增加暂存阶段的吞吐量,但需要考虑进行适当的调整:
- 根据你的分区范围,它可能会使用所有的并发槽,因为它可能会在专用 SQL 池上生成超过 128 个查询。
- 你必须将规模提升至至少 DWU6000 才能执行所有查询。
- 例如,对于 TPC-DS
web_sales表,163 个查询已提交到专用 SQL 池。 在 DWU6000 中,执行了 128 个查询,同时有 35 个查询在排队。 - 动态分区会自动选择范围分区。 在这种情况下,每个提交到专用 SQL 池的 SELECT 查询的范围为 11 天。 例如:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
建议用途
对于事实数据表,建议使用数据工厂和分区选项来提高吞吐量。
但是,增加的并行读取需要专用 SQL 池扩展到更高的 DWU,以允许执行提取查询。 利用分区后,速度比不采用分区选项提高了十倍。 可以通过计算资源增加 DWU 以获取额外的吞吐量,但专用 SQL 池最多允许 128 个活动查询。
有关 Synapse DWU 到 Fabric 映射的详细信息,请参阅博客:将 Azure Synapse 专用 SQL 池映射到 Fabric 数据仓库计算。
选项 3. DDL 迁移 - 复制向导 ForEach 复制活动
对于较小的数据库,前面的两个选项是很不错的数据迁移选项。 但是,如果需要更高的吞吐量,建议使用替代选项:
- 将数据从专用 SQL 池提取到 ADLS,从而缓解暂存性能开销。
- 使用数据工厂或 COPY 命令将数据引入 Fabric Warehouse。
建议用途
您可以继续使用数据工厂来转换您的模式 (DDL)。 使用复制向导,可以选择特定的表或“所有”表。 根据设计,这会通过一个步骤迁移架构和数据,使用查询语句中的 false 条件 TOP 0 提取不包含任何行的架构。
以下代码示例介涵盖了使用数据工厂进行架构 (DDL) 迁移。
代码示例:使用数据工厂进行架构 (DDL) 迁移
可以使用 Fabric 管道轻松地从任何源 Azure SQL 数据库或专用 SQL 池中迁移表对象的 DDL (架构)。 此管道通过源专用 SQL 池表的架构(DDL)迁移到 Fabric Warehouse。

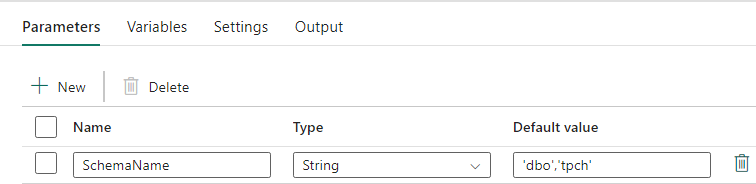
管道设计:参数
此管道接受参数,该参数 SchemaName允许指定要迁移的架构。 默认为 dbo 架构。
在“默认值”字段中,输入逗号分隔的表架构列表,以指示要迁移的模式: 提供两个模式,分别为 'dbo','tpch' 和 dbo。tpch
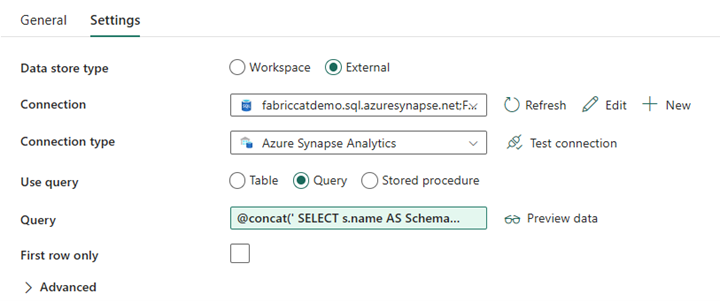
管道设计:查找活动
创建“查找活动”并将连接设置为指向源数据库。
在“设置”选项卡中:
将“数据存储类型”设置为“外部”。
连接是你的 Azure Synapse 专用 SQL 池。 “连接类型”为“Azure Synapse Analytics”。
“使用查询”设置为“查询”。
需要使用动态表达式构建“查询”字段,从而允许在返回目标源表列表的查询中使用 SchemaName 参数。 选择“查询”,然后选择“添加动态内容”。
查找活动中的此表达式将生成一个 SQL 语句来查询系统视图,以检索架构和表的列表。 引用 SchemaName 参数以允许对 SQL 架构进行筛选。 输出将是一个包含 SQL 架构和表的数组,这将作为 ForEach 活动的输入。
使用以下代码返回所有用户表及其架构名称的列表。
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
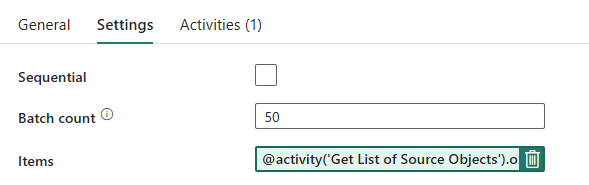
管道设计:ForEach 循环
对于 ForEach 循环,请在“设置”选项卡中配置以下选项:
- 禁用顺序选项以允许多个迭代并发运行。
- 将“批次数量”设置为 ,从而限制并发迭代的最大次数。
50 - “项”字段需要使用动态内容来引用查找活动的输出。 添加以下代码片段:
@activity('Get List of Source Objects').output.value
管道设计:ForEach 循环中的复制活动
在 ForEach 活动内,添加一个复制活动。 此方法使用管道中的动态表达式语言生成一个 SELECT TOP 0 * FROM <TABLE> ,以仅迁移架构而不将数据迁移到 Fabric Warehouse。
在“源”选项卡中:
- 将“数据存储类型”设置为“外部”。
- 连接是你的 Azure Synapse 专用 SQL 池。 “连接类型”为“Azure Synapse Analytics”。
- 将“使用查询”设置为“查询”。
- 在“查询”字段中,粘贴动态内容查询并使用以下表达式,该表达式将返回零行,仅返回表架构:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

在“目标”选项卡中:
- 将“数据存储类型”设置为“工作区”。
- “工作区数据存储类型”为“数据仓库”,“数据仓库”设置为 Fabric Warehouse。
- 目标表的架构和表名称是使用动态内容定义的。
- 架构是指当前迭代的字段,包含代码片段的 SchemaName:
@item().SchemaName - 表通过代码片段引用 TableName:
@item().TableName
- 架构是指当前迭代的字段,包含代码片段的 SchemaName:

管道设计:接收器
对于接收器,请指向仓库并引用源架构和表名称。
运行此管道后,你将看到数据仓库中填充了源中的每个表,并使用适当的架构。
在 Synapse 专用 SQL 池中使用存储过程进行迁移
此选项使用存储过程来执行 Fabric 迁移。
你可以在 github.com 上的 microsoft/fabric-migration 获取代码示例。 此代码作为开放源代码共享,因此尽情贡献内容并帮助社区。
迁移存储过程能做些什么:
- 将架构 (DDL) 转换为 Fabric Warehouse 语法。
- 在 Fabric Warehouse 上创建架构 (DDL)。
- 将数据从 Synapse 专用 SQL 池提取到 ADLS。
- 标记 T-SQL 代码(存储过程、函数、视图)不支持的 Fabric 语法。
建议用途
此选项非常适合于以下人员:
- 熟悉 T-SQL。
- 希望使用集成开发环境,如 SQL Server Management Studio (SSMS)。
- 希望更精细地控制要处理的任务。
可以执行架构 (DDL) 转换、数据提取或 T-SQL 代码评估的特定存储过程。
对于数据迁移,需要使用 COPY INTO 或数据工厂将数据引入 Fabric Warehouse。
使用 SQL 数据库项目进行迁移
Visual Studio Code 中提供的 SQL 数据库项目扩展支持Microsoft Fabric 数据仓库。
此扩展在 Visual Studio Code 中可用。 此功能支持源代码管理、数据库测试和架构验证的功能。
有关 Microsoft Fabric 中仓库的源代码管理的详细信息,包括 Git 集成和部署管道,请参阅仓库源代码管理。
建议用途
对于喜欢使用 SQL 数据库项目进行部署的人来说,这是个绝佳选择。 此选项本质上是将 Fabric 迁移存储过程集成到 SQL 数据库项目中,以提供无缝迁移体验。
SQL 数据库项目可以:
- 将架构 (DDL) 转换为 Fabric Warehouse 语法。
- 在 Fabric Warehouse 上创建架构 (DDL)。
- 将数据从 Synapse 专用 SQL 池提取到 ADLS。
- 标记 T-SQL 代码(存储过程、函数、视图)不支持的语法。
对于数据迁移,你随后需要使用 COPY INTO 或数据工厂将数据引入 Fabric Warehouse。
Microsoft Fabric CAT 团队提供了一组 PowerShell 脚本,用于通过 SQL 数据库项目处理架构(DDL)和数据库代码(DML)的提取、创建和部署。 有关将 SQL 数据库项目与有用的 PowerShell 脚本配合使用的演练,请参阅 GitHub.com 上的 microsoft/fabric-migration。
有关 SQL 数据库项目的详细信息,请参阅 SQL 数据库项目扩展入门和生成和发布项目。
使用 CETAS 迁移数据
T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) 命令提供经济高效的最佳方法,用于将数据从 Synapse 专用 SQL 池提取到 Azure Data Lake Storage (ADLS) Gen2。
CETAS 的功能:
- 将数据提取到 ADLS 中。
- 此选项要求用户在引入数据之前在 Fabric Warehouse 上创建架构 (DDL)。 迁移架构 (DDL) 时,请考虑本文中的选项。
此选项的优点包括:
- 仅针对源 Synapse 专用 SQL 池提交每个表的单个查询。 这不会用尽所有并发槽位,因此也不会妨碍客户生产过程中的ETL处理或查询。
- 无需缩放到 DWU6000,因为每个表仅使用单个并发槽位,因此客户可以使用较低的 DWU。
- 提取在所有计算节点之间并行运行,这是提高性能的关键。
建议用途
使用 CETAS 将数据作为 Parquet 提取到 ADLS 中。 Parquet 文件通过列式压缩提供了高效数据存储的优势,这种文件格式在网络上移动时占用的带宽更少。 此外,由于 Fabric 将数据存储为 Delta Parquet 格式,因此与文本文件格式相比,数据引入速度是文本文件格式的 2.5 倍,因为在引入期间无须转换为 Delta 格式,从而减少了开销。
增加 CETAS 吞吐量:
- 添加并行 CETAS 操作,增加并发槽的使用,但可以提高吞吐量。
- 在 Synapse 专用 SQL 池上缩放 DWU。
通过 dbt 进行迁移
在本部分中,我们将讨论 dbt 选项,此选项适用于已在其当前 Synapse 专用 SQL 池环境中使用 dbt 的客户。
dbt 的功能:
- 将架构 (DDL) 转换为 Fabric Warehouse 语法。
- 在 Fabric Warehouse 上创建架构 (DDL)。
- 将数据库代码 (DML) 转换为 Fabric 语法。
dbt 框架在每次执行时都会动态生成 DDL 和 DML (SQL 脚本)。 使用 SELECT 语句表示的模型文件,通过更改配置文件(连接字符串)和适配器类型,可以将 DDL/DML 立即转换为任何目标平台。
建议用途
dbt 框架是代码优先方法。 必须使用本文档中列出的选项(如 CETAS 或 COPY/数据工厂)迁移数据。
利用适用于 Microsoft Fabric 数据仓库的 dbt 适配器,只需进行简单的配置更改即可将针对不同平台(如 Synapse 专用 SQL 池、Snowflake、Databricks、Google Big Query 或 Amazon Redshift)的现有 DBT 项目迁移到 Fabric 仓库。
若要开始使用面向 Fabric Warehouse 的 dbt 项目,请参阅教程:为 Fabric 数据仓库设置 dbt。 本文档还列出了在不同仓库/平台之间移动的选项。
将数据引入 Fabric 仓库
若要引入 Fabric Warehouse,请使用 COPY INTO 或 Fabric Data Factory,具体取决于自己的偏好。 鉴于先决条件是文件已提取到 Azure Data Lake Storage (ADLS) Gen2,这两种方法都是推荐且性能最佳的选项,因为它们具有等效的性能吞吐量。
需要注意的几个因素,以便设计过程以获得最佳性能:
- 使用 Fabric,将多个表从 ADLS 同时加载到 Fabric 仓库时不会发生任何资源争用。 因此,在加载并行线程时不会出现性能下降。 最大引入吞吐量完全取决于 Fabric 容量的计算能力。
- Fabric 工作负荷管理可分离为加载和查询分配的资源。 当查询和数据加载同时执行时,不存在资源争用的情况。