本文提供 Power BI 语义模型模式的技术说明。 它适用于表示与外部托管 Analysis Services 模型的实时连接的语义模型,也适用于在 Power BI Desktop 中开发的模型。 本文强调了每种模式的理由,以及对 Power BI 容量资源的潜在影响。
三种语义模型模式包括:
导入模式
导入 模式是用于开发语义模型的最常见模式。 由于采用内存查询,此模式可实现快速性能。 它还为建模者提供设计灵活性,并支持特定的 Power BI 服务功能(Q&A、Quick Insights 等)。 由于这些优势,在创建新的 Power BI Desktop 解决方案时,这是默认模式。
请务必了解导入的数据始终存储到磁盘。 查询或刷新时,必须将数据完全加载到 Power BI 容量的内存中。 在内存中后,导入模型可以实现非常快的查询结果。 请务必了解,导入模型不可能部分加载到内存中。
刷新时,数据将压缩和优化,然后由 VertiPaq 存储引擎存储到磁盘。 从磁盘加载到内存中时,可以看到 10 次压缩。 因此,可以合理地期望 10 GB 的源数据可以压缩到大约 1 GB 的大小。 磁盘上的存储大小可以实现比压缩后大小减少 20%。 可以通过将 Power BI Desktop 文件大小与文件的任务管理器内存使用情况进行比较来确定大小差异。
可以通过三种方式实现设计灵活性:
- 通过缓存数据流中的数据以及外部数据源(无论数据源类型或格式如何)来集成数据。
- 创建数据准备查询时,请使用整个 Power Query M 公式语言 的函数(称为 M)。
- 使用业务逻辑增强模型时,应用整个 数据分析表达式 (DAX) 函数集。 支持计算列、计算表和度量值。
如下图所示,导入模型可以集成任意数量的受支持数据源类型中的数据。

但是,尽管导入模型具有令人信服的优势,但也有缺点:
- 必须先将整个模型加载到内存中,然后 Power BI 才能查询模型,这可能会给可用容量资源施加压力,尤其是在导入模型的数量和大小增长时。
- 导入的模型需要刷新,因为模型数据的当前性仅与最新刷新状态一致,通常按计划进行刷新。
- 完全刷新会删除所有表中的所有数据,并从数据源重新加载数据。 在 Power BI 服务和数据源方面,此操作在时间和资源上可能耗费较高。
注释
Power BI 可以实现增量刷新,以避免截断和重新加载整个表。 有关详细信息,包括支持的计划和许可,请参阅 语义模型的增量刷新和实时数据。
从 Power BI 服务资源的角度来看,导入模型需要:
- 查询或刷新时需要足够的内存来加载模型。
- 处理资源和额外的内存资源以刷新数据。
DirectQuery 模式
DirectQuery 模式是导入模式的替代方法。 在 DirectQuery 模式下开发的模型不会导入数据。 相反,它们只包含定义模型结构的元数据。 当对模型进行查询时,将使用原生查询从基础数据源中检索数据。

考虑开发 DirectQuery 模型有两个主要原因:
- 当数据量过大时,即使应用了数据缩减方法,仍然难以上载到模型中或实用地进行刷新。
- 当报表和仪表板需要提供近乎实时的数据时,这超出了计划刷新限制所能实现的范围。 计划刷新限制是共享容量的每天 8 次,高级容量每天 48 次。
与 DirectQuery 模型关联的几个优点:
- 导入模型大小限制不适用。
- 模型不需要计划的数据刷新。
- 报表用户在与报表筛选器和切片器交互时会看到最新的数据。 此外,报表用户可以刷新整个报表以检索当前数据。
- 可以使用 “自动页面刷新 ”功能开发实时报表。
- 仪表板磁贴(基于 DirectQuery 模型)可以每隔 15 分钟自动更新一次。
但是,DirectQuery 模型存在一些限制:
- Power Query/Mashup 表达式只能是可以转换为数据源能够理解的本机查询的函数。
- DAX 公式限于仅使用可以转换为数据源可理解的本机查询的函数。 不支持计算表。
- 不支持快速见解功能。
从 Power BI 服务资源的角度来看,DirectQuery 模型需要:
- 查询模型时,仅加载模型(元数据)的最小内存。
- 有时,Power BI 服务必须使用重要的处理器资源来生成和处理发送到数据源的查询。 出现这种情况时,可能会影响吞吐量,尤其是在并发用户查询模型时。
有关详细信息,请参阅 Power BI Desktop 中的 DirectQuery。
复合模式
复合 模式可以混合使用 Import 和 DirectQuery 模式,或集成多个 DirectQuery 数据源。 在复合模式下开发的模型支持为每个模型表配置存储模式。 此模式还支持使用 DAX 定义的计算表。
表存储模式可配置为 Import、DirectQuery 或 Dual。 配置为双存储模式的表同时支持“Import”和“DirectQuery”,此设置允许 Power BI 服务逐个查询地确定使用最有效的模式。

复合模型努力提供最佳的导入和 DirectQuery 模式。 正确配置后,它们可以将内存中模型的高查询性能与从数据源中检索准实时数据的能力相结合。
有关详细信息,请参阅 Power BI Desktop 中的“使用复合模型”。
纯导入表和 DirectQuery 表
开发复合模型的数据建模者很可能在导入或双存储模式下配置维度类型表,在 DirectQuery 模式下配置事实类型表。 有关模型表角色的详细信息,请参阅 了解星型架构以及 Power BI 的重要性。
例如,考虑一个模型,其中有一个采用双模式的 产品 维度类型表和一个在 DirectQuery 模式下的 销售 事实类型表。 可以从内存中高效快速查询 Product 表以呈现报表切片器。 还可以使用相关的 Product 表在 DirectQuery 模式下查询 Sales 表。 后一个查询可以生成一个高效的本机 SQL 查询,该查询联接 Product 和 Sales 表,并按切片器值筛选。
混合表
开发复合模型的数据建模者还可以将事实数据表配置为混合表。 混合表是包含一个或多个 Import 分区和一个 DirectQuery 分区的表。 混合表的优点是,它可以从内存中高效快速查询,同时包括上次导入周期后发生的数据源的最新数据更改,如以下可视化效果所示。
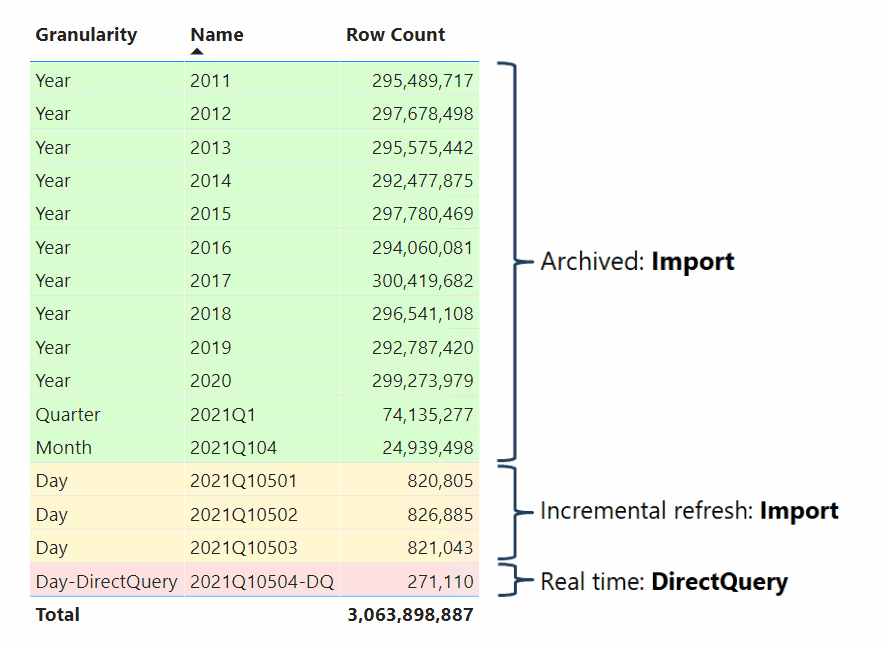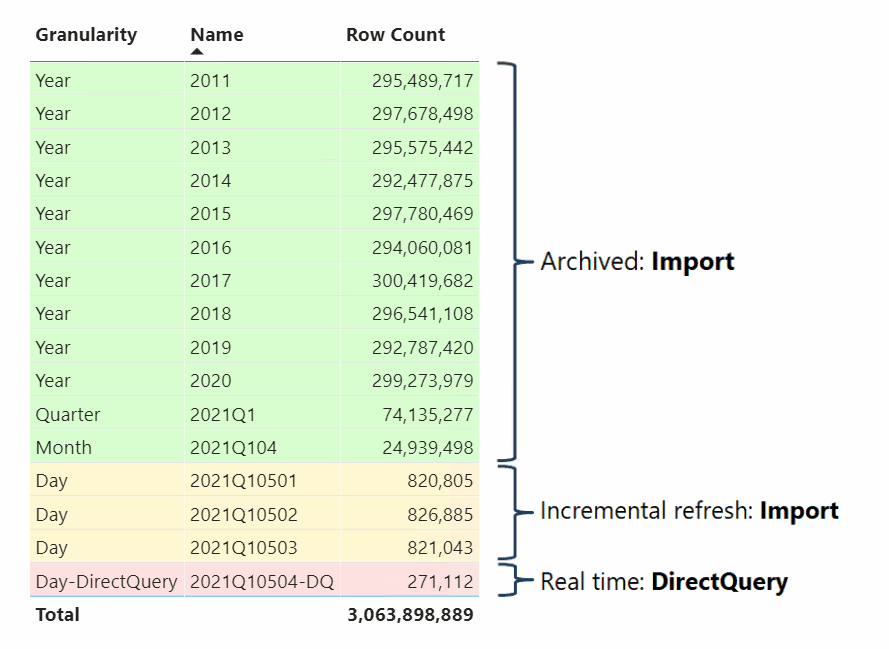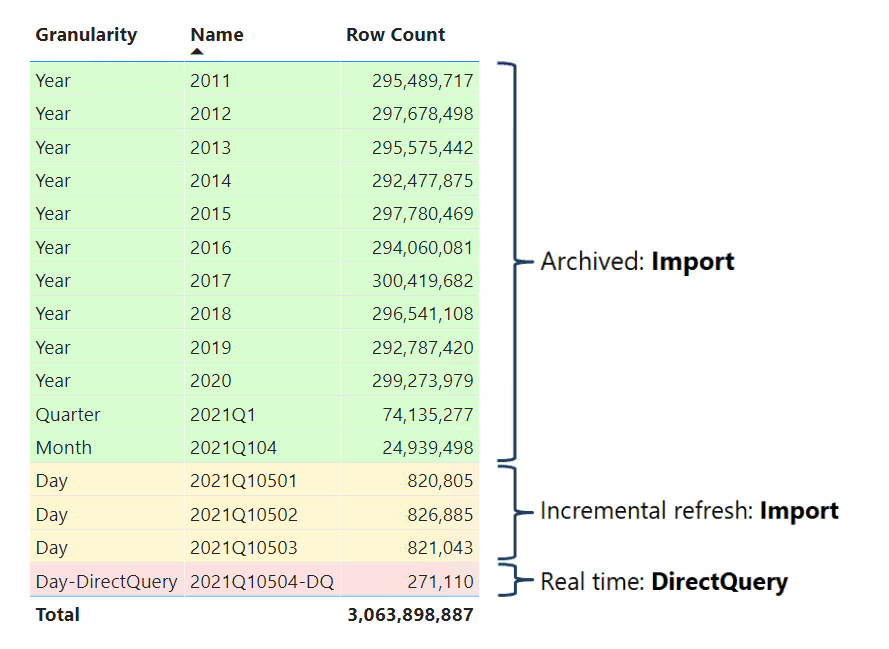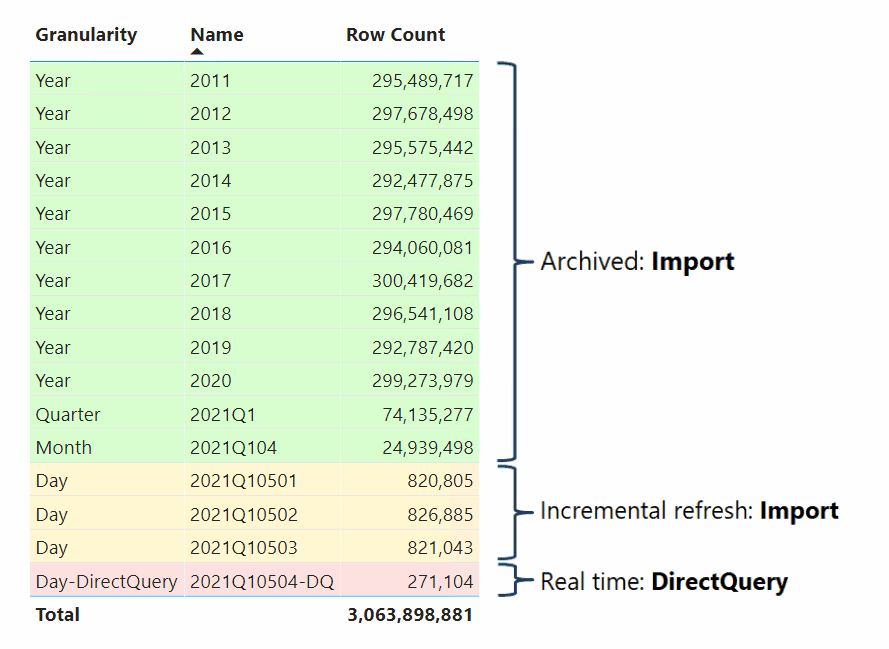
创建混合表的最简单方法是在 Power BI Desktop 中配置增量刷新策略,并使用 DirectQuery(仅限高级)实时启用“获取最新数据”选项。 当 Power BI 应用启用了此选项的增量刷新策略时,它会对表进行分区,如上图中显示的分区方案。 为了确保良好的性能,请在双存储模式下配置维度类型表,以便 Power BI 可以在查询 DirectQuery 分区时生成高效的本机 SQL 查询。
注释
仅当语义模型托管在高级容量的工作区中时,Power BI 才支持混合表。 因此,如果将增量刷新策略配置为使用 DirectQuery 实时获取最新数据的选项,则必须将语义模型上传到高级工作区。 有关详细信息,请参阅 语义模型的增量刷新和实时数据。
还可以通过使用表格模型脚本语言(TMSL)或表格对象模型(TOM)或使用第三方工具添加 DirectQuery 分区,将导入表转换为混合表。 例如,可以对事实数据表进行分区,以便大部分数据保留在数据仓库中,而仅导入最新数据的一小部分。 如果大部分数据是不经常访问的历史数据,此方法有助于优化性能。 混合表可以有多个导入分区,但只能有一个 DirectQuery 分区。