重要
Power Query 连接器支持最初作为限量公开预览引入,并遵循Microsoft Azure 预览补充使用条款,但现已终止。 如果有使用 Power Query 连接器的搜索解决方案,请迁移到备用解决方案。
在 2022 年 11 月 28 日之前迁移
Power Query 连接器预览版于 2021 年 5 月发布,不会推进正式发布。 以下迁移指南适用于 Snowflake 和 PostgreSQL。 如果您使用的是其他连接器且需要迁移说明,请使用在预览注册中提供的电子邮件联系信息请求帮助,或向 Azure 支持部门提交工单。
先决条件
- 一个 Azure 存储帐户。 如果你还没有存储帐户,请创建一个存储帐户。
- Azure 数据工厂。 如果没有,请创建一个数据工厂。 在实现之前,请参阅 数据工厂管道定价 ,了解相关的成本。 此外, 请通过示例检查数据工厂定价。
迁移 Snowflake 数据管道
本部分介绍如何将数据从 Snowflake 数据库复制到 Azure 认知搜索索引。 没有从 Snowflake 直接编制索引到 Azure 认知搜索的过程,因此本部分包括将数据库内容复制到 Azure 存储 Blob 容器的过渡阶段。 然后你将使用 数据工厂管道对该暂存容器进行索引。
步骤 1:检索 Snowflake 数据库信息
转到 Snowflake 并登录到 Snowflake 帐户。 Snowflake 帐户看起来像 https://< account_name.snowflakecomputing.com>。
登录后,请从左窗格中收集以下信息。 在下一步中,你将使用此信息:
- 在 “数据”中,选择 “数据库 ”并复制数据库源的名称。
- 在 “管理员”中,选择 “用户和角色 ”,并复制用户的名称。 确保用户具有读取权限。
- 在 “管理员”中,选择 “帐户 ”并复制帐户的 LOCATOR 值。
- 从 Snowflake URL 中,类似于
https://app.snowflake.com/<region_name>/xy12345/organization). 复制区域名称。 例如,在https://app.snowflake.com/south-central-us.azure/xy12345/organization中,区域名称为south-central-us.azure。 - 在 “管理员”中,选择 “仓库 ”,并复制与要用作源的数据库关联的仓库的名称。
步骤 2:配置 Snowflake 链接服务
使用 Azure 帐户登录到 Azure 数据工厂工作室 。
选择数据工厂,然后选择“ 继续”。
在左侧菜单中,选择“ 管理 ”图标。

在 “链接服务”下,选择“ 新建”。

在右窗格中的数据存储搜索中,输入“snowflake”。 选择 Snowflake 磁贴,然后选择 “继续”。

使用在上一步中收集的数据填写 “新建链接服务 ”窗体。 帐户名称包括定位符值和区域(例如:
xy56789south-central-us.azure) 。
表单完成后,选择“ 测试连接”。
如果测试成功,请选择“ 创建”。
步骤 3:配置 Snowflake 数据集
在左侧菜单中,选择 “创作” 图标。
选择 “数据集”,然后选择“数据集操作省略号”菜单(
...)。
选择 “新建数据集”。

在右侧窗格的数据存储搜索栏中,输入“snowflake”。 选择 Snowflake 磁贴,然后选择 “继续”。

在 “设置属性”中:
- 选择在 步骤 2 中创建的链接服务。
- 选择要导入的表,然后选择“ 确定”。

选择“保存”。
步骤 4:在 Azure 认知搜索中创建新的索引
在 Azure 认知搜索服务中创建新的索引,其架构与当前为 Snowflake 数据配置的架构相同。
可以重新调整当前用于 Snowflake Power Connector 的索引。 在 Azure 门户中,找到索引,然后选择“索引定义”(JSON)。 选择定义并将其复制到新索引请求的正文。

步骤 5:配置 Azure 认知搜索链接服务
在左侧菜单中,选择“ 管理 ”图标。
在 “链接服务”下,选择“ 新建”。
在右窗格中的数据存储搜索中,输入“search”。 选择 Azure 搜索 磁贴,然后选择 “继续”。

填写 “新建链接服务 ”值:
- 选择 Azure 认知搜索服务所在的 Azure 订阅。
- 选择包含您的 Power Query 连接器索引器的 Azure 认知搜索服务。
- 选择 创建。

步骤 6:配置 Azure 认知搜索数据集
在左侧菜单中,选择“作者”图标。
选择 数据集,然后选择数据集操作的省略号菜单(
...)。
选择 “新建数据集”。
在右窗格的“数据存储搜索”中,输入“search”。 选择 Azure 搜索 磁贴,然后选择 “继续”。

在 “设置属性”中:
选择“保存”。

步骤 7:配置 Azure Blob 存储链接服务
在左侧菜单中,选择“ 管理 ”图标。
在 “链接服务”下,选择“ 新建”。
在右侧窗格中的数据存储搜索栏中,输入“存储”。 选择 Azure Blob 存储 磁贴,然后选择 “继续”。

填写 “新建链接服务 ”值:
选择身份验证类型:SAS URI。 只有此身份验证类型可用于将数据从 Snowflake 导入 Azure Blob 存储。
为要用于暂存的存储帐户生成 SAS URL。 将 Blob SAS URL 粘贴到 SAS URL 字段中。
选择 创建。

步骤 8:配置存储数据集
在左侧菜单中,选择作者图标。
选择 “数据集”,然后选择数据集操作的省略号菜单(
...)。
选择 “新建数据集”。
在右窗格中的数据存储搜索中,输入“存储”。 选择 Azure Blob 存储 磁贴,然后选择 “继续”。

选择 DelimitedText 格式,然后选择 “继续”。
在 “设置属性”中:
在 “链接服务”下,选择 在步骤 7 中创建的链接服务。
在 文件路径 下,选择将成为暂存进程的接收器的容器,然后选择确定。

在行分隔符中,选择换行符 (\n)。
选中 “第一行”作为标题 框。
选择“保存”。

步骤 9:配置管道
在左侧菜单中,选择作者图标。
选择 “流水线”,然后选择“流水线行动”菜单(
...)。
选择“新建管道”。

创建和配置 数据工厂活动,用于将数据从 Snowflake 复制到 Azure 存储容器。
展开 “移动和转换 ”部分,然后将 “复制数据” 活动拖放到空白管道编辑器画布。

打开“ 常规 ”选项卡。接受默认值,除非需要自定义执行。
在“ 源 ”选项卡中,选择 Snowflake 表。 保留剩余选项的默认值。

在「接收器」选项卡中:
选择在步骤 8 中创建的存储 DelimitedText 数据集。
在 文件扩展名中,添加 .csv。
保留剩余选项的默认值。

选择“保存”。
请配置将数据从 Azure 存储 Blob 复制到搜索索引的相关任务。
展开 “移动和转换 ”部分,然后将 “复制数据” 活动拖放到空白管道编辑器画布。

在 “常规 ”选项卡中,接受默认值,除非需要自定义执行。
在“源”选项卡中:
- 选择在步骤 8中创建的存储数据集 DelimitedText。
- 在 “文件路径类型 ”中,选择 通配符文件路径。
- 保留所有剩余字段的默认值。
在 “汇聚点” 选项卡中,选择 Azure 认知搜索索引。 保留剩余选项的默认值。

选择“保存”。
步骤 10:配置活动顺序
在管道画布编辑器中,选择管道活动磁贴边缘的小绿色方块。 将其拖到“从存储帐户到 Azure 认知搜索的索引”活动以设置执行顺序。
选择“保存”。

步骤 11:添加管道触发器
选择 “添加触发器 ”以计划管道运行,然后选择“ 新建/编辑”。

从“ 选择触发器 ”下拉列表中,选择“ 新建”。

查看触发器选项以运行管道并选择“ 确定”。

选择“保存”。
选择发布。

迁移 PostgreSQL 数据管道
本部分介绍如何将数据从 PostgreSQL 数据库复制到 Azure 认知搜索索引。 无法将 PostgreSQL 直接索引到 Azure 认知搜索,因此本部分包含将数据库内容复制到 Azure 存储 Blob 容器的过渡阶段。 你将使用 数据工厂管道从该暂存容器创建索引。
步骤 1:配置 PostgreSQL 链接服务
使用 Azure 帐户登录到 Azure 数据工厂工作室 。
选择数据工厂,然后选择 “继续”。
在左侧菜单中,选择“ 管理 ”图标。
在 “链接服务”下,选择“ 新建”。
在右窗格中的数据存储搜索中,输入“postgresql”。 选择表示 PostgreSQL 数据库所在的位置(Azure 或其他)的 PostgreSQL 磁贴,然后选择“ 继续”。 在此示例中,PostgreSQL 数据库位于 Azure 中。

填写 “新建链接服务 ”值:
在 帐户选择方法中选择手动输入。
在 Azure 门户中的 Azure Database for PostgreSQL 概述页中,将以下值粘贴到各自的字段中:
- 将 服务器名称 添加到 完全限定的域名。
- 将 管理员用户名 添加到 用户名。
- 将 数据库 添加到 数据库名称。
- 请输入管理员的用户名和密码到 用户名密码字段。
- 选择 创建。

步骤 2:配置 PostgreSQL 数据集
在左侧菜单中,选择作者图标。
选择 数据集”,然后选择“数据集操作省略号菜单”(
...)。显示如何选择“作者”图标和数据集选项的屏幕截图。
选择 “新建数据集”。
在右窗格中的数据存储搜索中,输入“postgresql”。 选择 Azure PostgreSQL 磁贴。 选择继续。

填写 “设置属性 ”值:
选择 在步骤 1 中创建的 PostgreSQL 链接服务。
选择要导入/索引的表。
选择“确定”。

选择“保存”。
步骤 3:在 Azure 认知搜索中创建新的索引
在 Azure 认知搜索服务中创建新的索引,其架构与 PostgreSQL 数据所用的架构相同。
可以重新调整当前用于 PostgreSQL Power Connector 的索引。 在 Azure 门户中,找到索引,然后选择“索引定义”(JSON)。 选择定义并将其复制到新索引请求的正文。

步骤 4:配置 Azure 认知搜索链接服务
在左侧菜单中,选择“ 管理 ”图标。
在 “链接服务”下,选择“ 新建”。
在右窗格的数据库搜索中,输入“搜索”。 选择 “Azure 搜索 ”磁贴,然后选择“ 继续”。
填写 “新建链接服务 ”值:
- 选择您的 Azure 认知搜索服务所在的 Azure 订阅。
- 选择包含 Power Query 连接器索引器的 Azure 认知搜索服务。
- 选择 创建。
步骤 5:配置 Azure 认知搜索数据集
在左侧菜单中,选择作者图标。
选择 “数据集”,然后选择“数据集操作省略号”菜单(
...)。
选择 “新建数据集”。
在右窗格中的数据存储搜索中,输入“搜索”。 选择 Azure 搜索 磁贴,然后选择 “继续”。
在 “设置属性”中:
选择“保存”。

步骤 6:配置 Azure Blob 存储链接服务
在左侧菜单中,选择“ 管理 ”图标。
在 “链接服务”下,选择“ 新建”。
在右侧窗格的数据存储搜索栏中,输入“存储”。 选择 Azure Blob 存储 磁贴,然后选择 “继续”。
填写 “新建链接服务 ”值:
选择 身份验证类型: SAS URI。 只有此方法可用于将数据从 PostgreSQL 导入 Azure Blob 存储。
为要用于暂存的存储帐户生成 SAS URL,并将 Blob SAS URL 复制到 SAS URL 字段。
选择 创建。
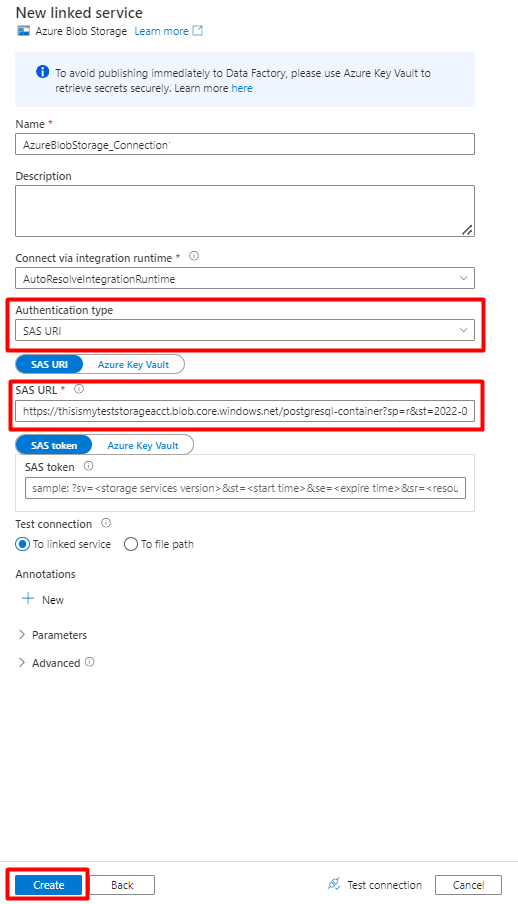
步骤 7:配置存储数据集
在左侧菜单中,选择作者图标。
选择数据集,然后选择“数据集操作”省略号菜单(
...)。
选择 “新建数据集”。
在右窗格中的数据存储搜索中,输入“存储”。 选择 Azure Blob 存储 磁贴,然后选择 “继续”。
选择 DelimitedText 格式,然后选择 “继续”。
在行分隔符中,选择换行符(\n)。
勾选“第一行作为标题行”框。
选择“保存”。

步骤 8:配置管道
在左侧菜单中,选择作者图标。
选择 “管道”,然后选择“管道操作省略号”菜单(
...)。
选择“新建管道”。
创建和配置 数据工厂活动,将数据从 PostgreSQL 复制到 Azure 存储容器。
展开 “移动和转换 ”部分,然后将 “复制数据” 活动拖放到空白管道编辑器画布。

打开“ 常规 ”选项卡,接受默认值,除非需要自定义执行。
在 “源 ”选项卡中,选择 PostgreSQL 表。 保留剩余选项的默认值。

在 “接收器”选项卡中:
选择 在步骤 7 中配置的存储 DelimitedText PostgreSQL 数据集。
在 文件扩展名中,添加 .csv
保留剩余选项的默认值。

选择“保存”。
配置复制数据从 Azure 存储到搜索索引的活动:
展开 “移动和转换 ”部分,然后将 “复制数据” 活动拖放到空白管道编辑器画布。

在“ 常规 ”选项卡中,保留默认值,除非需要自定义执行。
在“源”选项卡中:
- 选择 步骤 7 中配置的存储源数据集。
- 在 “文件路径类型 ”字段中,选择 通配符文件路径。
- 保留所有剩余字段的默认值。

在输出选项卡中,选择 Azure 认知搜索索引。 保留剩余选项的默认值。

选择“保存”。
步骤 9:配置活动顺序
在管道画布编辑器中,选择管道活动边缘的小绿色方块。 将其拖到“从存储帐户到 Azure 认知搜索的索引”活动以设置执行顺序。
选择“保存”。

步骤 10:添加管道触发器
选择 “添加触发器 ”以计划管道运行,然后选择“ 新建/编辑”。

从“ 选择触发器 ”下拉列表中,选择“ 新建”。
查看触发器选项以运行管道并选择“ 确定”。

选择“保存”。
选择发布。

Power Query 连接器预览版的遗留内容
Power Query 连接器与搜索索引器一起使用,以自动从各种数据源引入数据,包括其他云提供商上的数据引入。 它使用 Power Query 检索数据。
预览版支持的数据源包括:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Salesforce 对象
- Salesforce 报表
- Smartsheet
- 雪花
支持的功能
Power Query 连接器用于索引器。 Azure 认知搜索中的索引器是一个爬网程序,它从外部数据源中提取可搜索数据和元数据,并根据索引与数据源之间的字段到字段映射填充索引。 此方法有时称为“拉取模型”,因为服务无需编写向索引添加数据的任何代码即可拉取数据。 索引器为用户提供了一种方便的方法,让用户无需编写自己的爬网程序或推送模型即可从其数据源为内容编制索引。
引用 Power Query 数据源的索引器对技能集、计划、高水印更改检测逻辑的支持级别相同,以及其他索引器支持的大多数参数。
先决条件
虽然不能再使用此功能,但在预览版中,它具有以下要求:
受支持的区域中的 Azure 认知搜索服务。
预览注册。 必须在后端启用此功能。
Azure Blob 存储帐户,用作数据的中介。 数据将从数据源流向 Blob 存储,然后流向索引。 此要求仅在初始封闭预览中存在。
区域可用性
预览版仅适用于以下区域中的搜索服务:
- 美国中部
- 美国东部
- 美国东部 2
- 美国中北部
- 北欧
- 美国中南部
- 美国中西部
- 西欧
- 美国西部
- 西部美国 2
预览限制
本部分介绍特定于当前预览版的限制。
不支持从数据源拉取二进制数据。
不支持调试会话。
开始使用 Azure 门户
Azure 门户为 Power Query 连接器提供支持。 通过在容器上采样数据和读取元数据,Azure 认知搜索中的导入数据向导可以创建默认索引、将源字段映射到目标索引字段,并在单个作中加载索引。 根据源数据的大小和复杂性,您就可以在几分钟内具备完整的全文搜索索引。
以下视频演示如何在 Azure 认知搜索中设置 Power Query 连接器。
步骤 1 – 准备源数据
确保数据源包含数据。 导入数据向导读取元数据并执行数据采样来推断索引架构,但也从数据源加载数据。 如果数据缺失,向导将停止并返回并出错。
步骤 2 – 启动导入数据向导
获得预览版批准后,Azure 认知搜索团队将提供一个使用功能标志的 Azure 门户链接,以便可以访问 Power Query 连接器。 打开此页面,然后通过选择“ 导入数据”从 Azure 认知搜索服务页中的命令栏中启动向导。
步骤 3 - 选择数据源
可以使用此预览版从几个数据源中提取数据。 使用 Power Query 的所有数据源都将在其图块上包含“Power Query 提供支持”。 选择数据源。

选择数据源后,选择“ 下一步:配置数据 以移动到下一部分”。
步骤 4 - 配置数据
在此步骤中,你将配置连接。 每个数据源都需要不同的信息。 对于一些数据源,Power Query 文档提供了有关如何连接到数据的详细信息。
提供连接凭据后,选择“ 下一步”。
步骤 5 - 选择数据
导入向导将预览数据源中可用的各种表。 在此步骤中,你将检查一个表,其中包含要导入到索引中的数据。

选择表后,选择“ 下一步”。
步骤 6 - 转换数据(可选)
Power Query 连接器提供丰富的 UI 体验,使你能够处理数据,从而将正确的数据发送到索引。 可以删除列、筛选行等。
在将数据导入 Azure 认知搜索之前,无需对其进行转换。

有关使用 Power Query 转换数据的详细信息,请参阅 在 Power BI Desktop 中使用 Power Query。
转换数据后,选择“ 下一步”。
步骤 7 - 添加 Azure Blob 存储
Power Query 连接器预览版当前要求你提供 Blob 存储帐户。 此步骤仅在初始封闭预览中存在。 此 Blob 存储帐户将用作从数据源移动到 Azure 认知搜索索引的数据的临时存储。
我们建议提供具备完全访问权限的存储帐户连接字符串:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
可以通过导航到 Azure 门户中的存储帐户边栏选项卡 > 设置 > 密钥(适用于经典存储帐户)或设置 > 访问密钥(适用于 Azure 资源管理器存储帐户)来获取连接字符串。
提供数据源名称和连接字符串后,选择“下一步:添加认知技能(可选)”。
步骤 8 - 添加认知技能(可选)
AI 扩充 是索引器的扩展,可用于使内容更具可搜索性。
可以添加任何能给您的方案带来益处的增强。 完成后,选择“ 下一步:自定义目标索引”。
步骤 9 - 自定义目标索引
在“索引”页上,应会看到包含数据类型的字段列表,以及用于设置索引属性的一系列复选框。 向导可以根据元数据和源数据采样生成字段列表。
可以通过选中属性列顶部的复选框来批量选择属性。 对于应返回到客户端应用并接受全文搜索处理的每个字段,请选择“可检索和可搜索”。 你会注意到整数不是全文或模糊可搜索的(数字是逐字计算的,在筛选器中通常很有用)。
有关详细信息,请查看索引属性和语言分析器的说明。
花点时间查看你的选择。 运行向导后,将创建物理数据结构,并且无法在不删除和重新创建所有对象的情况下编辑这些字段的大部分属性。

完成后,选择“ 下一步:创建索引器”。
步骤 10 - 创建索引器
最后一步创建索引器。 命名索引器可将其作为独立资源存在,可以独立于在同一向导序列中创建的索引和数据源对象进行计划和管理。
导入数据向导的输出是一个索引器,可对数据源进行爬网,并将所选数据导入到 Azure 认知搜索上的索引中。
创建索引器时,可以选择按计划运行索引器并添加更改检测。 若要添加更改检测,请指定“高水印”列。

填写完此页面后,选择“ 提交”。
高水位标识变更检测策略
此更改检测策略依赖于一个“高水印”列,该列记录行的最新更新时的版本号或时间戳。
要求
- 所有插入都为列指定一个值。
- 对某个项目的所有更新也会更改该列的值。
- 此列的值随每次插入或更新而增加。
不支持的列名称
Azure 认知搜索索引中的字段名称必须满足某些要求。 其中一项要求是不允许某些字符(如“/”)。 如果数据库中的列名不符合这些要求,则索引架构检测不会将列识别为有效的字段名称,并且不会看到该列作为索引的建议字段列出。 通常,使用 字段映射 可以解决此问题,但门户中不支持字段映射。
若要为表中具有不受支持的字段名称的列的内容编制索引,请在导入数据过程的“转换数据”阶段重命名该列。 例如,可以将名为“计费代码/邮政编码”的列重命名为“zipcode”。 通过重命名列,索引架构检测会将它识别为有效的字段名称,并将其作为建议添加到索引定义。
后续步骤
本文介绍了如何使用 Power Query 连接器拉取数据。 由于此预览版功能已停用,因此还介绍了如何将现有解决方案迁移到受支持的方案。
若要了解有关索引器的详细信息,请参阅 Azure 认知搜索中的索引器。