描述关键性能指标
让我们了解如何在 Azure Monitor 中创建指标,以便触发警报或执行自动错误响应。
检查 Azure 指标
Azure Monitor 服务可跟踪指定资源总体运行状况的各种指标。 定期收集的指标是警报程序的关键接口,有助于快速高效地解决问题。 Azure Monitor Metrics 是功能强大的子系统,不仅可以分析和可视化性能数据,还可以触发警报来通知管理员,或触发自动操作来触发 Azure 自动化 Runbook 或 Webhook。 还可以将 Azure 指标数据存档到 Azure 存储,因为活动数据仅存储 93 天。
创建指标警报
通过 Azure 门户,可以在 Azure Monitor 边栏选项卡的概述部分中基于定义的指标创建警报规则。 可以通过三种方式为 Azure Monitor 警报设定范围。 例如,以 Azure 虚拟机为例,可将范围指定为:
单个订阅内的虚拟机列表(在单个 Azure 区域中)
指定为单个订阅中一个或多个资源组中的所有虚拟机(在单个 Azure 区域中)
指定为单个订阅中的所有虚拟机(在单个 Azure 区域中)
通过这种方式,可以基于资源组中包含的资源创建警报规则,如下所示。

以下示例演示如何为名为 SQL2019 的虚拟机创建警报,重点介绍单个虚拟机的范围。

无论警报的范围如何,创建过程均相同。
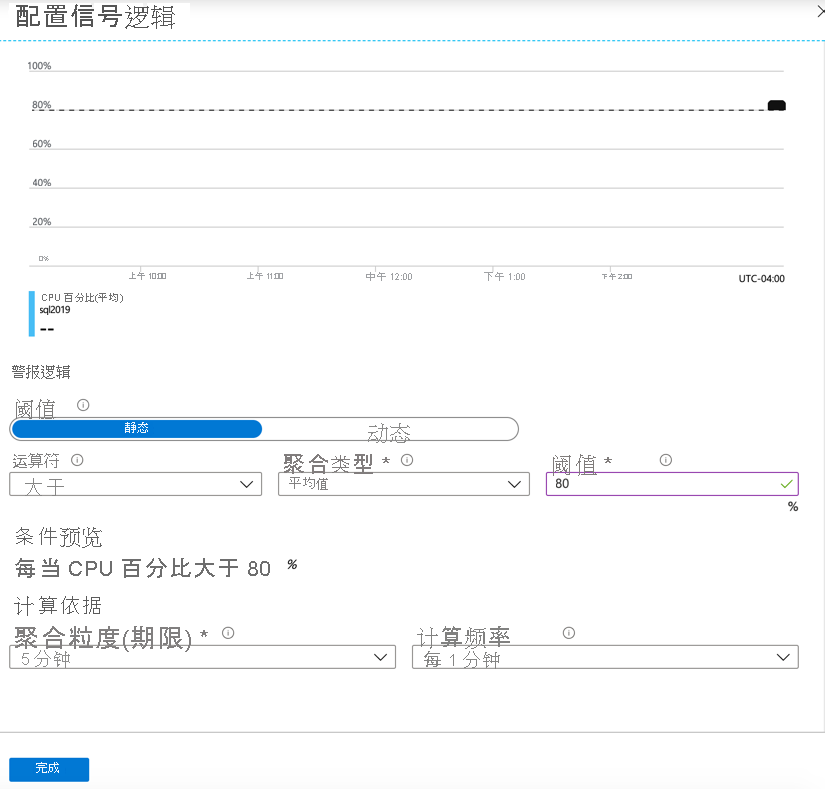
在警报屏幕中,选择“ 新建警报规则”。 如果警报是在资源范围内创建的,则资源值应自动填充。 可以看到资源是 SQL2019 虚拟机,订阅是 开发测试实验室 ,其所在的资源组是 SQLPlayground。
在“条件”部分下,选择“ 添加:

选择要为其设定警报的指标。 下图显示了“CPU 百分比”,随后你会看到它已被选中。

可以以静态方式配置警报(例如,CPU 利用率超过 95% 时发出警报),也可以使用动态阈值以动态方式配置警报。 动态阈值可以学习指标的历史行为,并且可以在资源运行异常时发出警报。 这些动态阈值可以检测工作负载的季节性变化并相应地调整警报。
如果使用静态警报,则必须为所选指标提供阈值。 在本示例中,指定为 80%。 此阈值表示,如果 CPU 使用率在给定时间段内超过 80%,则会触发警报并按指定做出响应。
两种类型的警报均提供布尔运算符,例如“大于”或“小于”运算符。 除布尔运算符外,还可以选择聚合度量值,例如平均值、最小值、最大值、计数、平均值和总数。 使用这些选项可轻松构造出适合几乎所有企业级警报的灵活警报。
创建警报后,为了通知管理员或启动自动化过程,需要配置一个操作组。
定义行动组是可选的,如果未配置行动组,警报将只把通知记录到存储中,而无需执行进一步操作。 可以在指标屏幕上,选择“操作组”旁边的“添加”来创建新的操作组。

选择“ 创建作组”后,会看到以下屏幕。 您为操作组命名,并定义警报和响应。 在此示例中,如果触发警报条件,管理员将收到电子邮件通知。

可以通过在“配置”下选择“编辑详细信息”,或者添加新操作来配置电子邮件或短信的详细信息,这也会显示配置屏幕。

在操作组中,可以通过多种方式来响应警报。 以下选项可用于定义要采取的措施:
- 自动化 Runbook
- Azure 函数
- 向 Azure 资源管理器角色发送电子邮件
- 电子邮件/短信/推送/语音
- ITSM
- Azure 逻辑应用
- 安全 Webhook
- Webhook
这些操作有两类:通知,即通知管理员或管理员组某个事件,自动化是指执行已定义的操作以响应性能条件。
查看过去的性能数据
利用 Azure Monitor 的好处之一是能够轻松快速地检查过去收集的指标。 当你检查资源时,会注意到右上角的日期时间选择器。 Azure Monitor 指标将保留 93 天,之后会将其清除,但可以选择将其存档到 Azure 存储。

还可以选择较小的时间窗口,例如过去 30 分钟、最后一小时、过去 4 小时或过去 12 小时,例如。 Azure Monitor 的灵活性使管理员能够快速识别问题,并可能诊断过去的问题。
重要的 SQL Server 指标
Microsoft SQL Server 是仪表化的软件,可收集大量性能元数据。 数据库引擎具有可监视的指标,用于帮助识别和优化与性能相关的问题。 某些操作系统指标只能通过性能监视器查看,而其他操作系统指标则可通过 T-SQL 查询访问(特别地,从动态管理视图 (DMV) 中进行选择)。 两个位置都公开了一些指标,因此知道在哪个位置标识特定指标很重要。 只能从 DMV 中捕获的数据的一个示例是 sys.dm_os_volume_stats 中公开的数据和事务日志文件读取/写入延迟。 另一方面,无法直接通过 SQL Server 获取的 OS 指标示例是磁盘卷的每秒读取和写入时间。 结合这两个指标有助于更好地了解性能问题是否与数据库结构或物理存储瓶颈有关。