探索流处理体系结构的常见元素
可使用多种技术来实现流处理解决方案,尽管具体的实现细节可能会有所不同,但大多数流体系结构都有一些通用的元素。
流处理的通用体系结构
最简单地说,流处理的高级体系结构如下所示:
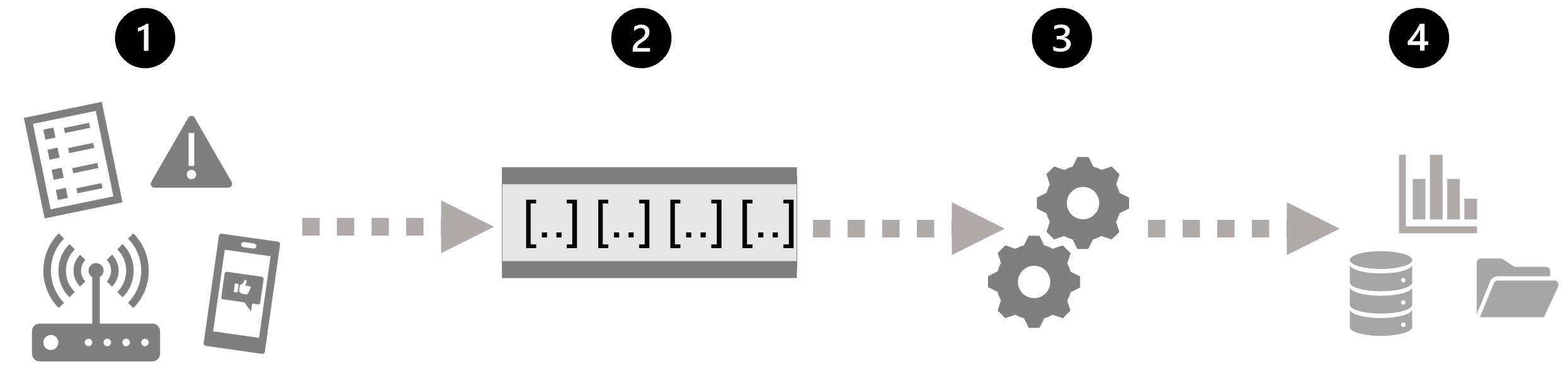
- 事件生成一些数据。 这可能是传感器发出的信号、发布的社交媒体消息、写入的日志文件条目或导致某些数字数据的任何其他事件。
- 将在流式处理源中捕获生成的数据供进行处理。 在简单情况下,该源可能是云数据存储中的文件夹或数据库中的表。 在更可靠的流解决方案中,该源可能是封装逻辑以确保按顺序处理事件数据以及每个事件仅处理一次的“队列”。
- 事件数据通常由永久查询进行处理,该查询对事件数据进行操作,以选择特定类型事件、项目数据值或临时时间段(或窗口)的聚合数据值的数据 - 例如,通过计算每分钟的传感器发射数。
- 流处理操作的结果将写入到输出(或接收器)以供后续下游查询进行进一步处理,该输出(或接收器)可能是文件、数据库表、实时可视化仪表板或其他队列。
实时分析服务
Microsoft 支持多种可用于实现流式处理数据实时分析的技术,其中包括:
- Azure 流分析:一种平台即服务 (PaaS) 解决方案,可用于定义从流源引入数据、应用永久查询并将结果写入到输出的流作业。
- Spark 结构化流式处理:一个开源库,可用于在基于 Apache Spark 的服务(包括 Microsoft Fabric 和 Azure Databricks)上开发复杂的流式处理解决方案。
- Microsoft Fabric:高性能数据库和分析平台,包括数据工程、数据工厂、数据科学、Real-Time 分析、数据仓库和数据库。
流处理的源
通常使用以下服务在 Azure 上引入流处理数据:
- Azure 事件中心:一种数据引入服务,可用于管理事件数据的队列,以确保每个事件按顺序处理一次。
- Azure IoT 中心:类似于 Azure 事件中心的数据引入服务,但已优化以管理来自 物联网 (IoT)设备的事件数据。
- Azure Data Lake Store Gen 2:一种高度可缩放的存储服务,通常用于 批处理 方案,但也可用作流式处理数据源。
- Apache Kafka:一种开源数据引入解决方案,通常与 Apache Spark 一起使用。
流处理的接收器
流处理的输出通常发送到以下服务:
- Azure 事件中心:用于对已处理的数据进行排队,以便进一步进行下游处理。
- Azure Data Lake Store Gen 2、 Microsoft OneLake 或 Azure Blob 存储:用于将处理的结果保留为文件。
- Azure SQL 数据库、 Azure Databricks 或 Microsoft Fabric:用于在表中保存已处理的结果以供查询和分析。
- Microsoft Power BI:用于在报表和仪表板中生成实时数据可视化效果。