Azure HDInsight 的工作原理
在这里,你将了解 Azure HDInsight 的工作原理。 你将了解以下组件及其组合方式,以提供数据管理和管理:
- Apache Hadoop
- HDInsight 存储
- HDInsight 处理
什么是 Apache Hadoop?
Apache Hadoop 是 HDInsight 核心的云分布式数据处理系统。 它有三个组件,下表描述了:
| Apache Hadoop 组件 | DESCRIPTION |
|---|---|
| HDFS(Hadoop分布式文件系统) | Apache Hadoop 分布式文件系统(HDFS)为 Hadoop 系统提供存储。 |
| YARN | Apache Hadoop Yet Another Resource Negotiator (YARN) 组件为系统提供处理。 |
| MapReduce | MapReduce 是一种可以处理和分析数据的编程模型。 |
组件如何交互?
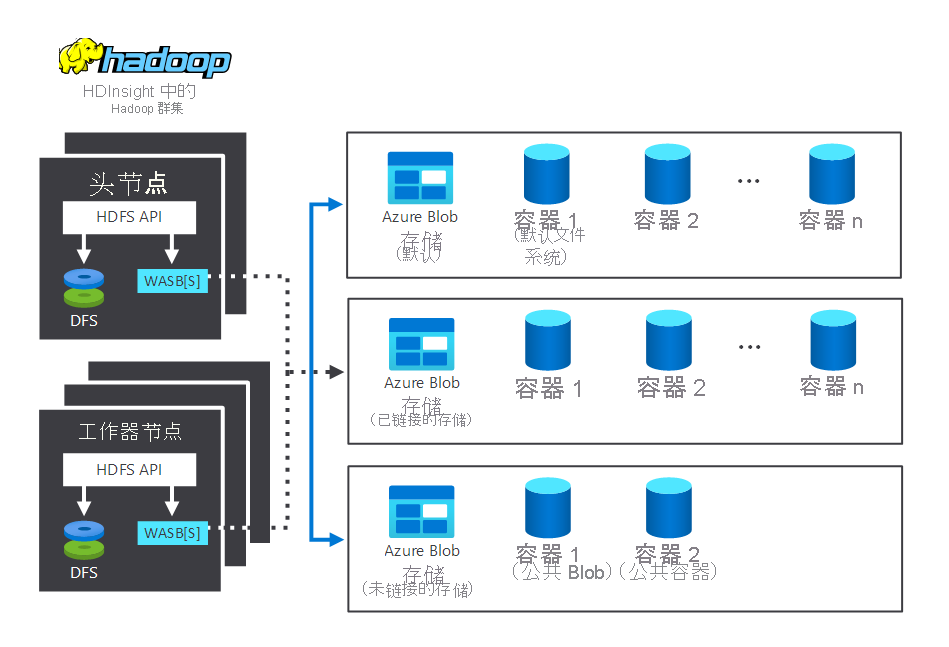
下图描述了在典型的 HDInsight Hadoop 群集中交互的存储和处理组件。 它说明了以下组件:
- 头节点和工作器节点,用于执行处理。
- 节点内的多个 Windows Azure 存储 Blob (WASB) 存储中心。 HDFS 与这些容器交互。
- 多个默认、链接和未链接的存储容器。 它们可用于两个节点。
现在我们来看看存储和处理的工作原理。
存储的工作原理是什么?
预配 HDInsight 群集时,不会自动创建群集的存储组件。 而是由符合 HDFS 的系统(如 Azure 存储或 Azure Data Lake)提供。
将群集的存储组件与处理组件分开有好处。 例如,可以安全地删除仅用于计算的任何 HDInsight 群集,而无需担心丢失数据。 添加 HDInsight 群集时,必须定义默认文件系统。
重要
对于 Azure 存储,必须将 Blob 容器指定为默认文件系统。
提供默认文件系统可确保 HDInsight 在搜索文件时能够解析相对文件引用。
小窍门
若要增加可用存储,可以根据需要链接和取消链接其他文件系统。

处理的工作原理是什么?
处理数据时,HDInsight 上的 Hadoop 群集的计算组件会分为两个逻辑区域。 下表描述了以下两个方面:
| 组件 | DESCRIPTION |
|---|---|
| 头节点 | 头节点接受和管理客户端请求,并将请求传递给工作器节点。 |
| 工作器节点 | 工作节点处理数据。 |
注释
头节点有时称为主节点。
大多数群集包含两个头节点,包括:
- 用于管理客户端连接的活动头节点。
- 被动头节点,如果主动节点脱机,则提供复原能力。

头节点和工作器节点都可以直接连接到本地附加的 HDFS,或者访问存储在 Azure Blob 或 Azure Data Lake 中的数据。 管理的数据取决于两个因素:
- MapReduce 编程模型如何定义如何使用数据
- 头节点如何分配工作
YARN 的作用是什么?
YARN 在 HDInsight 群集中执行资源管理。 处理数据时,此服务管理资源和作业计划。
YARN 位于 HDInsight 群集的 HDFS 和计算系统之间。 它与头节点合作,以帮助在群集的工作节点之间分配作业。 这有助于确保并行执行数据处理作业。