重要
此功能仅适用于公共预览版客户。 预览版中的功能可能不完整,并且可能会在更广的版本中推出之前进行更改。
组织数据可以通过以下三种方式之一显示在 Viva Insights Web 应用中:通过Microsoft Entra ID(默认源);通过作为见解管理员直接上传到 Viva Insights 的单个 .csv 文件;或者通过你、源系统管理员和 Microsoft 365 IT 管理员设置的基于 API 的数据导入。
本文介绍第三个选项,即导入数据。
通过导入,可以通过 zip 文件将数据从源系统引入 Viva Insights HR 数据入口 API。 您可以:
- 创建自定义应用,将数据从源系统导出到 zip 文件。 然后,使用相同的应用,使用以下 API 信息导入该数据。
- 创建自定义应用,将数据从源系统导出到 zip 文件。 然后,运行我们创建的 C# 控制台应用,将数据导入 Viva Insights。
- 创建自定义应用,将数据从源系统导出到 zip 文件。 然后,运行我们创建的 PowerShell 脚本,将数据导入 Viva Insights。
- 使用 Azure 数据工厂 (ADF) 模板将数据发送到基于 API 的导入。
但是,在运行应用并开始将数据传输到 Viva Insights 之前,需要协调 Microsoft 365 管理员与见解管理员 (见解管理员) 之间的一些任务。 有关所需步骤的概述,请参阅 工作流 。
重要
仅当这是首次导入组织数据时,才使用以下步骤。 如果这不是首次导入,请参阅 导入组织数据 (后续导入) 刷新以前导入的数据。
工作流
设置:
- 数据源管理员 生成安全证书 并将其提供给Microsoft 365 管理员。
- Microsoft 365 管理员使用安全证书在 Azure 中注册新应用。
- 使用应用注册中的 ID,见解管理员 设置导入。
- 数据源管理员准备其数据,并执行以下任一作:
- 使用基于 API 的自定义应用从源系统导出数据,然后使用同一应用将数据导入 Viva Insights。
- 使用基于 API 的自定义应用从源系统导出数据,然后使用 C# 解决方案或 PowerShell 脚本将数据导入 Viva Insights。

验证:Viva Insights 验证数据。 (如果验证不成功,可以从 验证失败中所述的几个选项中进行选择。)
处理:Viva Insights 处理数据。 (如果处理不成功,可以从 处理失败中所述的几个选项中进行选择。)

成功验证和处理数据后,整个数据导入任务即完成。
安装
生成安全证书
适用于:数据源管理员
若要开始将数据从源文件中获取到 Viva Insights,Microsoft 365 管理员需要在 Azure 中创建和注册应用。 作为数据源管理员,你需要通过为其提供安全证书来帮助Microsoft 365 管理员注册其应用。
下面是要执行的作:
- 按照本文中的说明创建证书: 创建自签名公共证书对应用程序进行身份验证
- 将生成的证书发送给 Microsoft 365 管理员。
现在就是这样。 如果想要在后续步骤中先行一步,请按照 按设置的频率导出数据中的步骤作。
在 Azure 中注册新应用
适用于:Microsoft 365 管理员
注意
有关在 Azure 中注册应用的详细信息,请参阅快速入门:使用 Microsoft 标识平台注册应用程序。
从Microsoft管理中心的左侧,选择“ 所有管理中心”。 此选项显示为列表中的最后一个选项。

选择“Microsoft Entra ID”。
创建新的应用注册:
在顶部工具栏中,选择“ 添加 > 应用注册”。

在生成的屏幕上:
- 为应用命名。
- 在 “支持的帐户类型”下,将第一个选项保留为“ 此组织目录中的帐户仅 ([仅组织] - 单租户) ”处于选中状态。
- 选择屏幕底部的“ 注册 ”按钮。

返回到 “概述” 屏幕时,请复制 “应用程序 (客户端) ID ”和 “目录 (租户) ID”。

重要
请将这些 ID 放在方便的位置。 稍后需要提供它们。
添加证书:
选择 “添加证书或机密”。

选择 “上传证书”。

上传数据源管理员给你的证书,并添加 “说明”。 选择“添加”按钮。

删除 API 权限:
从左侧选择 “API 权限 ”。
对于每个列出的 API/权限 名称,请选择 API 右侧的省略号 (...) ,例如 ,Microsoft Graph。
选择“ 删除权限”。
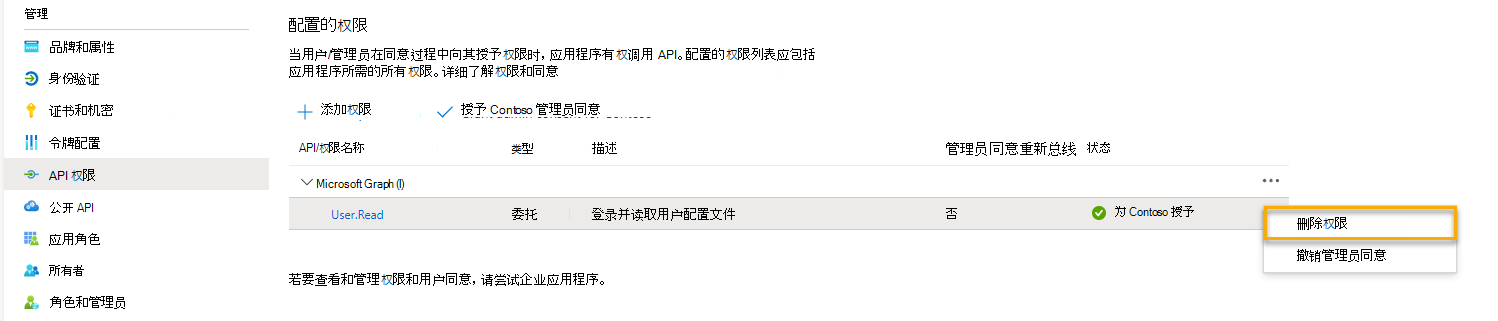
确认删除。
删除这些项目的权限时,可确保应用仅具有所需的权限。
共享在步骤 3c 中记录的 ID:
- 为见解管理员提供应用 ID。
- 为数据源管理员提供应用 ID 和 租户 ID。


在 Viva Insights 中设置导入
适用于:见解管理员
从以下两个位置之一开始导入:“数据连接”下的“数据中心”页或“组织数据”页。
从 数据中心:
- 在 “数据源 ”部分中,找到 “基于 API 的导入 ”选项。 选择“开始”按钮。
从 数据连接:
在“ 当前源”旁边,选择 “数据源” 按钮。
此时将显示 “切换到:基于 API 的导入 ”窗口。 选择“开始”。
在 基于 API 的组织数据导入 页上:
为连接命名。
输入Microsoft 365 管理员提供的应用 ID。
保存。
选择在步骤 3a 中命名的连接作为新数据源。
请与数据源管理员联系,请求他们向 Viva Insights 发送组织数据。
准备、导出和导入组织数据
有关准备数据的提示
- 对于新数据,请包括所有员工的完整历史数据。
- 导入公司中所有员工的组织数据,包括持牌员工和无执照员工。
- 请参阅 示例 .csv 模板 了解数据结构和指南,以避免出现唯一值过多或过少、字段冗余、数据格式无效等常见问题。
按设置的频率导出数据
你决定每月、每周 (一次等 ) 自定义应用将源系统中的组织数据导出为 zip 文件夹,并将其存储在文件中。 此 zip 文件夹基于 此处的 zip 文件夹。 zip 文件夹需要包含 data.csv 文件和metadata.json文件。
下面是有关这些文件及其需要包含的内容的一些更多详细信息:
data.csv
添加要在此文件中导入的所有字段。 请确保根据我们在 准备组织数据中的指南设置格式。
metadata.json
指示要执行的刷新类型以及 Viva Insights 应如何映射字段:
-
"DatasetType": "HR"(第 2 行) 。 保持原样。 -
"IsBootstrap":(第 3 行) 。 使用"true"指示完全刷新,使用"false"指示增量刷新。 -
"ColumnMap":. 如果使用的名称不同于 Viva Insights 使用的名称,请更改每个列标题名称以匹配在源系统中使用的名称。
重要
删除 .csv 文件中不存在的任何字段。
映射示例
以下示例表示 metadata.json 文件中的一个字段:
"PersonId": {
"name": "PersonId",
"type": "EmailType"
-
"PersonId": {对应于源列名称。 -
“name” : “PersonId”,对应于 Viva Insights 字段名称。 -
"type": "EmailType"对应于字段的数据类型。
假设源系统对此字段标头使用 Employee 而不是 PersonId。 若要确保正确映射字段,请编辑下面的第一行,使其如下所示:
"Employee": {
"name": "PersonId",
"type": "EmailType"
上传数据时,字段 Employee 将变为 PersonId Viva Insights 中。
导入数据
若要将数据导入 Viva Insights,可以从四个选项中进行选择:
- 使用我们的 API 生成一个自定义应用,以你选择的频率导出和导入数据。 了解详细信息。
- 在基于 API 的主机上运行我们的 C# 解决方案。 了解详细信息。
- 运行 PowerShell 脚本,该脚本也基于我们的 API。 了解详细信息。
- 使用 Azure 数据工厂 (ADF) 模板将数据发送到基于 API 的导入。 了解详细信息。
注意
我们的 C# 和 PowerShell 解决方案仅将数据导入 Viva Insights。 它们不会从源系统导出数据。
在使用以下任何选项之前,请确保你已获取此信息:
- 应用 (客户端) ID。 在“应用程序 (客户端) ID”下的Azure 门户的已注册应用信息中查找此 ID。
- 客户端密码:这是应用程序在请求令牌时用于证明其身份的机密字符串。 它也称为应用程序密码。 此机密仅在首次创建客户端密码时显示。 若要创建新的客户端密码,请参阅在门户中创建Microsoft Entra应用和服务主体。
- 证书名称。 此名称是在已注册的应用程序中配置的。 上传证书后,证书名称将显示在Azure门户中的“说明”下。 可以使用证书名称作为客户端密码的替代方法。
- zip 文件和 zip 文件的路径。 不要 data.csv 和metadata.json更改文件名。
- Microsoft Entra租户 ID。 另可在应用的“ 目录 (租户) ID”下的“概述”页上找到此 ID。
- 缩放单位:为租户提供的缩放单元,
novaprdwus2-01例如 。
关于 Viva Insights HR 数据入口 API
查看以下命令:
[请求标头]
下面提到的所有 API 都需要这两个请求标头
x-nova-scaleunit: <ScaleUnit obtained from Insights setup connection page>
Authentication: Bearer <Oauth token from AAD>
注意
使用) 为已注册的应用 (守护程序应用身份验证流生成 Active Directory OAuth 令牌:
Authority: https://login.microsoftonline.com
Tenant: <target AAD tenant ID>
Audience: https://api.orginsights.viva.office.com
有关生成令牌的详细信息,请参阅: 使用 Microsoft 身份验证库获取和缓存令牌 (MSAL)
如果为租户设置了连接器,则获取连接器/ping 以检查
[GET] https://api.orginsights.viva.office.com/v1.0/scopes/<tenantId>/ingress/connectors/HR
[ResponseBody]
如果设置了连接器,并且调用方应用程序 (ID) 被授予授权:
200:
{
“ConnectorId”: “Connector-id-guid”
}
如果见解管理员删除了连接器,或者,见解管理员尚未设置连接器:
403: Forbidden.
推送数据
1P/3P 调查应用,用于调用 Viva Insights API 以推送内容
[POST] https://api.orginsights.viva.office.com/v1.0/scopes/<tenantId>/ingress/connectors/HR/ingestions/fileIngestion
[正文] 文件内容为 multipart/form-data
类型: Zip 存档
要存档的内容:
Metadata.json
Data.csv
[请求正文]
Body:
{
"$content-type": "multipart/form-data",
"$multipart":
[
{
"headers":
{
"Content-Disposition": "form-data; name=\"file\"; filename=info"
},
"body": @{body('Get_blob_content_(V2)')}
}
]
}
[响应正文]
200:
{
"FriendlyName": "Data ingress",
"Id": "<ingestion Id>",
"ConnectorId": "<connector Id>",
"Submitter": "System",
"StartDate": "2023-05-08T19:07:07.4994043Z",
"Status": "NotStarted",
"ErrorDetail": null,
"EndDate": null,
"Type": "FileIngestion"
}
如果未设置连接器:
403: Forbidden
如果已设置连接器,但之前的引入尚未完成:
400: Bad request: Previous ingestion is not complete.
轮询状态
用于轮询引入状态的 API,因为数据引入是长时间运行的作。
[GET] https://api.orginsights.viva.office.com/v1.0/scopes/<tenantId>/ingress/connectors/Hr/ingestions/fileIngestion/{ingestionId:guid}
[响应]
200:
{
"FriendlyName": "Data ingress",
"Id": "<ingestion Id>",
"ConnectorId": "<connector Id>",
"Submitter": "System",
"StartDate": "2023-05-08T19:05:44.2171692Z",
"Status": "NotStarted/ExtractionComplete/ValidationFailed
/Completed/",
"ErrorDetail": null,
"EndDate": "2023-05-08T20:09:18.7301504Z",
"Type": "FileIngestion"
},
如果验证失败 (数据) 问题,则下载错误流
[GET] https://api.orginsights.viva.office.com/v1.0/scopes/<tenantId>//Hr/ingestions/{ingestionId}/errors
[响应]
200: File stream with errors, if any.
选项 1:使用 Viva Insights HR 数据入口 API 生成自定义导入/导出应用
可以使用 Viva Insights HR 数据入口 API 生成自定义应用,该应用会自动从源系统导出数据,然后将其导入 Viva Insights。
你的应用可以采用任何形式(例如 PowerShell 脚本),但它需要按选取的频率将源数据导出为 zip 文件夹,将文件夹存储在文件中,并将该文件夹导入 Viva Insights。
选项 2:通过自定义应用导出数据后,通过 C# 解决方案导入数据
按选取的频率将源数据导出为 zip 文件夹并将该文件夹存储在文件中后,可以在主机上运行描述性数据UploadApp C# 解决方案。 然后,通过描述性数据UploadApp C# 解决方案,将本地存储的数据引入 Viva Insights。 在 GitHub 上了解详细信息。
若要运行解决方案,请执行以下作:
通过在命令行中运行以下命令将此应用克隆到计算机:
git clone https://github.com/microsoft/vivainsights_ingressupload.git.包含以下控制台值。 有关 说明,请参阅准备、导出和导入组织数据。
- AppID/ClientID
- 压缩文件的绝对路径。 设置路径的格式,如下所示:
C:\\Users\\JaneDoe\\OneDrive - Microsoft\\Desktop\\info.zip - Microsoft Entra租户 ID
- 证书名称
选项 3:通过自定义应用导出数据后运行描述性数据Upload PowerShell 解决方案
与选项 2 类似,在按选取的频率将源数据导出为 zip 文件夹并将该文件夹存储在文件中后,可以在主机上运行描述性数据Upload PowerShell 解决方案。 然后,描述性数据Upload PowerShell 解决方案会将本地存储的数据引入 Viva Insights。 在 GitHub 上了解详细信息。
通过在命令行中运行以下命令,将源代码克隆到计算机:
git clone https://github.com/microsoft/vivainsights_ingressupload.git以管理员角色打开新的 PowerShell 窗口。
在 PowerShell 窗口中运行以下命令:
Install-Module -Name MSAL.PS或者,转到此 PowerShell 库链接 以获取有关安装的说明。
设置参数。 有关说明 ,请参阅准备、导出和导入组织数据 。
ClientIDpathToZippedFileTenantIdnovaScaleUnitingressDataType: HR-
ClientSecret或certificateName
选项 4:使用Azure 数据工厂 (ADF) 模板将数据发送到基于 API 的导入
1. 创建新Azure 数据工厂
创建新的数据工厂或使用现有数据工厂。 完成字段,然后选择“ 创建”。

2.创建新的管道和活动
创建新管道并输入管道的名称。
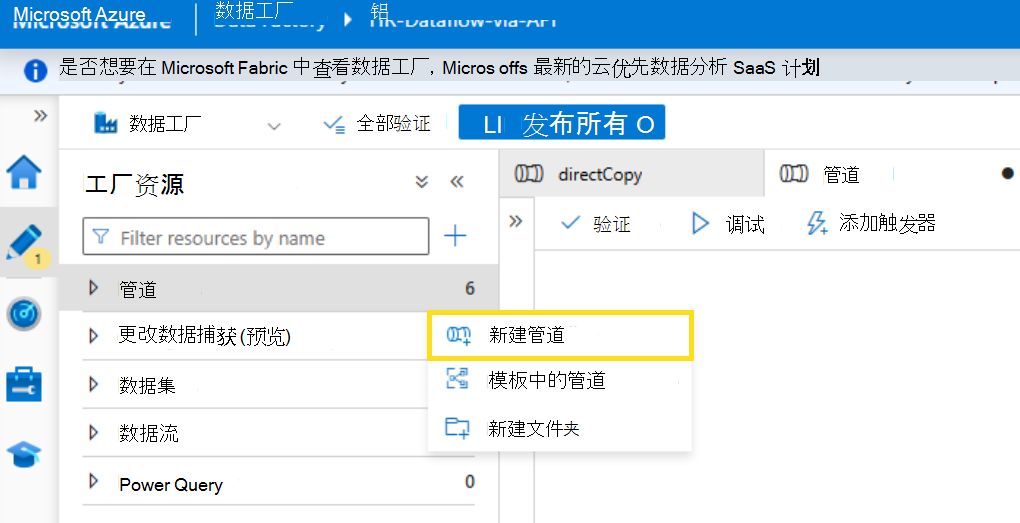
在 “活动”下,添加 “复制数据”。

3. 复制数据活动设置:常规
选择 “复制数据 ”活动,然后选择“ 常规 ”以使用以下指南完成每个字段。
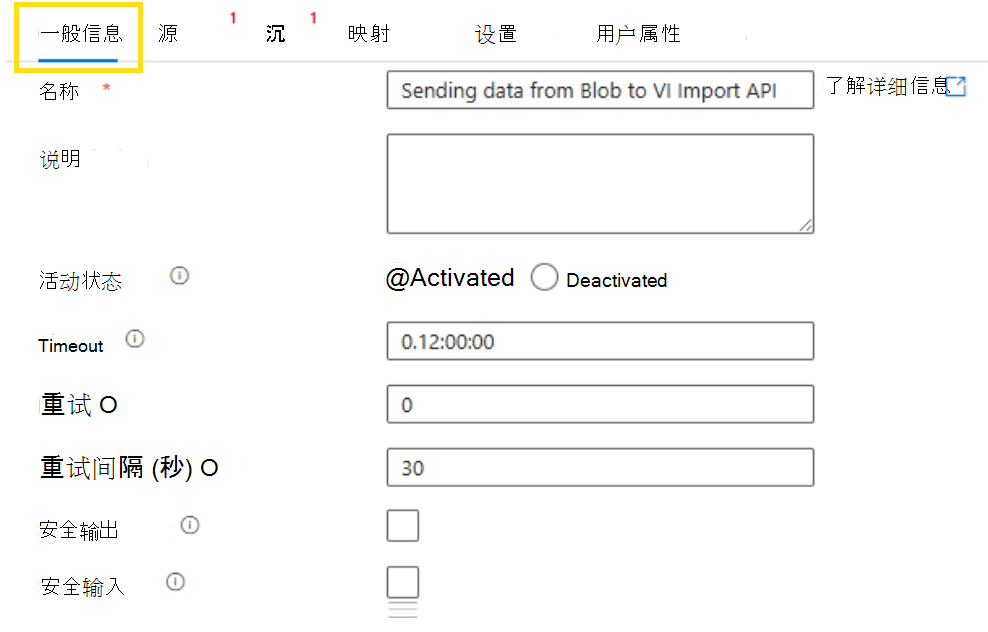
- 名称:输入活动的名称。
- 说明:输入活动的说明。
- 活动状态:选择“ 已激活”。 或者选择“ 已停用 ”,从管道运行和验证中排除活动。
- 超时:这是活动可以运行的最长时间。 默认值为 12 小时,最小值为 10 分钟,允许的最大时间为 7 天。 格式为 D.HH:MM:SS。
- 重试:最大重试次数。 这可以保留为 0。
- 重试间隔 (秒) :最大重试次数。 如果重试尝试设置为 0,则这可以保留为 30。
- 安全输出:选择后,不会在日志记录中捕获活动的输出。 可以清除此项。
- 安全输入:选择后,不会在日志记录中捕获来自活动的输入。 可以清除此项。
4. 复制数据活动设置:源
选择“ 源”。
选择现有源数据集或选择“ +新建” 以创建新的源数据集。 例如,在“新建数据集”下选择“Azure Blob 存储”,然后选择数据的格式类型。

设置 .csv 文件的属性。 输入 “名称” ,然后在“ 链接服务”下,选择现有位置或选择“ +新建”。

如果选择了“ +新建”,请使用以下指南输入新链接服务的详细信息。

在 “源数据集”旁边,选择“ 打开”。

选择“ 第一行”作为标题。

5. 复制数据活动设置:接收器
选择“ 接收器”。
选择“ +新建 ”,将新的 rest 资源配置为连接到 Viva Insights 导入 API。 搜索“Rest”,然后选择“ 继续”。

为服务命名。 在 “链接服务 ”下,选择“ +新建”。

搜索“Rest”并将其选中。

使用以下指南输入字段。
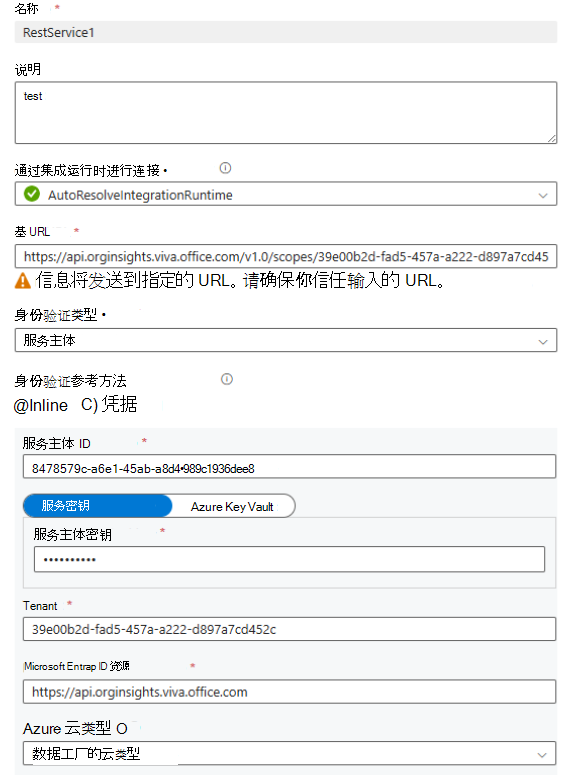
- 名称:输入新链接服务的名称。
- 说明:输入新链接服务的说明。
- 通过集成运行时进行连接:输入首选方法。
- 基 URL:使用以下 URL 并将 TENANT_ID> 替换为<租户 ID:https://api.orginsights.viva.office.com/v1.0/scopes/<TENANT_ID>/ingress/connectors/HR/ingestions/fileIngestion
-
身份验证类型:选择身份验证类型作为 服务主体 或 证书。 服务主体示例:
- 内联:选择它。
- 服务主体 ID:输入 ID。
- 服务主体密钥:输入密钥。
- 租户:输入租户 ID。
- Microsoft Entra ID资源:https://api.orginsights.viva.office.com
- Azure云类型:选择Azure云类型。
- 服务器证书验证:选择 “已启用”。
使用以下指南输入接收器设置。

- 接收器数据集:选择现有数据集或新创建的数据集。
- 请求方法:选择“ POST”。
- 请求超时:默认为 5 分钟。
- 请求间隔 (毫秒) :默认值为 10。
- 写入批大小:批大小应大于文件中的最大行数。
- Http 压缩类型:无 为默认值。 或者,可以使用 GZip。
-
其他标头:选择“ +新建”。
- 框 1:x-nova-scaleunit
- 值:可通过导航到“组织数据”选项卡->“选择”管理数据源“->>”选择基于 API 的导入“,从工作区分析中检索该值。
6. 复制数据活动设置:映射
选择“ 映射”。
对于启动上传,请确保在映射中包括 PersonId、ManagerId 和组织, (目标名称) 。 对于增量上传,请验证目标名称是否与上一个上传中的目标名称以及 PersonId 一致。 不能使用新列执行增量上传,并且所有上传都需要 PersonId 。

7. 复制数据活动设置:设置和用户属性
“设置”或“用户属性”不需要其他自定义项。 如果需要,可以逐个编辑这些设置。
8. 复制数据活动:触发安装程序 (自动化)
若要将触发器添加到自动化设置,请选择“ 添加触发器”。 建议的自动化是每周一次。 还可以自定义频率。

Validation
数据源管理员发送数据后,应用开始验证。
此阶段完成后,验证已成功或失败。 根据结果,你将在 “数据连接 ”屏幕右上角收到成功通知或失败通知。
有关后续作的信息,请转到相应的部分:
验证成功
成功验证后,Viva Insights 开始处理新数据。 处理可能需要几个小时到一天左右的时间。 在处理过程中,“ 导入历史记录 ”表上会显示“正在处理”状态。
处理完成后,它要么成功,要么失败。 根据结果,可以在 “导入历史记录 ”表中找到“成功”或“失败”状态。
处理成功
在 “导入历史记录 ”表中找到“成功”状态时,上传过程已完成。
收到“成功”状态后,可以:
- 选择 (眼睛) 图标的视图以查看验证结果的摘要。
- 选择映射图标以查看工作流的映射设置。
注意
每个租户一次只能进行一次导入。 你需要完成一个数据文件的工作流,这意味着在开始下一个数据文件的工作流之前,要么引导它成功验证和处理,要么放弃它。 上传工作流的状态或阶段显示在“ 数据连接 ”选项卡上。
处理失败
如果处理失败,“导入 历史记录 ”表中会显示“处理失败”状态。 若要成功处理,数据源管理员需要更正错误并再次将数据推送到 Viva Insights。
注意
处理失败通常是由后端错误导致的。 如果看到持续处理失败,并且已更正导入文件中的数据,请 向我们记录支持票证。
验证失败
如果数据验证失败,导入 历史记录 表中将显示“验证失败”状态。 若要成功验证,数据源管理员需要更正错误,并再次将数据推送到 Viva Insights。 在 “作”下,选择下载图标以下载错误日志。 将此日志发送给数据源管理员,以便他们知道在再次发送数据之前要更正的内容。
数据源管理员可能会发现以下部分有助于修复导出文件中的数据错误。
关于数据中的错误
适用于:数据源管理员
当任何数据行或列具有任何属性的无效值时,整个导入将失败,直到数据源管理员修复源数据。
请参阅 准备组织数据 ,了解可能有助于解决遇到的错误的特定格式设置规则。