Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Datenqualität misst die Integrität von Daten in einem organization. Sie bewerten die Datenqualität mithilfe von Datenqualitätsbewertungen. Microsoft Purview Unified Catalog generiert Bewertungen basierend auf der Bewertung der Daten anhand der von Ihnen definierten Regeln.
Datenqualitätsregeln sind wichtige Richtlinien, die Organisationen festlegen, um die Genauigkeit, Konsistenz und Vollständigkeit ihrer Daten sicherzustellen. Diese Regeln tragen zur Aufrechterhaltung der Datenintegrität und -zuverlässigkeit bei.
Im Folgenden finden Sie einige wichtige Aspekte von Data Quality-Regeln:
Genauigkeit: Daten sollten reale Entitäten genau darstellen. Kontext ist wichtig! Wenn Sie beispielsweise Kundenadressen speichern, stellen Sie sicher, dass diese mit den tatsächlichen Standorten übereinstimmen.
Vollständigkeit: Diese Regel identifiziert leere, NULL- oder fehlende Daten. Es wird überprüft, ob alle Werte vorhanden sind, wenn auch nicht unbedingt korrekt.
Konformität: Diese Regel stellt sicher, dass die Daten Standards für die Datenformatierung einhalten, z. B. die Darstellung von Datumsangaben, Adressen und zulässigen Werten.
Konsistenz: Diese Regel überprüft, ob unterschiedliche Werte desselben Datensatzes einer bestimmten Regel entsprechen und dass keine Widersprüche vorliegen. Die Datenkonsistenz stellt sicher, dass die gleichen Informationen in verschiedenen Datensätzen einheitlich dargestellt werden. Wenn Sie über einen Produktkatalog verfügen, sind für instance konsistente Produktnamen und -beschreibungen von entscheidender Bedeutung.
Aktualität: Mit dieser Regel soll sichergestellt werden, dass die Daten in so kurzer Zeit wie möglich zugänglich sind. Dadurch wird sichergestellt, dass die Daten auf dem neuesten Stand sind.
Eindeutigkeit: Diese Regel überprüft, ob Werte nicht dupliziert werden. Wenn beispielsweise nur ein Datensatz pro Kunde vorhanden sein soll, gibt es nicht mehrere Datensätze für denselben Kunden. Jeder Kunde, jedes Produkt oder jede Transaktion sollte über einen eindeutigen Bezeichner verfügen.
Lebenszyklus der Datenqualität
Das Erstellen von Data Quality-Regeln ist der sechste Schritt im Data Quality-Lebenszyklus. Die vorherigen Schritte sind:
- Weisen Sie Benutzern Data Quality Steward-Berechtigungen in Unified Catalog zu, um alle Data Quality-Features zu verwenden.
- Registrieren und überprüfen Sie eine Datenquelle in Microsoft Purview Data Map.
- Fügen Sie Ihre Datenressource einem Datenprodukt hinzu.
- Richten Sie eine Datenquellenverbindung ein, um Ihre Quelle für die Bewertung der Datenqualität vorzubereiten.
- Konfigurieren und Ausführen der Datenprofilerstellung für ein Medienobjekt in Ihrer Datenquelle.
Erforderliche Rollen
- Zum Erstellen und Verwalten von Datenqualitätsregeln benötigen Benutzer die Rolle Data Quality Steward.
- Um vorhandene Qualitätsregeln anzuzeigen, benötigen Benutzer die Rolle "Data Quality Reader".
Anzeigen vorhandener Datenqualitätsregeln
Wählen Sie Unified Catalog die Option Integritätsverwaltung und dann Datenqualität aus.
Wählen Sie eine Governancedomäne und dann ein Datenprodukt aus.
Wählen Sie eine Datenressource aus der Liste Datenressourcen aus.
Wählen Sie die Registerkarte Regeln aus, um die vorhandenen Regeln anzuzeigen, die auf das Medienobjekt angewendet werden.
Wählen Sie eine Regel aus, um den Leistungsverlauf der angewendeten Regel auf die ausgewählte Datenressource zu durchsuchen.


Verfügbare Data Quality-Regeln
Microsoft Purview Data Quality ermöglicht die Konfiguration der folgenden Regeln. Diese Regeln sind sofort verfügbar und bieten eine Möglichkeit, die Qualität Ihrer Daten zu messen.
| Regel | Definition |
|---|---|
| Aktualität | Bestätigt, dass alle Werte auf dem neuesten Stand sind. |
| Eindeutige Werte | Bestätigt, dass die Werte in einer Spalte eindeutig sind. |
| Übereinstimmung des Zeichenfolgenformats | Bestätigt, dass die Werte in einer Spalte einem bestimmten Format oder anderen Kriterien entsprechen. |
| Übereinstimmung des Datentyps | Bestätigt, dass die Werte in einer Spalte ihren Datentypanforderungen entsprechen. |
| Doppelte Zeilen | Sucht nach doppelten Zeilen mit den gleichen Werten in zwei oder mehr Spalten. |
| Leere/leere Felder | Sucht nach leeren und leeren Feldern in einer Spalte, in der Werte vorhanden sein sollen. |
| Tabellensuche | Bestätigt, dass ein Wert in einer Tabelle in der spezifischen Spalte einer anderen Tabelle gefunden werden kann. |
| Custom | Erstellen Sie eine benutzerdefinierte Regel mit dem Visuellen Ausdrucks-Generator. |
Aktualität
Die Aktualitätsregel überprüft, ob das Medienobjekt innerhalb der erwarteten Zeit aktualisiert wird. Die Aktualität wird durch die Auswahl der Datumsangaben der letzten Änderung bestimmt.

Hinweis
Die Bewertung der Aktualitätsregel ist entweder 100 (Bestanden) oder 0 (Fehler). Die Aktualitätsregel wird für Snowflake, Azure Databricks Unity Catalog, Google BigQuery, Synapse und Microsoft Azure SQL nicht unterstützt.
Eindeutige Werte
Die Regel Eindeutige Werte gibt an, dass alle Werte in der angegebenen Spalte eindeutig sein müssen. Alle eindeutigen Werte werden als pass behandelt, und Werte, die nicht eindeutig sind, werden als fehler behandelt. Wenn die Regel Leere/leere Felder nicht für die Spalte definiert ist, werden null- oder leere Werte für die Zwecke dieser Regel ignoriert.

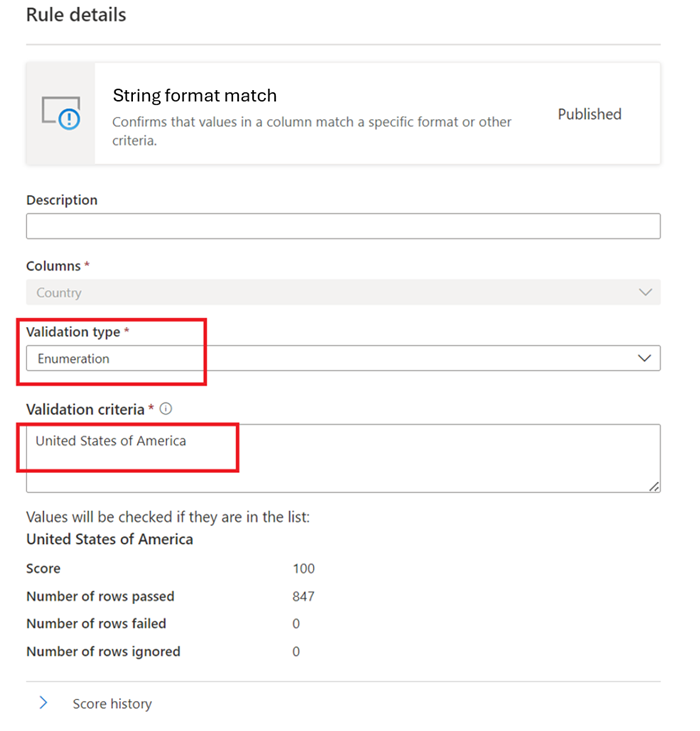
Übereinstimmung des Zeichenfolgenformats
Die Übereinstimmungsregel Format überprüft, ob alle Werte in der Spalte gültig sind. Wenn Sie die Regel Leere/leere Felder für eine Spalte nicht definieren, ignoriert die Regel NULL- oder leere Werte.
Diese Regel kann jeden Wert in der Spalte mit drei verschiedenen Ansätzen überprüfen:
-
Enumeration: Bei diesem Ansatz wird eine durch Trennzeichen getrennte Liste von Werten verwendet. Wenn der ausgewertete Wert nicht mit einem der aufgeführten Werte übereinstimmt, tritt bei der Überprüfung ein Fehler auf. Sie können Kommas und umgekehrte Schrägstriche mit escapen, indem Sie einen umgekehrten Schrägstrich (
\) verwenden.a \, b, cEnthält also zwei Werte: der erste ista , bund der zweite istc.
Wie Muster:
like(<i><string></i> : string, <i><pattern match></i> : string) => booleanDas Muster ist eine Zeichenfolge, mit der die Regel wörtlich übereinstimmt. Ausnahmen sind die folgenden Sondersymbole: _ entspricht einem beliebigen Zeichen in der Eingabe (ähnlich wie.inposixregulären Ausdrücken) % entspricht null oder mehr Zeichen in der Eingabe (ähnlich wie.inposixregulären Ausdrücken). Das Escapezeichen lautet.Wenn ein Escapezeichen vor einem Sondersymbol oder einem anderen Escapezeichen steht, wird das folgende Zeichen wörtlich abgeglichen. Es ist ungültig, ein anderes Zeichen mit Escapezeichen zu versehen.like('icecream', 'ice%') -> true

Regulärer Ausdruck:
regexMatch(<i><string></i> : string, <i><regex to match></i> : string) => booleanÜberprüft, ob die Zeichenfolge mit dem angegebenen RegEx-Muster übereinstimmt. Verwenden Sie
<regex>(Zurück-Anführungszeichen), um eine Zeichenfolge ohne Escapezeichen abzugleichen.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true

Übereinstimmung des Datentyps
Die Datentyp-Übereinstimmungsregel gibt den erwarteten Datentyp für die zugeordnete Spalte an. Da die Regel-Engine in vielen verschiedenen Datenquellen ausgeführt wird, kann sie keine nativen Typen wie BIGINT oder VARCHAR verwenden. Stattdessen verwendet es ein eigenes Typsystem und übersetzt native Typen in dieses System. Diese Regel teilt der Qualitätsscan-Engine mit, welche der integrierten Typen für den nativen Typ verwendet werden soll. Das Datentypsystem stammt aus dem microsoft Azure Datenfluss Typsystem, das in Azure Data Factory verwendet wird.
Während einer Qualitätsüberprüfung testet die Engine alle nativen Typen anhand des Datentyp-Übereinstimmungstyps. Wenn der native Typ nicht in den Datentypübereinstimmungstyp übersetzt werden kann, wird diese Zeile als Fehler behandelt.

Doppelte Zeilen
Die Regel Doppelte Zeilen überprüft, ob die Kombination der Werte in der Spalte für jede Zeile in der Tabelle eindeutig ist.
Im folgenden Beispiel wird erwartet, dass die Verkettung von CompanyName, CustomerID, EmailAddress, FirstName und LastName einen Wert erzeugt, der für alle Zeilen in der Tabelle eindeutig ist.
Jede Ressource kann null oder eine instance dieser Regel aufweisen.

Leere/leere Felder
Die Regel Leere/leere Felder bestätigt, dass die identifizierten Spalten keine NULL-Werte enthalten dürfen. Für Zeichenfolgen lässt die Regel auch leere Werte oder Nur-Leerzeichenwerte zu. Während einer Datenqualitätsüberprüfung behandelt die Engine jeden Wert in dieser Spalte, der nicht NULL ist, als richtig. Diese Regel wirkt sich auf andere Regeln aus, z. B . eindeutige Werte oder Format-Übereinstimmungsregeln . Wenn Sie diese Regel nicht für eine Spalte definieren, ignorieren diese Regeln automatisch alle NULL-Werte, wenn sie für diese Spalte ausgeführt werden. Wenn Sie diese Regel für eine Spalte definieren, untersuchen diese Regeln NULL- oder leere Werte für diese Spalte und berücksichtigen sie zu Bewertungszwecken.

Tabellensuche
Die Tabellen-Nachschlageregel untersucht jeden Wert in der Spalte, in der Sie die Regel definieren, und vergleicht ihn mit einer Verweistabelle. Beispielsweise enthält eine primäre Tabelle eine Spalte namens "location", die Städte, Bundesstaaten und Postleitzahlen im Format "city, state zip" enthält. Eine Referenztabelle namens "citystate" enthält alle rechtlichen Kombinationen von Städten, Bundesstaaten und Postleitzahlen, die im USA unterstützt werden. Das Ziel besteht darin, alle Speicherorte in der aktuellen Spalte mit dieser Verweisliste zu vergleichen, um sicherzustellen, dass nur rechtliche Kombinationen verwendet werden.
Um diese Regel einzurichten, geben Sie den Namen "citystatezip" in das Dialogfeld "Ressourcen suchen" ein. Wählen Sie dann die gewünschte Ressource und die Spalte aus, mit der Sie vergleichen möchten.

Hinweis
Die Referenztabelle oder das Datenasset muss zur gleichen Governancedomäne gehören. Sie können eine Datenressource nicht über verschiedene Governancedomänen hinweg vergleichen.
Benutzerdefinierte Regeln
Mit der benutzerdefinierten Regel können Sie Regeln angeben, die Zeilen basierend auf einem oder mehreren Werten in dieser Zeile überprüfen. Sie können reguläre Ausdrücke, Azure Data Factory Ausdruck und SQL-Ausdruckssprache verwenden, um benutzerdefinierte Regeln zu erstellen.
Eine benutzerdefinierte Regel umfasst drei Teile:
Zeilenausdruck: Dieser boolesche Ausdruck gilt für jede Zeile, die vom Filterausdruck genehmigt wird. Wenn dieser Ausdruck true zurückgibt, wird die Zeile übergeben. Wenn false zurückgegeben wird, schlägt die Zeile fehl.
Filterausdruck: Diese optionale Bedingung schränkt das Dataset ein, für das die Zeilenbedingung ausgewertet wird. Sie aktivieren es, indem Sie das Kontrollkästchen Filterausdruck verwenden aktivieren. Dieser Ausdruck gibt einen booleschen Wert zurück. Der Filterausdruck gilt für eine Zeile, und wenn er true zurückgibt, wird diese Zeile für die Regel berücksichtigt. Wenn der Filterausdruck false für diese Zeile zurückgibt, bedeutet dies, dass zeile für die Zwecke dieser Regel ignoriert wird. Das Standardverhalten des Filterausdrucks besteht darin, alle Zeilen zu übergeben. Wenn Sie also keinen Filterausdruck angeben, werden alle Zeilen berücksichtigt.
NULL-Ausdruck: Überprüft, wie NULL-Werte behandelt werden sollen. Dieser Ausdruck gibt einen Booleschen Wert zurück, der Fälle behandelt, in denen Daten fehlen. Wenn der Ausdruck true zurückgibt, wird der Zeilenausdruck nicht angewendet.
Jeder Teil der Regel funktioniert ähnlich wie vorhandene Microsoft Purview Data Quality Bedingungen. Eine Regel wird nur übergeben, wenn der Zeilenausdruck für das Dataset, das dem Filterausdruck entspricht, als TRUE ausgewertet wird und fehlende Werte wie im NULL-Ausdruck angegeben behandelt.
Beispiel: Eine Regel, um sicherzustellen, dass "fareAmount" positiv und "tripDistance" gültig ist:
- Zeilenausdruck: tripDistance > 0 AND fareAmount > 0
- Filterausdruck: paymentType = 'CRD'
- NULL-Ausdruck: tripDistance IS NULL
Erstellen einer benutzerdefinierten Regel
- Wechseln Sie Unified Catalog zu Integritätsverwaltung>Datenqualität.
- Wählen Sie eine Governancedomäne, ein Datenprodukt und dann eine Datenressource aus.
- Wählen Sie auf der Registerkarte Regeln die Option Neue Regel aus.
Erstellen einer benutzerdefinierten Regel mit Azure Data Factory Ausdruck (ADF)
Um die Regel mithilfe eines regulären Ausdrucks oder eines ADF-Ausdrucks zu erstellen, wählen Sie in der Regelliste der Optionen die Option Benutzerdefiniert und dann Weiter aus.
Fügen Sie Regelnamen und Beschreibung hinzu, und wählen Sie dann Erstellen aus.

Beispiele für benutzerdefinierte Regeln
| Szenario | Ausdrücke |
|---|---|
| Überprüfen Sie, ob state_id gleich Kalifornien ist und aba_Routing_Number einem bestimmten RegEx-Muster entspricht und das Geburtsdatum in einen bestimmten Bereich fällt. | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Überprüfen, ob VendorID gleich 124 ist | {VendorID}=='124' |
| Überprüfen Sie , ob fare_amount gleich oder größer als 100 ist. | {fare_amount} >= "100" |
| Überprüfen, ob fare_amount größer als 100 und tolls_amount ungleich 100 ist | {fare_amount} >= "100"||{tolls_amount} != "400" |
| Überprüfen Sie, ob die Bewertung kleiner als 5 ist. | Rating < 5 |
| Überprüfen, ob die Anzahl der Ziffern im Jahr 4 ist | length(toString(year)) == 4 |
| Vergleichen Sie die beiden Spalten bbToLoanRatio und bankBalance , um zu überprüfen, ob ihre Werte gleich sind. | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Überprüfen Sie, ob die gekürzte und verkettete Anzahl von Zeichen in firstName, lastName, LoanID, uuid größer als 20 ist. | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Überprüfen Sie, ob aba_Routing_Number mit einem bestimmten RegEx-Muster übereinstimmt und das Datum der ersten Transaktion größer als 2022-11-12 und Disallow-Listed false ist und der durchschnittliche bankBalance-Wert größer als 50000 ist und state_id gleich "Massachusetts", "Tennessee", "North Dakota" oder "Alabama" ist. | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachusetts' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Alabama') |
| Überprüfen Sie, ob aba_Routing_Number einem bestimmten RegEx-Muster entspricht und dateOfBirth zwischen 13.12.12.1968 und 2020-12-13 liegt. | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Überprüfen Sie, ob die Anzahl eindeutiger Werte in aba_Routing_Number gleich 1.000.000 und die Anzahl eindeutiger Werte in EMAIL_ADDR gleich 1.000.000 ist. | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
Sowohl der Filterausdruck als auch der Zeilenausdruck werden mithilfe der Azure Data Factory Ausdruckssprache definiert, wobei die hier definierte Sprache verwendet wird. Es sind jedoch nicht alle Für die generische ADF-Ausdruckssprache definierten Funktionen verfügbar. Die vollständige Liste der verfügbaren Funktionen finden Sie in der Liste Funktionen, die im Dialogfeld "Ausdruck" verfügbar ist. Die folgenden hier definierten Funktionen werden nicht unterstützt: isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, cached lookup und Window.
Hinweis
<regex> (zurückes Anführungszeichen) kann in regulären Ausdrücken verwendet werden, die in benutzerdefinierten Regeln enthalten sind, um eine Zeichenfolge ohne Escapezeichen für Sonderzeichen abzugleichen. Die Sprache für reguläre Ausdrücke basiert auf Java. Erfahren Sie mehr über reguläre Ausdrücke und Java , und verstehen Sie die Zeichen, die mit Escapezeichen versehen werden müssen.
Erstellen einer benutzerdefinierten Regel mithilfe eines SQL-Ausdrucks
Benutzerdefinierte SQL-Regeln in Microsoft Purview Data Quality bieten eine flexible Möglichkeit zum Definieren von Datenqualitätsprüfungen mithilfe von Spark SQL-Prädikaten. Mit diesem Feature können Benutzer Regeln direkt in Spark SQL für erweiterte Validierungsszenarien erstellen. Es ist nur ein Zeilenausdruck erforderlich. Filter- und NULL-Ausdrücke sind für weitere Anpassungen optional. Verwenden Sie benutzerdefinierte SQL-Regeln, um komplexe Geschäftsanforderungen zu erfüllen und die Datenqualität zu verbessern, indem Sie die vollständigen Funktionen von Spark SQL nutzen. Benutzerdefinierte SQL-Regeln ermöglichen eine komplexe Datenüberprüfung, die mit ADF-Ausdrücken allein möglicherweise nicht möglich ist. Durch das Schreiben von Spark SQL-Prädikaten können Sie einzigartige Geschäftsanforderungen erfüllen und hohe Datenqualitätsstandards einhalten.
Um die Regel mithilfe der SQL-Ausdruckssprache zu erstellen, wählen Sie in der Regelliste der Optionen die Option Benutzerdefiniert (SQL) und dann Weiter aus.
Fügen Sie Regelnamen und Beschreibung hinzu, und wählen Sie dann Erstellen aus.
Szenario Ausdrücke Überprüft korrekte Zeichenfolgenmuster (z. B. rateCodeId ab "1" und numerisch) und filtert nach gültigen Zahlungstypen. Row: rateCodeId RLIKE '^1[0-9]+$'Filter: paymentType IN ('CRD', 'CSH')Null: rateCodeId IS NULLStellt einen korrekten Spaltenvergleich zwischen puLocationId und doLocationId und dem Fahrpreis im Vergleich zur Fahrtstrecke sicher. Row: puLocationId > doLocationId AND fareAmount > tripDistance * 10'Filter: paymentType <> 'CSH''Null: tripDistance IS NULLÜberprüft, ob der paymentType in einer bestimmten Liste (Card, Cash) enthalten ist, und filtert Zeilen nach Tarifbeträgen. Row: paymentType IN ('CRD', 'CSH')'Filter: fareAmount >= 50Null: paymentType IS NULLStellt sicher, dass die Entfernung innerhalb eines inklusiven Bereichs (5-10 Meilen) liegt, während NULL verarbeitet und nach gültigen Zahlungsmethoden gefiltert wird. Row: tripDistance BETWEEN 5 AND 10Filter: paymentType <> 'CRD'Null: tripDistance IS NULLStellt sicher, dass das Dataset einen NULL-Wert von 20 % für fareAmount nicht überschreitet. Row: (SELECT avg(CASE WHEN fareAmount IS NULL THEN 1 ELSE 0 END) FROM nycyellowtaxidelta1BillionPartitioned) < 0.20'Filter: vendorID IN ('VTS', 'CMT')Überprüft, ob das Dataset mindestens zwei unterschiedliche paymentType-Werte enthält. Row: (SELECT count(DISTINCT paymentType) FROM nycyellowtaxidelta1BillionPartitioned) >= 2Filter: vendorID IN ('1', '2')Stellt sicher, dass der durchschnittliche Fahrpreis des Datasets innerhalb eines angegebenen Bereichs liegt (80 <= durchschnittlich <= 140). Row: (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) BETWEEN 80 AND 140 'Filter: paymentType IN ('CRD', 'CSH')Stellt sicher, dass die maximale tripDistance im Dataset = 10 Meilen beträgt <. Row: (SELECT max(tripDistance) FROM nycyellowtaxidelta1BillionPartitioned) <= 10.0Filter: vendorID IN ('VTS', 'CMT')Stellt sicher, dass die Standardabweichung von fareAmount unter einem bestimmten Schwellenwert (< 30) liegt. Row: (SELECT stddev_samp(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) < 30.0Filter: vendorID IN ('VTS', 'CMT')Stellt sicher, dass der Medianpreis des Datasets innerhalb des angegebenen Schwellenwerts (<= 15) liegt. Row: (SELECT percentile_approx(fareAmount, 0.5) FROM nycyellowtaxidelta1BillionPartitioned) <= 15.0Filter: vendorID IN ('VTS', 'CMT')Stellt sicher, dass vendorId im Dataset innerhalb eines bestimmten paymentType eindeutig ist. Row: COUNT(1) OVER (PARTITION BY vendorID) = 1Filter: paymentType IN ('CRD', 'CSH','1', '2')Null: vendorID IS NULLStellt sicher, dass die Kombination aus puLocationId und doLocationId innerhalb des Datasets eindeutig ist. Row: COUNT(1) OVER (PARTITION BY puLocationId, doLocationId) = 1Filter: paymentType IN ('CRD', 'CSH')Null: puLocationId IS NULL OR doLocationId IS NULLStellt sicher, dass vendorId pro paymentType eindeutig ist. Row: COUNT(1) OVER (PARTITION BY paymentType, vendorID) = 1 ,Filter: rateCodeId < 25, Null: vendorID IS NULLStellt sicher, dass der tpepPickupDateTime-Wert der Zeile größer als ein gegebener Cutoff-Zeitstempel ist. Row: tpepPickupDateTime >= TIMESTAMP '2014-01-03 00:00:00'Filter: paymentType IN ('CRD', 'CSG', '1', '2')Null: tpepPickupDateTime IS NULLJede Fahrt muss innerhalb von 1 Stunde abgeschlossen werden Row: (unix_timestamp(tpepDropoffDateTime) - unix_timestamp(tpepPickupDateTime)) <= 3600Filter: paymentType IN ('CRD', 'CSH', '1', '2')Null: tpepPickupDateTime IS NULL OR tpepDropoffDateTime IS NULLBehält nur den höchsten Fahrpreis pro Abholort bei. Row: row_number() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1, Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0, Null: fareAmount IS NULL OR puLocationId IS NULLAlle gebundenen höchsten Tarife pro Abholort (nicht nur zuerst durch row_number). Row: rank() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0Null: fareAmount IS NULL OR puLocationId IS NULLDer Fahrpreis darf sich nicht im Laufe der Zeit für jede Zahlungsmethode verringern. Row: fareAmount >= lag(fareAmount) OVER (PARTITION BY paymentType ORDER BY tpepPickupDateTime)Null: tpepPickupDateTime IS NULL OR fareAmount IS NULLDer Tarif jeder Zeile liegt innerhalb von 10 des Gruppendurchschnitts nach Zahlungsmethode. Row: abs(fareAmount - avg(fareAmount) OVER (PARTITION BY paymentType)) <= 10Filter: paymentType IN ('CRD', 'CSH','1','2')Null: fareAmount IS NULLDie Gesamtanzahl der Fahrtstrecken darf 20 Meilen nicht überschreiten. Row: sum(tripDistance) OVER (ORDER BY tpepPickupDateTime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) <= 20Filter: paymentType = '1'Null: tripDistance IS NULLÜberprüft, ob der Fahrpreis jeder Reise über dem globalen Durchschnitt für berechtigte Anbieter liegt. Row: fareAmount > (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned)Filter: vendorID IN ('VTS', 'CMT')Null: fareAmount IS NULLÜberprüft, ob die tripDistance jeder Zeile größer als der Mindestwert für ihren paymentType (Card/Cash) ist. Row: tripDistance > (SELECT min(u.tripDistance) FROM (SELECT tripDistance, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD', 'CSH')Null: tripDistance IS NULLÜberprüft bei jeder Fahrt, ob der Fahrpreis über dem Durchschnitt für seine Zahlungsmethode liegt. Row: fareAmount > (SELECT avg(u.fareAmount) FROM (SELECT fareAmount, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD','CSH','1','2') AND vendorID IN ('VTS','CMT')Null: fareAmount IS NULLÜberprüft, ob die fareAmount-Spalte (numerisch) korrekt als Zeichenfolge dargestellt werden kann, die dem numerischen Muster entspricht (positive Zahlen mit optionaler Dezimalzahl). Dabei wird die Umwandlung verwendet, da fareAmount eine numerische Spalte ist. Row: CAST(fareAmount AS STRING) RLIKE '^[0-9]+(\.[0-9]+)?$'Filter: paymentType IN ('CRD', 'CSH')Null: fareAmount IS NULLStellt sicher, dass tpepPickupDateTime ein gültiger Zeitstempel im Format yyyy-MM-tt HH:mm:ss ist. Diese Spalte weist bereits das DATETIME-Format auf. Row: to_timestamp(tpepPickupDateTime, 'yyyy-MM-dd HH:mm:ss') IS NOT NULLFilter: paymentType IN ('CRD','CSH')Null: tpepPickupDateTime IS NULLStellt sicher, dass paymentType-Werte in Kleinbuchstaben normalisiert werden und keine führenden oder nachfolgenden Leerzeichen aufweisen. Row: lower(trim(paymentType)) IN ('card','cash') AND length(trim(paymentType)) > 0Null: paymentType IS NULL OR trim(paymentType) = ''Berechnet sicher das Verhältnis von fareAmount zu tripDistance und stellt sicher, dass die Division durch Null nicht erfolgt, indem zuerst überprüft wird, ob tripDistance > 0 ist. Row: CASE WHEN tripDistance > 0 THEN fareAmount / tripDistance ELSE NULL END >= 10Filter: tripDistance > 0 AND vendorID IN ('VTS', 'CMT')Veranschaulicht, wie Coalesce NULL-Werte durch Standardwerte ersetzen kann (z. B. 0,0), und stellt sicher, dass nur gültige Zeilen zurückgegeben werden. Row: coalesce(fareAmount, 0.0) >= 5Filter: paymentType IN ('CRD','CSH')
Bewährte Methoden zum Schreiben benutzerdefinierter SQL-Regeln
- Halten Sie Ausdrücke einfach. Ziel ist es, klare, unkomplizierte Ausdrücke zu schreiben, die einfach zu verwalten sind.
- Verwenden sie integrierte Spark SQL-Funktionen. Verwenden Sie die umfangreiche Bibliothek von Funktionen von Spark SQL für die Bearbeitung von Zeichenfolgen, die Datumsbehandlung und numerische Vorgänge, um Fehler zu minimieren und die Leistung zu verbessern.
- Testen Sie zuerst mit einem kleinen Dataset. Überprüfen Sie Regeln für ein kleines Dataset, bevor Sie sie im großen Stil anwenden, um potenzielle Probleme frühzeitig zu identifizieren.
Bekannte Einschränkungen und Überlegungen für SQL-Ausdrucksregeln
Mehrdeutige Spaltenverweise und Spaltenschattierung
Problem: Wenn eine Spalte sowohl in der äußeren Abfrage als auch in der Unterabfrage (oder in verschiedenen Teilen der Abfrage) mit demselben Namen angezeigt wird, kann Spark SQL möglicherweise nicht auflösen, welche Spalte verwendet werden soll. Dieses Problem führt zu logischen Fehlern oder zu einer falschen Abfrageausführung. Dieses Problem kann bei geschachtelten Abfragen, Unterabfragen oder Joins auftreten, was zu Mehrdeutigkeiten oder Schatten führt.
Mehrdeutigkeit: Tritt auf, wenn ein Spaltenname sowohl in der äußeren Abfrage als auch in der Unterabfrage ohne eindeutige Qualifizierung vorhanden ist, sodass Spark SQL unsicher ist, auf welche Spalte verwiesen werden soll.
Shadowing: Bezieht sich auf, wenn eine Spalte in der äußeren Abfrage von derselben Spalte in der Unterabfrage "überschrieben" oder "abgeschatt" wird, wodurch der äußere Verweis ignoriert wird.
Beispielausdruck:
distance_km > ( SELECT min(distance_km) FROM Tripdata t WHERE t.payment_type = payment_type -- ambiguous outer reference )Problem: Nicht qualifizierte payment_type wird in den nächstgelegenen Bereich aufgelöst, der eine Spalte mit diesem Namen enthält, d. h. die innere t.payment_type , nicht die payment_type der äußeren Zeile. Dadurch wird das Prädikat in t.payment_type = t.payment_type (immer TRUE) umgewandelt, sodass Ihre Unterabfrage zu einem globalen min statt zu einer Gruppe min wird.
Lösung: Um diese Mehrdeutigkeit aufzulösen und Spaltenschattierung zu vermeiden, benennen Sie die innere Spalte in der Unterabfrage um, und stellen Sie sicher, dass die payment_type der äußeren Abfrage eindeutig bleibt.
Korrigierter Ausdruck:
distance_km >
(
SELECT min(u.distance_km)
FROM (
SELECT distance_km, payment_type AS pt
FROM Tripdata
) u
WHERE u.pt = payment_type -- this `payment_type` now binds to OUTER row
)
- In der Unterabfrage wird die Spalte payment_type als pt (d. h. payment_type AS pt) bezeichnet, und you.pt wird in der Bedingung verwendet.
- In der äußeren Abfrage kann jetzt eindeutig auf den ursprünglichen payment_type verwiesen werden, und Spark SQL löst ihn ordnungsgemäß als äußere payment_type auf.
Fenstervorgänge (Leistungsüberlegung)
- Fenstervorgänge wie ROW_NUMBER() und RANK() können teuer sein, insbesondere bei großen Datasets. Verwenden Sie sie mit Bedacht, und testen Sie die Leistung für kleinere Datasets, bevor Sie sie im großen Stil anwenden. Erwägen Sie die Verwendung von PARTITION BY, um den Datenbereich zu reduzieren.
Escaping von Spaltennamen in Spark SQL
- Wenn Spaltennamen Sonderzeichen (z. B. Leerzeichen, Bindestriche oder andere nicht alphanumerische Zeichen) enthalten, müssen sie mit Escapezeichen versehen werden.
- Beispiel, wenn der Spaltenname order-id lautet und die Regel lauten muss, dass er größer als 10 sein sollte.
- Falscher Ausdruck: order-id > 10
- Richtiger Ausdruck:
`order-id`> 10
Name der Datenressource, der in Ausdrücken verweist
Wenn Sie in SQL-Ausdrücken auf Ihre Datenressource verweisen, müssen Sie bestimmte Bereinigungsregeln befolgen. Der ursprüngliche Name der Datenressource muss nicht aktualisiert werden, aber der Name der Datenressource, auf den in SQL-Ausdrücken verwiesen wird, muss bereinigt werden, um die folgenden Kriterien zu erfüllen:
| Regel | Beschreibung | Beispiel: Ursprünglicher Name | Beispiel: Bereinigungsname |
|---|---|---|---|
| Zulässige Zeichen | Nur Buchstaben (A-Z, a-z), Zahlen (0-9) und Unterstriche (_) sind zulässig. Sonderzeichen (Leerzeichen, Bindestriche, Punkte usw.) müssen entfernt werden. | my-dataset_v1+2023 | mydataset_v12023 |
| Unterstriche kürzen | Unterstriche am Anfang oder Ende des Namens müssen entfernt werden. | my_dataset_ | my_dataset |
| Zeichenlimit | Der endgültige, bereinigte Name darf 64 Zeichen nicht überschreiten. | [Ein langer Name, der 64 Zeichen überschreitet] | [Die ersten 64 Zeichen des bereinigten Namens] |
Wenn ihr Datenobjektname bereits diesen Richtlinien entspricht (d. h., er enthält keine Sonderzeichen, führende/nachfolgende Unterstriche und liegt innerhalb des 64-Zeichen-Grenzwerts), kann er unverändert in Ihren SQL-Ausdrücken verwendet werden.
Bereinigen eines Datasetnamens
Führen Sie die folgenden Schritte aus, um sicherzustellen, dass ihr Datasetname für SQL-Ausdrücke gültig ist:
- Sonderzeichen entfernen: Entfernen Sie alle Zeichen außer Buchstaben, Zahlen und Unterstrichen.
- Unterstriche kürzen: Entfernen Sie alle führenden oder nachfolgenden Unterstriche.
- Abschneiden: Wenn der resultierende Name 64 Zeichen überschreitet, kürzen Sie ihn so ab, dass der Grenzwert von 64 Zeichen eingehalten wird.
Beispiel: Name der Datenressource f07d724d-82c9-4c75-97c4-c5baf2cd12a4.parquet
- Sonderzeichen entfernen: f07d724d82c94c7597c4c5baf2cd12a4parquet
- Unterstriche kürzen: (In diesem Fall nicht verfügbar, da keine führenden oder nachfolgenden Unterstriche vorhanden sind.)
- Abschneiden: Der resultierende Name ist 54 Zeichen lang, was unter dem Grenzwert von 64 Zeichen liegt.
Endgültiger SQL-Referenzname: f07d724d82c94c7597c4c5baf2cd12a4parquet
Hinweis
Der name der ursprünglichen Datenressource bleibt unverändert. Nur der Name der Datenressource, der in den SQL-Ausdrücken verwendet wird, muss diesen Regeln entsprechen. Für Spaltennamen, die Sonderzeichen enthalten, z. B. Leerzeichen oder Bindestriche, können Sie sie in SQL-Ausdrücken mit Escapezeichen versehen.
Joins werden nicht unterstützt.
Benutzerdefinierte SQL-Regeln in Microsoft Purview Data Quality keine Joins unterstützen. Die Regeln müssen für ein einzelnes Dataset verwendet werden. Sie können beim Schreiben dieser benutzerdefinierten Regeln nicht mehrere Tabellen oder Datasets verknüpfen.
Nicht unterstützte SQL-Vorgänge (DML, DCL und schädliches SQL)
Benutzerdefinierte SQL-Regeln unterstützen keine DML-Vorgänge (Data Manipulation Language) oder DCL-Vorgänge (Data Control Language) wie INSERT, UPDATE, DELETE, GRANT und andere schädliche SQL-Vorgänge wie TRUNCATE, DROP und ALTER. Diese Vorgänge werden nicht unterstützt, da sie die Daten oder den Zustand der Datenbank ändern.
KI-gestützte automatisch generierte Regeln
Ki-gestützte automatisierte Regelgenerierung für die Datenqualitätsmessung verwendet KI-Techniken (Künstliche Intelligenz), um automatisch Regeln für die Bewertung und Verbesserung der Datenqualität zu erstellen. Automatisch generierte Regeln sind inhaltsspezifisch. Die meisten allgemeinen Regeln werden automatisch generiert, sodass Sie sich nicht viel mühen müssen, benutzerdefinierte Regeln zu erstellen.
So durchsuchen und wenden Sie automatisch generierte Regeln an:
Wählen Sie auf der Registerkarte Regeln einer Datenressource Regeln vorschlagen aus.
Durchsuchen Sie die Liste der vorgeschlagenen Regeln.

Wählen Sie regeln aus der Liste der vorgeschlagenen Regeln aus, die auf die Datenressource angewendet werden sollen.



Nächste Schritte
- Konfigurieren und Ausführen einer Datenqualitätsüberprüfung für ein Datenprodukt, um die Qualität aller unterstützten Ressourcen im Datenprodukt zu bewerten.
- Überprüfen Sie Ihre Scanergebnisse , um die aktuelle Datenqualität Ihres Datenprodukts zu bewerten.