Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La qualité des données mesure l’intégrité des données dans un organization. Vous évaluez la qualité des données à l’aide de scores de qualité des données. Catalogue unifié Microsoft Purview génère des scores basés sur l’évaluation des données par rapport aux règles que vous définissez.
Les règles de qualité des données sont des directives essentielles que les organisations établissent pour garantir l’exactitude, la cohérence et l’exhaustivité de leurs données. Ces règles permettent de maintenir l’intégrité et la fiabilité des données.
Voici quelques aspects clés des règles de qualité des données :
Précision : les données doivent représenter avec précision des entités réelles. Le contexte est important ! Par exemple, si vous stockez les adresses des clients, assurez-vous qu’elles correspondent aux emplacements réels.
Exhaustivité : cette règle identifie les données vides, null ou manquantes. Il vérifie que toutes les valeurs sont présentes, mais pas nécessairement correctes.
Conformité : cette règle garantit que les données respectent les normes de mise en forme des données telles que la représentation des dates, des adresses et des valeurs autorisées.
Cohérence : cette règle vérifie que les différentes valeurs du même enregistrement sont conformes à une règle donnée et qu’il n’y a pas de contradictions. La cohérence des données garantit que les mêmes informations sont représentées uniformément dans différents enregistrements. Par instance, si vous disposez d’un catalogue de produits, des noms et des descriptions de produits cohérents sont essentiels.
Chronologie : cette règle vise à garantir que les données sont accessibles en un laps de temps aussi court que possible. Il garantit que les données sont à jour.
Unicité : cette règle vérifie que les valeurs ne sont pas dupliquées. Par exemple, s’il n’y a qu’un seul enregistrement par client, il n’y a pas plusieurs enregistrements pour le même client. Chaque client, produit ou transaction doit avoir un identificateur unique.
Cycle de vie de la qualité des données
La création de règles de qualité des données est la sixième étape du cycle de vie de la qualité des données. Les étapes précédentes sont les suivantes :
- Attribuer aux utilisateurs des autorisations de gestionnaire de la qualité des données dans Catalogue unifié pour utiliser toutes les fonctionnalités de qualité des données.
- Inscrire et analyser une source de données dans Mappage de données Microsoft Purview.
- Ajoutez votre ressource de données à un produit de données.
- Configurez une connexion à la source de données pour préparer votre source pour l’évaluation de la qualité des données.
- Configurez et exécutez le profilage des données pour une ressource dans votre source de données.
Rôles requis
- Pour créer et gérer des règles de qualité des données, les utilisateurs ont besoin du rôle de gestionnaire de la qualité des données.
- Pour afficher les règles de qualité existantes, les utilisateurs ont besoin du rôle lecteur de qualité des données.
Afficher les règles de qualité des données existantes
Dans Catalogue unifié, sélectionnez Gestion de l’intégrité, puis Qualité des données.
Sélectionnez un domaine de gouvernance, puis un produit de données.
Sélectionnez une ressource de données dans la liste Ressources de données .
Sélectionnez l’onglet Règles pour afficher les règles existantes appliquées à la ressource.
Sélectionnez une règle pour parcourir l’historique des performances de la règle appliquée à la ressource de données sélectionnée.


Règles de qualité des données disponibles
Qualité des données Microsoft Purview permet de configurer les règles suivantes. Ces règles sont disponibles prêtes à l’emploi et offrent un moyen de mesurer la qualité de vos données à faible code ou sans code.
| Règle | Définition |
|---|---|
| Actualisation | Confirme que toutes les valeurs sont à jour. |
| Valeurs uniques | Confirme que les valeurs d’une colonne sont uniques. |
| Correspondance de format de chaîne | Confirme que les valeurs d’une colonne correspondent à un format spécifique ou à d’autres critères. |
| Correspondance du type de données | Confirme que les valeurs d’une colonne correspondent à leurs exigences en matière de type de données. |
| Lignes dupliquées | Recherche les lignes en double avec les mêmes valeurs sur deux colonnes ou plus. |
| Champs vides/vides | Recherche les champs vides et vides dans une colonne où il doit y avoir des valeurs. |
| Recherche de table | Confirme qu’une valeur dans une table se trouve dans la colonne spécifique d’une autre table. |
| Personnalisé | Créez une règle personnalisée avec le générateur d’expressions visuelles. |
Actualisation
La règle d’actualisation vérifie si la ressource est mise à jour dans le délai prévu. L’actualisation est déterminée par la sélection des dates de dernière modification.

Remarque
Le score de la règle d’actualisation est 100 (réussite) ou 0 (échec). La règle d’actualisation n’est pas prise en charge pour Snowflake, Azure Databricks Unity Catalog, Google BigQuery, Synapse et Microsoft Azure SQL.
Valeurs uniques
La règle Valeurs uniques indique que toutes les valeurs de la colonne spécifiée doivent être uniques. Toutes les valeurs uniques sont traitées comme des réussites, et les valeurs qui ne sont pas uniques sont traitées comme des échecs. Si la règle champs vides/vides n’est pas définie sur la colonne, les valeurs null ou vides sont ignorées pour les besoins de cette règle.

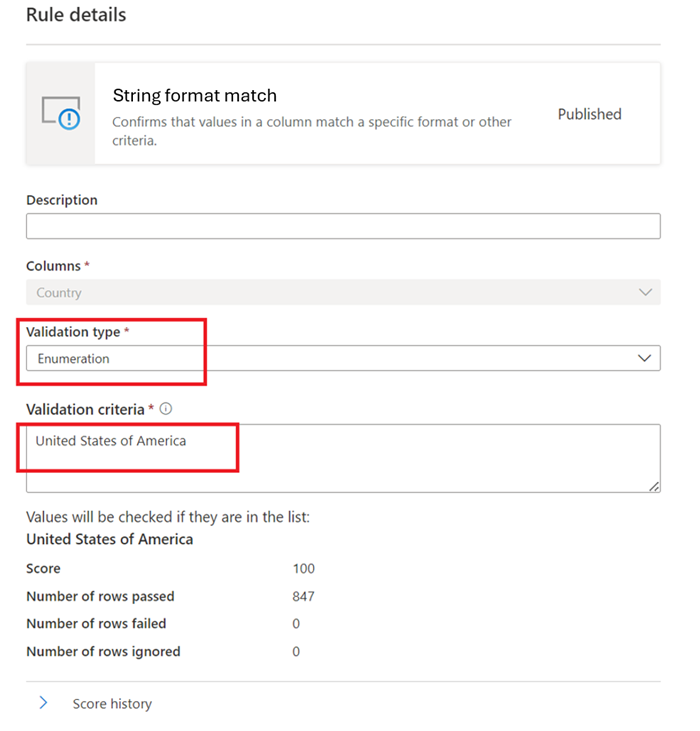
Correspondance de format de chaîne
La règle de correspondance de format vérifie si toutes les valeurs de la colonne sont valides. Si vous ne définissez pas la règle champs vides/vides sur une colonne, la règle ignore les valeurs null ou vides.
Cette règle peut valider chaque valeur de la colonne à l’aide de trois approches différentes :
-
Énumération : cette approche utilise une liste de valeurs séparées par des virgules. Si la valeur que vous évaluez ne correspond pas à l’une des valeurs répertoriées, la case activée échoue. Vous pouvez échapper des virgules et des barres obliques inverses à l’aide d’une barre oblique inverse (
\). Par conséquent,a \, b, ccontient deux valeurs : la première esta , bet la seconde estc.
Like Pattern :
like(<i><string></i> : string, <i><pattern match></i> : string) => booleanle modèle est une chaîne qui correspond littéralement à la règle. Les exceptions sont les symboles spéciaux suivants : _ correspond à n’importe quel caractère dans l’entrée (comme dansposixles expressions régulières) % correspond à.zéro ou plusieurs caractères dans l’entrée (comme.dansposixles expressions régulières). Le caractère d’échappement est.Si un caractère d’échappement précède un symbole spécial ou un autre caractère d’échappement, le caractère suivant est mis en correspondance littéralement. L’échappement d’un autre caractère n’est pas valide.like('icecream', 'ice%') -> true

Expression régulière :
regexMatch(<i><string></i> : string, <i><regex to match></i> : string) => booleanVérifie si la chaîne correspond au modèle d’expression régulière donné. Utilisez
<regex>(guillemet précédent) pour faire correspondre une chaîne sans échappement.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true

Correspondance du type de données
La règle de correspondance de type de données spécifie le type de données attendu pour la colonne associée. Étant donné que le moteur de règles s’exécute sur de nombreuses sources de données différentes, il ne peut pas utiliser de types natifs tels que BIGINT ou VARCHAR. Au lieu de cela, il utilise son propre système de type et traduit les types natifs dans ce système. Cette règle indique au moteur d’analyse de la qualité quels types intégrés utiliser pour le type natif. Le système de type de données provient du système de type Microsoft Azure Data Flow utilisé dans Azure Data Factory.
Pendant une analyse de qualité, le moteur teste tous les types natifs par rapport au type de correspondance de type de données. S’il ne peut pas traduire le type natif en type de correspondance de type de données, il traite cette ligne comme une erreur.

Lignes dupliquées
La règle Lignes en double vérifie si la combinaison des valeurs de la colonne est unique pour chaque ligne de la table.
Dans l’exemple suivant, la concaténation de CompanyName, CustomerID, EmailAddress, FirstName et LastName produit une valeur unique pour toutes les lignes de la table.
Chaque ressource peut avoir zéro ou un instance de cette règle.

Champs vides/vides
La règle Champs vides/vides affirme que les colonnes identifiées ne doivent pas contenir de valeurs Null. Pour les chaînes, la règle interdit également les valeurs vides ou d’espaces blancs uniquement. Lors d’une analyse de la qualité des données, le moteur traite comme correcte toute valeur de cette colonne qui n’est pas null. Cette règle affecte d’autres règles telles que les règles valeurs uniques ou règles de correspondance de format . Si vous ne définissez pas cette règle sur une colonne, ces règles ignorent automatiquement les valeurs Null lorsqu’elles s’exécutent sur cette colonne. Si vous définissez cette règle sur une colonne, ces règles examinent les valeurs null ou vides sur cette colonne et les considèrent à des fins de score.

Recherche de table
La règle de recherche table examine chaque valeur de la colonne dans laquelle vous définissez la règle et la compare à une table de référence. Par exemple, une table primaire a une colonne appelée « emplacement » qui contient des villes, des états et des codes postaux sous la forme « ville, zip d’état ». Une table de référence appelée « citystate » contient toutes les combinaisons légales de villes, d’états et de codes postaux pris en charge dans le États-Unis. L’objectif est de comparer tous les emplacements de la colonne actuelle à cette liste de références pour s’assurer que seules les combinaisons juridiques sont utilisées.
Pour configurer cette règle, entrez le nom « citystatezip » dans la boîte de dialogue de recherche des ressources. Sélectionnez ensuite la ressource souhaitée et la colonne à comparer.

Remarque
La table de référence ou la ressource de données doit appartenir au même domaine de gouvernance. Vous ne pouvez pas comparer une ressource de données dans différents domaines de gouvernance.
Règles personnalisées
La règle personnalisée vous permet de spécifier des règles qui valident les lignes en fonction d’une ou plusieurs valeurs de cette ligne. Vous pouvez utiliser le langage d’expression régulière, l’expression Azure Data Factory et le langage d’expression SQL pour créer des règles personnalisées.
Une règle personnalisée comprend trois parties :
Expression de ligne : cette expression booléenne s’applique à chaque ligne approuvée par l’expression de filtre. Si cette expression retourne true, la ligne passe. Si elle retourne false, la ligne échoue.
Expression de filtre : cette condition facultative réduit le jeu de données sur lequel la condition de ligne est évaluée. Vous l’activez en cochant la case Utiliser l’expression de filtre . Cette expression renvoie une valeur booléenne. L’expression de filtre s’applique à une ligne et si elle retourne true, cette ligne est prise en compte pour la règle. Si l’expression de filtre retourne false pour cette ligne, cela signifie que la ligne est ignorée pour les besoins de cette règle. Le comportement par défaut de l’expression de filtre consiste à passer toutes les lignes. Par conséquent, si vous ne spécifiez pas d’expression de filtre, toutes les lignes sont prises en compte.
Expression Null : vérifie comment les valeurs NULL doivent être gérées. Cette expression retourne une valeur booléenne qui gère les cas où des données sont manquantes. Si l’expression retourne true, l’expression de ligne n’est pas appliquée.
Chaque partie de la règle fonctionne de la même façon que les conditions de Qualité des données Microsoft Purview existantes. Une règle passe uniquement si l’expression de ligne prend la valeur TRUE pour le jeu de données qui correspond à l’expression de filtre et gère les valeurs manquantes comme spécifié dans l’expression null.
Exemple : Une règle pour garantir que « fareAmount » est positif et que « tripDistance » est valide :
- Expression de ligne : tripDistance > 0 AND fareAmount > 0
- Expression de filtre : paymentType = 'CRD'
- Expression Null : tripDistance IS NULL
Créer une règle personnalisée
- Dans Catalogue unifié, accédez à Gestion de> l’intégritéQualité des données.
- Sélectionnez un domaine de gouvernance, un produit de données, puis une ressource de données.
- Sous l’onglet Règles , sélectionnez Nouvelle règle.
Créer une règle personnalisée à l’aide de l’expression Azure Data Factory (ADF)
Pour créer la règle à l’aide d’une expression régulière ou d’une expression ADF, sélectionnez Personnalisé dans la liste des options de règle, puis sélectionnez Suivant.
Ajoutez le nom de la règle et la description, puis sélectionnez Créer.

Exemples de règles personnalisées
| Scénario | Expressions |
|---|---|
| Vérifiez si state_id est égal à la Californie et aba_Routing_Number correspond à un certain modèle d’expression régulière, et si la date de naissance se situe dans une certaine plage | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Vérifier si VendorID est égal à 124 | {VendorID}=='124' |
| Vérifier si fare_amount est égal ou supérieur à 100 | {fare_amount} >= "100" |
| Vérifiez si fare_amount est supérieur à 100 et tolls_amount n’est pas égal à 100 | {fare_amount} >= "100"||{tolls_amount} != "400" |
| Vérifier si l’évaluation est inférieure à 5 | Rating < 5 |
| Vérifier si le nombre de chiffres dans l’année est de 4 | length(toString(year)) == 4 |
| Comparer deux colonnes bbToLoanRatio et bankBalance à case activée si leurs valeurs sont égales | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Vérifiez si le nombre de caractères supprimés et concaténés dans firstName, lastName, LoanID, uuid est supérieur à 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Vérifiez si aba_Routing_Number correspond à un modèle d’expression régulière, et si la date de transaction initiale est supérieure à 2022-11-12, et Disallow-Listed a la valeur false, et que bankBalance moyenne est supérieure à 50000, et state_id est égal à « Massachusetts », « Tennessee », « Dakota du Nord » ou « Alabama » | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachusetts' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Alabama') |
| Vérifiez si aba_Routing_Number correspond à un modèle d’expression régulière et si dateOfBirth est compris entre 1968-12-13 et 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Vérifiez si le nombre de valeurs uniques dans aba_Routing_Number est égal à 1 000 000 et si le nombre de valeurs uniques dans EMAIL_ADDR est égal à 1 000 000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
L’expression de filtre et l’expression de ligne sont définies à l’aide du langage d’expression Azure Data Factory, avec le langage défini ici. Toutefois, toutes les fonctions définies pour le langage d’expression ADF générique ne sont pas disponibles. La liste complète des fonctions disponibles se trouve dans la liste Fonctions disponible dans la boîte de dialogue d’expression. Les fonctions suivantes définies ici ne sont pas prises en charge : isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, recherche mise en cache et Fonctions Window.
Remarque
<regex> (guillemet précédent) peut être utilisé dans les expressions régulières incluses dans des règles personnalisées pour faire correspondre une chaîne sans échappement de caractères spéciaux. Le langage d’expression régulière est basé sur Java. Découvrez les expressions régulières et Java et comprenez les caractères qui doivent être placés dans une séquence d’échappement.
Créer une règle personnalisée à l’aide de l’expression SQL
Les règles SQL personnalisées dans Qualité des données Microsoft Purview fournissent un moyen flexible de définir des contrôles de qualité des données à l’aide de prédicats SPARK SQL. Cette fonctionnalité permet aux utilisateurs de créer des règles directement dans Spark SQL pour des scénarios de validation avancés. Seule une expression de ligne est requise ; les expressions filter et null sont facultatives pour une personnalisation ultérieure. Utilisez des règles SQL personnalisées pour répondre à des besoins métier complexes et améliorer la qualité des données, en tirant parti de toutes les fonctionnalités de Spark SQL. Les règles SQL personnalisées permettent une validation de données complexe qui peut ne pas être possible avec les seules expressions ADF. En écrivant des prédicats Spark SQL, vous pouvez répondre à des besoins métier uniques et maintenir des normes de qualité des données élevées.
Pour créer la règle à l’aide du langage d’expression SQL, sélectionnez Personnalisé (SQL) dans la liste des options de règle, puis sélectionnez Suivant.
Ajoutez le nom de la règle et la description, puis sélectionnez Créer.
Scénario Expressions Valide les modèles de chaîne corrects (par exemple, rateCodeId commençant par « 1 » et numérique) et filtre par types de paiement valides. Row: rateCodeId RLIKE '^1[0-9]+$'Filter: paymentType IN ('CRD', 'CSH')Null: rateCodeId IS NULLGarantit des comparaisons de colonnes correctes entre puLocationId et doLocationId, et le prix par rapport à la distance de trajet. Row: puLocationId > doLocationId AND fareAmount > tripDistance * 10'Filter: paymentType <> 'CSH''Null: tripDistance IS NULLVérifie si le paymentType figure dans une liste donnée (Carte, Espèces), en filtrant les lignes en fonction des montants des tarifs. Row: paymentType IN ('CRD', 'CSH')'Filter: fareAmount >= 50Null: paymentType IS NULLGarantit que la distance est comprise dans une plage inclusive (5-10 miles) lors de la gestion de la valeur NULL et du filtrage pour les types de paiement valides. Row: tripDistance BETWEEN 5 AND 10Filter: paymentType <> 'CRD'Null: tripDistance IS NULLGarantit que le jeu de données ne dépasse pas une valeur NULL de 20 % pour fareAmount. Row: (SELECT avg(CASE WHEN fareAmount IS NULL THEN 1 ELSE 0 END) FROM nycyellowtaxidelta1BillionPartitioned) < 0.20'Filter: vendorID IN ('VTS', 'CMT')Vérifie qu’il existe au moins 2 valeurs paymentType distinctes dans le jeu de données. Row: (SELECT count(DISTINCT paymentType) FROM nycyellowtaxidelta1BillionPartitioned) >= 2Filter: vendorID IN ('1', '2')Garantit que le montant tarifaire moyen du jeu de données se situe dans une plage spécifiée (80 <= moy <= 140). Row: (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) BETWEEN 80 AND 140 'Filter: paymentType IN ('CRD', 'CSH')Garantit que la valeur maximale de tripDistance dans le jeu de données est <= 10 miles. Row: (SELECT max(tripDistance) FROM nycyellowtaxidelta1BillionPartitioned) <= 10.0Filter: vendorID IN ('VTS', 'CMT')Garantit que l’écart type de fareAmount est inférieur à un certain seuil (< 30). Row: (SELECT stddev_samp(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) < 30.0Filter: vendorID IN ('VTS', 'CMT')Garantit que le montant tarifaire médian du jeu de données se situe dans le seuil spécifié (<= 15). Row: (SELECT percentile_approx(fareAmount, 0.5) FROM nycyellowtaxidelta1BillionPartitioned) <= 15.0Filter: vendorID IN ('VTS', 'CMT')Garantit que vendorId est unique dans le jeu de données au sein de paymentType spécifique. Row: COUNT(1) OVER (PARTITION BY vendorID) = 1Filter: paymentType IN ('CRD', 'CSH','1', '2')Null: vendorID IS NULLGarantit que la combinaison de puLocationId et doLocationId est unique dans le jeu de données. Row: COUNT(1) OVER (PARTITION BY puLocationId, doLocationId) = 1Filter: paymentType IN ('CRD', 'CSH')Null: puLocationId IS NULL OR doLocationId IS NULLGarantit que vendorId est unique par paymentType. Row: COUNT(1) OVER (PARTITION BY paymentType, vendorID) = 1 ,Filter: rateCodeId < 25, Null: vendorID IS NULLGarantit que le tpepPickupDateTime de la ligne est supérieur à un horodatage de coupure donné. Row: tpepPickupDateTime >= TIMESTAMP '2014-01-03 00:00:00'Filter: paymentType IN ('CRD', 'CSG', '1', '2')Null: tpepPickupDateTime IS NULLChaque voyage doit être effectué dans un délai d'1 heure Row: (unix_timestamp(tpepDropoffDateTime) - unix_timestamp(tpepPickupDateTime)) <= 3600Filter: paymentType IN ('CRD', 'CSH', '1', '2')Null: tpepPickupDateTime IS NULL OR tpepDropoffDateTime IS NULLConserve uniquement le prix le plus élevé par emplacement de prise en charge. Row: row_number() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1, Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0, Null: fareAmount IS NULL OR puLocationId IS NULLTous les tarifs les plus élevés liés par emplacement de prise en charge passent (pas seulement d’abord par row_number). Row: rank() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0Null: fareAmount IS NULL OR puLocationId IS NULLLe tarif ne doit pas diminuer au fil du temps pour chaque type de paiement. Row: fareAmount >= lag(fareAmount) OVER (PARTITION BY paymentType ORDER BY tpepPickupDateTime)Null: tpepPickupDateTime IS NULL OR fareAmount IS NULLTarif de chaque ligne dans un délai de 10 par rapport à la moyenne du groupe par type de paiement. Row: abs(fareAmount - avg(fareAmount) OVER (PARTITION BY paymentType)) <= 10Filter: paymentType IN ('CRD', 'CSH','1','2')Null: fareAmount IS NULLLe total des distances de trajet en cours ne doit pas dépasser 20 miles. Row: sum(tripDistance) OVER (ORDER BY tpepPickupDateTime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) <= 20Filter: paymentType = '1'Null: tripDistance IS NULLVérifie si le tarif de chaque voyage est supérieur à la moyenne mondiale pour les fournisseurs éligibles. Row: fareAmount > (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned)Filter: vendorID IN ('VTS', 'CMT')Null: fareAmount IS NULLVérifie si la valeur tripDistance de chaque ligne est supérieure à la valeur minimale pour son paymentType (Card/Cash). Row: tripDistance > (SELECT min(u.tripDistance) FROM (SELECT tripDistance, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD', 'CSH')Null: tripDistance IS NULLPour chaque voyage, vérifie si le tarif est supérieur à la moyenne pour son type de paiement Row: fareAmount > (SELECT avg(u.fareAmount) FROM (SELECT fareAmount, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD','CSH','1','2') AND vendorID IN ('VTS','CMT')Null: fareAmount IS NULLVérifie si la colonne fareAmount (numérique) peut être correctement représentée sous la forme d’une chaîne correspondant au modèle numérique (nombres positifs avec décimal facultatif). Cela utilise la conversion, car fareAmount est une colonne numérique. Row: CAST(fareAmount AS STRING) RLIKE '^[0-9]+(\.[0-9]+)?$'Filter: paymentType IN ('CRD', 'CSH')Null: fareAmount IS NULLGarantit que le tpepPickupDateTime est un horodatage valide au format aaaa-MM-jj HH :mm :ss. Cette colonne est déjà au format DATETIME Row: to_timestamp(tpepPickupDateTime, 'yyyy-MM-dd HH:mm:ss') IS NOT NULLFilter: paymentType IN ('CRD','CSH')Null: tpepPickupDateTime IS NULLGarantit que les valeurs paymentType sont normalisées en minuscules et n’ont pas d’espaces de début ou de fin. Row: lower(trim(paymentType)) IN ('card','cash') AND length(trim(paymentType)) > 0Null: paymentType IS NULL OR trim(paymentType) = ''Calcule en toute sécurité le ratio de fareAmount à tripDistance, en veillant à ce que la division par zéro ne se produise pas en vérifiant d’abord si tripDistance > 0. Row: CASE WHEN tripDistance > 0 THEN fareAmount / tripDistance ELSE NULL END >= 10Filter: tripDistance > 0 AND vendorID IN ('VTS', 'CMT')Montre comment la fusion peut remplacer des valeurs null par des valeurs par défaut (par exemple, 0,0) et garantit que seules les lignes valides sont retournées. Row: coalesce(fareAmount, 0.0) >= 5Filter: paymentType IN ('CRD','CSH')
Bonnes pratiques pour l’écriture de règles SQL personnalisées
- Gardez les expressions simples. Visez à écrire des expressions claires et simples qui sont faciles à gérer.
- Utilisez les fonctions Spark SQL intégrées. Utilisez la riche bibliothèque de fonctions de Spark SQL pour la manipulation de chaînes, la gestion des dates et les opérations numériques afin de réduire les erreurs et d’améliorer les performances.
- Testez d’abord avec un petit jeu de données. Validez les règles sur un petit jeu de données avant de les appliquer à grande échelle pour identifier les problèmes potentiels au plus tôt.
Limitations et considérations connues pour les règles d’expressions SQL
Références de colonne ambiguës et ombrage de colonnes
Problème : Lorsqu’une colonne apparaît à la fois dans la requête externe et la sous-requête (ou dans différentes parties de la requête) portant le même nom, Spark SQL peut ne pas être en mesure de résoudre la colonne à utiliser. Ce problème entraîne des erreurs logiques ou une exécution incorrecte des requêtes. Ce problème peut survenir dans des requêtes imbriquées, des sous-requêtes ou des jointures, entraînant une ambiguïté ou un ombrage.
Ambiguïté : se produit lorsqu’un nom de colonne est présent à la fois dans la requête externe et dans la sous-requête sans qualification claire, ce qui rend Spark SQL incertain quant à la colonne à référencer.
Ombrage : fait référence au moment où une colonne de la requête externe est « remplacée » ou « ombrée » par la même colonne dans la sous-requête, ce qui entraîne l’ignorer de la référence externe.
Exemple d’expression :
distance_km > ( SELECT min(distance_km) FROM Tripdata t WHERE t.payment_type = payment_type -- ambiguous outer reference )Problème : la payment_type non qualifiée est résolue dans l’étendue la plus proche qui a une colonne de ce nom, c’est-à-dire la t.payment_type interne, et non la payment_type de la ligne externe. Cela transforme le prédicat en t.payment_type = t.payment_type (toujours TRUE), de sorte que votre sous-requête devient un min global au lieu d’un groupe min.
Solution : Pour résoudre cette ambiguïté et éviter l’ombre des colonnes, renommez la colonne interne dans la sous-requête, en veillant à ce que la payment_type de la requête externe reste sans ambiguïté.
Expression corrigée :
distance_km >
(
SELECT min(u.distance_km)
FROM (
SELECT distance_km, payment_type AS pt
FROM Tripdata
) u
WHERE u.pt = payment_type -- this `payment_type` now binds to OUTER row
)
- Dans la sous-requête, la colonne payment_type est alias pt (autrement dit, payment_type AS pt) et you.pt est utilisé dans la condition.
- Dans la requête externe, le payment_type d’origine peut désormais être clairement référencé et Spark SQL le résout correctement en tant que payment_type externe.
Opérations de fenêtre (considérations sur les performances)
- Les opérations de fenêtre telles que ROW_NUMBER() et RANK() peuvent être coûteuses, en particulier pour les jeux de données volumineux. Utilisez-les judicieusement et testez les performances sur des jeux de données plus petits avant de les appliquer à grande échelle. Envisagez d’utiliser PARTITION BY pour réduire l’étendue des données.
Échappement du nom de colonne dans Spark SQL
- Si les noms de colonnes contiennent des caractères spéciaux (tels que des espaces, des traits d’union ou d’autres caractères non alphanumériques), ils doivent être placés dans une séquence d’échappement à l’aide de signets inverses.
- Exemple si le nom de colonne est order-id et que la règle doit être supérieure à 10.
- Expression incorrecte : order-id > 10
- Expression correcte :
`order-id`> 10
Référencement du nom de ressource de données dans les expressions
Lorsque vous référencez votre ressource de données dans des expressions SQL, vous devez suivre des règles de nettoyage spécifiques. Le nom de la ressource de données d’origine n’a pas besoin d’être mis à jour, mais le nom de la ressource de données référencée dans les expressions SQL doit être nettoyé pour répondre aux critères suivants :
| Règle | Description | Exemple : nom d’origine | Exemple - Nom assainit |
|---|---|---|---|
| Caractères autorisés | Seuls les lettres (A-Z, a-z), les chiffres (0-9) et les traits de soulignement (_) sont autorisés. Les caractères spéciaux (espaces, traits d’union, points, etc.) doivent être supprimés. | my-dataset_v1+2023 | mydataset_v12023 |
| Découper les traits de soulignement | Les traits de soulignement au début ou à la fin du nom doivent être supprimés. | my_dataset_ | my_dataset |
| Limite de caractères | Le nom final et nettoyé ne doit pas dépasser 64 caractères. | [Nom long dépassant 64 caractères] | [Les 64 premiers caractères du nom nettoyé] |
Si le nom de votre ressource de données suit déjà ces instructions (c’est-à-dire qu’il ne contient pas de caractères spéciaux, de traits de soulignement de début/de fin, et qu’il se trouve dans la limite de 64 caractères), il peut être utilisé tel quel dans vos expressions SQL sans aucune modification.
Comment nettoyer le nom d’un jeu de données
Procédez comme suit pour vous assurer que le nom de votre jeu de données est valide pour les expressions SQL :
- Supprimer les caractères spéciaux : supprimez tous les caractères, à l’exception des lettres, des chiffres et des traits de soulignement.
- Découper les traits de soulignement : supprimez tous les traits de soulignement de début ou de fin.
- Tronquer : si le nom obtenu dépasse 64 caractères, tronquez-le pour qu’il s’ajuste à la limite de 64 caractères.
Exemple : Nom de la ressource de données f07d724d-82c9-4c75-97c4-c5baf2cd12a4.parquet
- Supprimer les caractères spéciaux : f07d724d82c94c7597c4c5baf2cd12a4parquet
- Découper les traits de soulignement : (N/A dans ce cas, car il n’y a pas de traits de soulignement de début ou de fin.)
- Tronquer : le nom obtenu est de 54 caractères, ce qui est inférieur à la limite de 64 caractères.
Nom de référence SQL final : f07d724d82c94c7597c4c5baf2cd12a4parquet
Remarque
Le nom de la ressource de données d’origine reste inchangé. Seul le nom de la ressource de données utilisé dans les expressions SQL doit suivre ces règles. Pour les noms de colonnes qui contiennent des caractères spéciaux, tels que des espaces ou des traits d’union, vous pouvez les placer dans une séquence d’échappement à l’aide de guillemets précédents dans les expressions SQL.
Les jointures ne sont pas prises en charge
Les règles SQL personnalisées dans Qualité des données Microsoft Purview ne prennent pas en charge les jointures. Les règles doivent fonctionner sur un jeu de données unique. Vous ne pouvez pas joindre plusieurs tables ou jeux de données lors de l’écriture de ces règles personnalisées.
Opérations SQL non prises en charge (DML, DCL et SQL dangereux)
Les règles SQL personnalisées ne prennent pas en charge les opérations DML (Data Manipulation Language) ou DCL (Data Control Language) telles que INSERT, UPDATE, DELETE, GRANT et d’autres opérations SQL nuisibles comme TRUNCATE, DROP et ALTER. Ces opérations ne sont pas prises en charge, car elles modifient les données ou l’état de la base de données.
Règles générées automatiquement assistées par IA
La génération de règles automatisées assistées par l’IA pour la mesure de la qualité des données utilise des techniques d’intelligence artificielle (IA) pour créer automatiquement des règles d’évaluation et d’amélioration de la qualité des données. Les règles générées automatiquement sont spécifiques au contenu. La plupart des règles courantes sont générées automatiquement afin que vous n’ayez pas à déployer beaucoup d’efforts dans la création de règles personnalisées.
Pour parcourir et appliquer des règles générées automatiquement :
Sous l’onglet Règles d’une ressource de données, sélectionnez Suggérer des règles.
Parcourez la liste des règles suggérées.

Sélectionnez des règles dans la liste des règles suggérées à appliquer à la ressource de données.



Étapes suivantes
- Configurez et exécutez une analyse de la qualité des données sur un produit de données pour évaluer la qualité de toutes les ressources prises en charge dans le produit de données.
- Passez en revue les résultats de votre analyse pour évaluer la qualité actuelle des données de votre produit de données.