Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel vous guide tout au long de l’utilisation d’un notebook Azure Databricks pour importer des données à partir d’un fichier CSV contenant des données de nom de bébé de health.data.ny.gov dans votre volume catalogue Unity à l’aide de Python, Scala et R. Vous apprenez également à modifier un nom de colonne, à visualiser les données et à enregistrer dans une table.
Spécifications
Pour effectuer les tâches décrites dans cet article, vous devez répondre aux exigences suivantes :
- Votre espace de travail doit avoir le catalogue Unity activé. Pour plus d’informations sur la prise en main du catalogue Unity, consultez Prise en main du catalogue Unity.
- L’utilisateur doit disposer du privilège
WRITE VOLUMEsur un volume, du privilègeUSE SCHEMAsur le schéma parent, et du privilègeUSE CATALOGsur le catalogue parent. - Vous devez avoir l’autorisation d’utiliser une ressource de calcul existante ou d’en créer une. Consultez Calcul ou consultez votre administrateur Databricks.
Conseil
Pour obtenir un bloc-notes terminé pour cet article, consultez Importer et visualiser des blocs-notes de données.
Étape 1 : créer un notebook
Pour créer un bloc-notes dans votre espace de travail, cliquez sur ![]() dans la barre latérale, puis sur Bloc-notes. Un notebook vide s’ouvre dans l’espace de travail.
dans la barre latérale, puis sur Bloc-notes. Un notebook vide s’ouvre dans l’espace de travail.
Pour en savoir plus sur la création et la gestion de blocs-notes, consultez Gérer les blocs-notes.
Étape 2 : Définir des variables
Dans cette étape, vous définissez des variables à utiliser dans l’exemple de notebook que vous créez dans cet article.
Copiez et collez le code suivant dans la nouvelle cellule de notebook vide. Remplacez
<catalog-name>,<schema-name>et<volume-name>par les noms de catalogue, de schéma et de volume d’un volume Unity Catalog. Remplacez éventuellement la valeurtable_namepar le nom de table de votre choix. Plus loin dans cet article, vous allez charger les données des noms de nouveaux-nés dans cette table.Appuyez sur
Shift+Enterpour exécuter la cellule et créer une cellule vide.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathLangage de programmation Scala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Étape 3 : Importer le fichier CSV
Dans cette étape, vous importez un fichier CSV contenant des données de nom de bébé à partir de health.data.ny.gov dans votre volume de catalogue Unity.
Copiez et collez le code suivant dans la nouvelle cellule de notebook vide. Ce code copie le fichier
rows.csvde health.data.ny.gov vers votre volume de catalogue Unity à l'aide de la commande Databricks dbutils.Appuyez sur
Shift+Enterpour exécuter la cellule et passer à la cellule suivante.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Langage de programmation Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Étape 4 : Charger les données CSV dans un DataFrame
Dans cette étape, vous créez un DataFrame nommé df à partir du fichier CSV que vous avez précédemment chargé dans votre volume de catalogue Unity à l’aide de la méthode spark.read.csv .
Copiez et collez le code suivant dans la nouvelle cellule de notebook vide. Ce code charge les données des noms de nouveaux-nés dans le DataFrame
dfà partir du fichier CSV.Appuyez sur
Shift+Enterpour exécuter la cellule et passer à la cellule suivante.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Langage de programmation Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Vous pouvez charger des données à partir de nombreux formats de fichiers pris en charge.
Étape 5 : visualiser des données depuis un notebook
Dans cette étape, vous utilisez la méthode display() pour afficher le contenu du DataFrame dans un tableau du notebook, puis vous visualisez les données dans un graphique de nuage de mots dans le notebook.
Copiez et collez le code suivant dans la nouvelle cellule de bloc-notes vide, puis cliquez sur Exécuter la cellule pour afficher les données d’un tableau.
Python
display(df)Langage de programmation Scala
display(df)R
display(df)Passez en revue les résultats dans le tableau.
En regard de l’onglet Tableau , cliquez + , puis cliquez sur Visualisation.
Dans l’éditeur de visualisation, cliquez sur Type de visualisation et vérifiez que le cloud Word est sélectionné.
Dans la colonne Mots, assurez-vous que
First Nameest sélectionné.Dans la limite des fréquences, cliquez sur
35.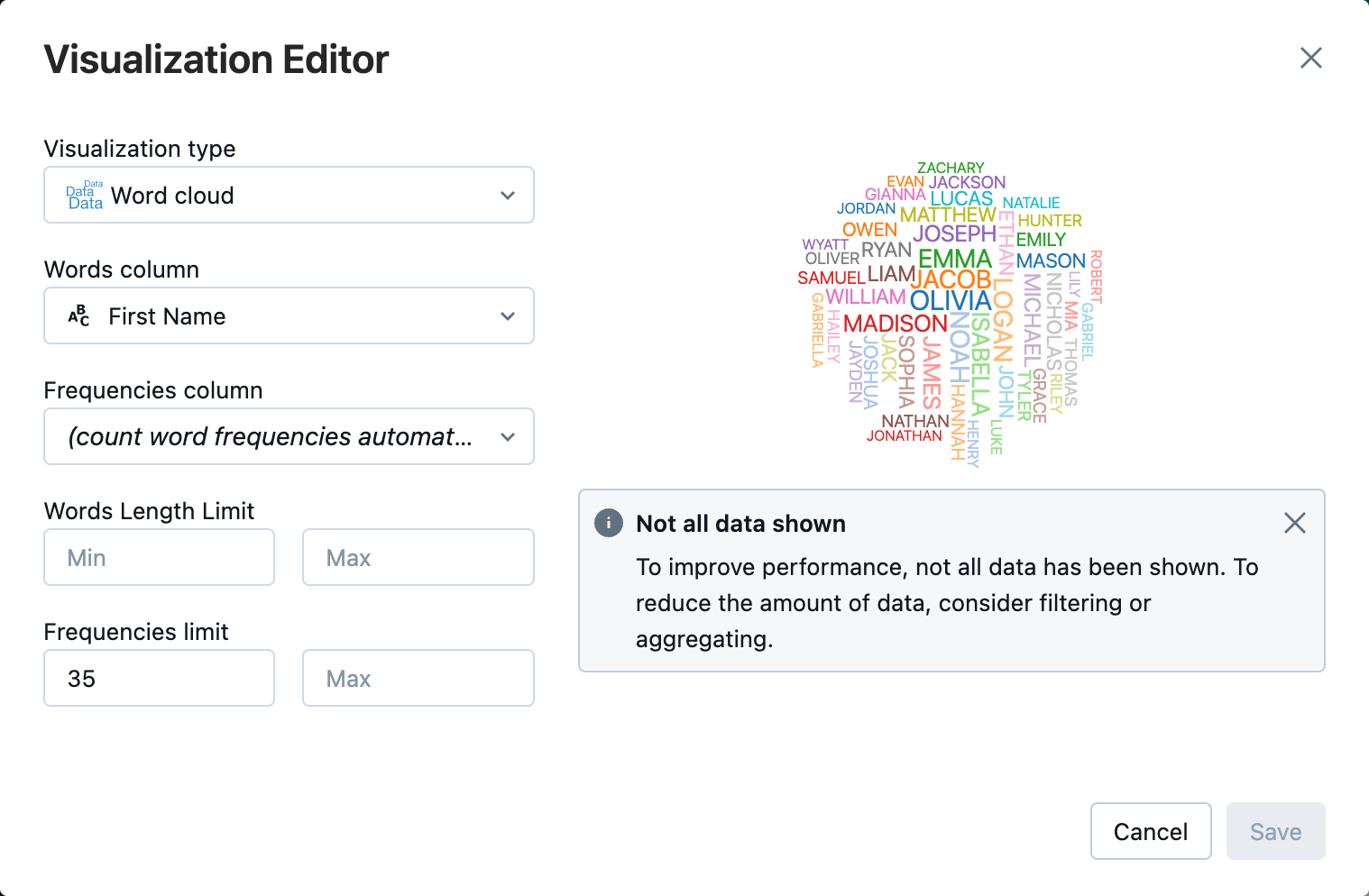
Cliquez sur Enregistrer.
Étape 6 : enregistrer le DataFrame dans une table
Importante
Pour enregistrer votre DataFrame dans Unity Catalog, vous devez avoir des privilèges de table CREATE sur le catalogue et le schéma. Pour plus d’informations sur les autorisations dans le catalogue Unity, consultez Privilèges et objets sécurisables dans le catalogue Unity et Gérer les privilèges dans le catalogue Unity.
Copiez et collez le code suivant dans une cellule de notebook vide. Ce code remplace un espace dans le nom d’une colonne. Les caractères spéciaux, tels que les espaces, ne sont pas autorisés dans les noms de colonnes. Ce code utilise la méthode Apache Spark
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaLangage de programmation Scala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Copiez et collez le code suivant dans une cellule de notebook vide. Ce code enregistre le contenu du DataFrame dans une table d’Unity Catalog en utilisant la variable de nom de table définie au début de cet article.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Langage de programmation Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Pour vérifier que la table a été enregistrée, cliquez sur Catalogue dans la barre latérale gauche pour ouvrir l’interface utilisateur de l’Explorateur de catalogues. Ouvrez votre catalogue puis votre schéma pour vérifier que la table apparaît.
Cliquez sur votre tableau pour afficher le schéma de la table sous l’onglet Vue d’ensemble .
Cliquez sur Exemples de données pour afficher 100 lignes de données à partir de la table.
Importer et visualiser des notebooks de données
Utilisez l’un des notebooks suivants pour effectuer les étapes contenues dans cet article. Remplacez <catalog-name>, <schema-name> et <volume-name> par les noms de catalogue, de schéma et de volume d’un volume Unity Catalog. Remplacez éventuellement la valeur table_name par le nom de table de votre choix.
Python
Importer des données de CSV en utilisant Python
Langage de programmation Scala
Importer des données de CSV en utilisant Scala
R
Importer des données de CSV en utilisant R
Étapes suivantes
- Pour en savoir plus sur les techniques d’analyse exploratoire des données ( EDA), consultez Tutoriel : Techniques EDA à l’aide de notebooks Databricks.
- Pour en savoir plus sur la création d’un pipeline ETL (extraction, transformation et chargement), consultez Tutoriel : Créer un pipeline ETL avec Lakeflow Spark Declarative Pipelines et Tutoriel : Créer un pipeline ETL avec Apache Spark sur la Plateforme Databricks