Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Note
Fabric Runtime 2.0 est actuellement en préversion expérimentale. Pour plus d’informations, consultez les limitations et les notes.
Fabric Runtime offre une intégration transparente au sein de l’écosystème Microsoft Fabric, offrant un environnement robuste pour l’ingénierie des données et les projets de science des données optimisés par Apache Spark.
Cet article présente Fabric Runtime 2.0 Experimental (préversion), le dernier runtime conçu pour les calculs Big Data dans Microsoft Fabric. Il met en évidence les principales fonctionnalités et composants qui font de cette version une étape importante pour l’analytique évolutive et les charges de travail avancées.
Fabric Runtime 2.0 intègre les composants et mises à niveau suivants conçus pour améliorer vos fonctionnalités de traitement des données :
- Apache Spark 4.0
- Système d’exploitation : Azure Linux 3.0 (Mariner 3.0)
- Java : 21
- Scala : 2.13
- Python : 3.12
- Delta Lake : 4.0
Activer Runtime 2.0
Vous pouvez activer Runtime 2.0 au niveau de l’espace de travail ou au niveau de l’élément d’environnement. Utilisez le paramètre d’espace de travail pour appliquer Runtime 2.0 comme valeur par défaut pour toutes les charges de travail Spark de votre espace de travail. Vous pouvez également créer un élément d’environnement avec Runtime 2.0 à utiliser avec des notebooks spécifiques ou des définitions de travaux Spark, qui remplace la configuration par défaut de l’espace de travail.
Activer Runtime 2.0 dans les paramètres de l’espace de travail
Pour définir Runtime 2.0 comme valeur par défaut pour l’ensemble de votre espace de travail :
Accédez à la tabulation Paramètres de l’espace de travail dans votre espace de travail Fabric.
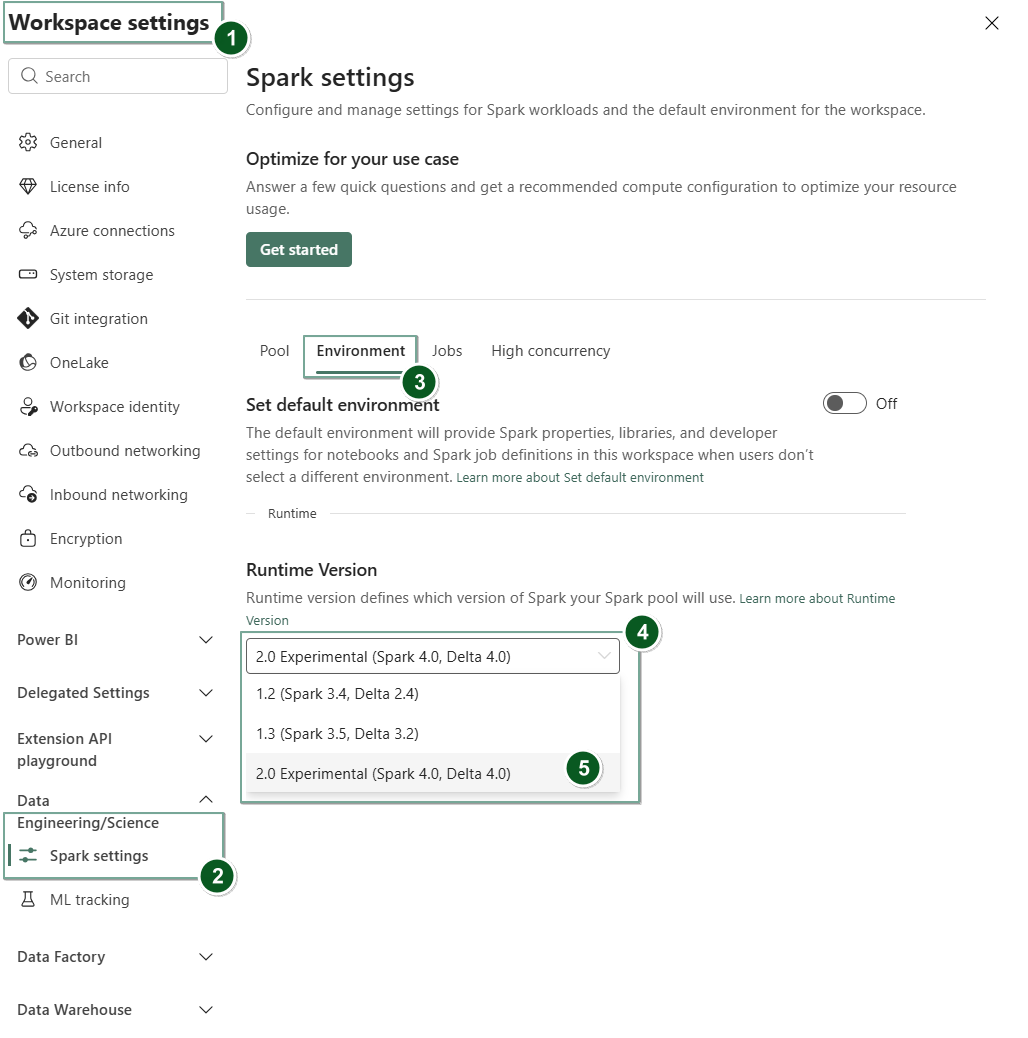
Accédez à l’onglet Ingénierie/Science des données , puis sélectionnez Paramètres Spark.
Sélectionnez l’onglet Environnement.
Dans la liste déroulante version du runtime , sélectionnez 2.0 Expérimental (Spark 4.0, Delta 4.0) et enregistrez vos modifications. Cette action définit Runtime 2.0 comme runtime par défaut pour votre espace de travail.

Activer Runtime 2.0 dans un élément d’environnement
Pour utiliser Runtime 2.0 avec des notebooks spécifiques ou des définitions de tâches Spark :
Créez un élément d’environnement ou ouvrez-en un et existant.
Dans la liste déroulante Runtime, sélectionnez 2.0 Expérimental (Spark 4.0, Delta 4.0)
SaveetPublishvos modifications.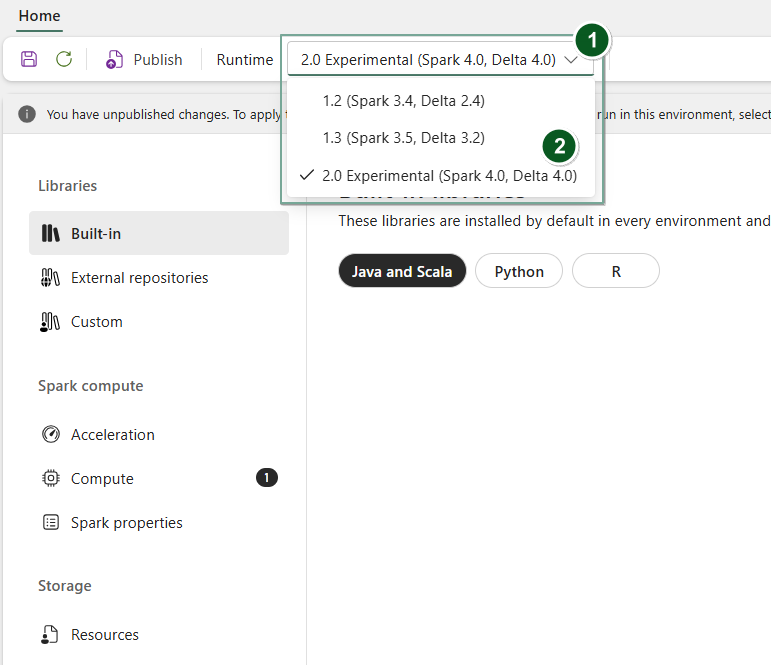
Important
Le démarrage des sessions Spark 2.0 peut prendre environ 2 à 5 minutes, car les pools de démarrage ne font pas partie de la version expérimentale anticipée.
Ensuite, vous pouvez utiliser cet élément d’environnement avec votre
NotebookouSpark Job Definition.

Vous pouvez maintenant commencer à expérimenter les dernières améliorations et fonctionnalités introduites dans Fabric Runtime 2.0 (Spark 4.0 et Delta Lake 4.0).
Préversion publique expérimentale
La phase de préversion expérimentale du runtime Fabric 2.0 vous donne un accès anticipé aux nouvelles fonctionnalités et API à partir de Spark 4.0 et Delta Lake 4.0. La préversion vous permet d’utiliser immédiatement les dernières améliorations basées sur Spark, ce qui garantit une préparation et une transition fluide pour les futures modifications telles que les versions plus récentes de Java, Scala et Python.
Conseil / Astuce
Pour obtenir des informations à jour, et une liste détaillée des modifications et des notes de publication spécifiques pour les Runtimes d’exécution Fabric, consultez les versions et mises à jour de Spark Runtimes et abonnez-vous.
Limitations et notes
Fabric Runtime 2.0 est actuellement en préversion publique expérimentale, conçue pour permettre aux utilisateurs d’explorer et d’expérimenter les dernières fonctionnalités et API de Spark et Delta Lake dans les environnements de développement ou de test. Bien que cette version offre l’accès aux fonctionnalités principales, il existe certaines limitations :
Vous pouvez utiliser des sessions Spark 4.0, écrire du code dans des notebooks, planifier des définitions de travaux Spark et utiliser avec PySpark, Scala et Spark SQL. Toutefois, la langue R n’est pas prise en charge dans cette version anticipée.
Vous pouvez installer des bibliothèques directement dans votre code avec pip et conda. Vous pouvez définir des paramètres Spark via les options %%configure dans les notebooks et les SJDs (définitions de travaux Spark).
Vous pouvez lire et écrire dans le Lakehouse avec Delta Lake 4.0, mais certaines fonctionnalités avancées telles que l’ordre V, l’écriture Parquet native, l’autocompaction, l’écriture optimisée, la fusion à faible mélange, la fusion, l’évolution du schéma et le voyage dans le temps ne sont pas incluses dans cette version préliminaire.
Le Conseiller Spark n’est actuellement pas disponible. Toutefois, les outils de surveillance tels que l’interface utilisateur Spark et les journaux sont pris en charge dans cette version préliminaire.
Les fonctionnalités telles que les intégrations de science des données, notamment Copilot et connecteurs, notamment Kusto, SQL Analytics, Cosmos DB et MySQL Java Connector, ne sont actuellement pas prises en charge dans cette version anticipée. Les bibliothèques de science des données ne sont pas prises en charge dans les environnements PySpark. PySpark fonctionne uniquement avec une configuration Conda de base, qui inclut PySpark seul sans bibliothèques supplémentaires.
Les intégrations avec l’élément d’environnement et Visual Studio Code ne sont pas prises en charge dans cette version anticipée.
Il ne prend pas en charge la lecture et l’écriture de données dans des comptes de stockage Azure à usage général v2 (GPv2) avec des protocoles WASB ou ABFS.
Note
Partagez vos commentaires sur Fabric Runtime dans la plateforme Idées. Veillez à mentionner la version et la phase de mise en production à laquelle vous faites référence. Nous apprécions les commentaires de la communauté et hiérarchisons les améliorations en fonction des votes, en veillant à répondre aux besoins des utilisateurs.
Points clés
Apache Spark 4.0
Apache Spark 4.0 marque une étape importante comme la version inaugurale de la série 4.x, qui incarne l’effort collectif de la communauté open source dynamique.
Dans cette version, Spark SQL est considérablement enrichi avec de puissantes nouvelles fonctionnalités conçues pour améliorer l’expressivité et la polyvalence des charges de travail SQL, telles que la prise en charge des types de données VARIANT, les fonctions définies par l’utilisateur SQL, les variables de session, la syntaxe de canal et le classement de chaîne. PySpark voit un dévouement continu tant à l'égard de son étendue fonctionnelle qu'à l'expérience globale des développeurs, en apportant une API de traçage, une nouvelle API de source de données Python, une prise en charge des fonctions définies par l'utilisateur (UDTF) Python et un profilage unifié pour les fonctions définies par l'utilisateur (UDF) PySpark, ainsi que de nombreuses autres améliorations. Structured Streaming évolue avec des ajouts clés qui offrent un meilleur contrôle et une facilité de débogage, notamment l’introduction de l’API d’état arbitraire v2 pour une gestion d’état plus flexible et la source de données d’état pour faciliter le débogage.
Vous pouvez consulter la liste complète et les changements précis ici : https://spark.apache.org/releases/spark-release-4-0-0.html.
Note
Dans Spark 4.0, SparkR est déconseillé et peut être supprimé dans une version ultérieure.
Delta Lake 4.0
Delta Lake 4.0 marque un engagement collectif à rendre Delta Lake interopérable entre les formats, plus facile à utiliser et plus performant. Delta 4.0 est une version majeure avec de puissantes nouvelles fonctionnalités, des optimisations de performance et des améliorations fondamentales pour l'avenir des open data lakehouses.
Vous pouvez consulter la liste complète et les modifications détaillées introduites avec Delta Lake 3.3 et 4.0 ici : https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Important
Les fonctionnalités spécifiques de Delta Lake 4.0 sont expérimentales et fonctionnent uniquement sur des expériences Spark, telles que notebooks et définitions de travaux Spark. Si vous devez utiliser les mêmes tables Delta Lake sur plusieurs charges de travail Microsoft Fabric, n’activez pas ces fonctionnalités. Pour en savoir plus sur les versions et fonctionnalités de protocole compatibles dans toutes les expériences Microsoft Fabric, lisez l’interopérabilité du format de table Delta Lake.
Contenu connexe
- Runtimes Apache Spark dans Fabric - Vue d’ensemble, gestion des versions et prise en charge de plusieurs runtimes
- Guide de migration de Spark Core
- Guide de migration de SQL, des jeux de données et du DataFrame
- Guide de migration de la diffusion en continu structurée
- Guide de migration de l’apprentissage automatique (MLlib)
- Guide de migration du PySpark (Python sur Spark)
- Guide de migration SparkR (R sur Spark)