Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le compartimentage des journaux linéaires est une fonctionnalité du service de modèle personnalisé de régression logistique.
Le binning de données est un moyen de prétraitement des données qui réduit les effets des erreurs d’observation mineures. Au lieu d’examiner toutes les valeurs de données individuelles d’un ensemble, vous divisez le jeu en intervalles, ou compartiments, et remplacez la valeur du compartiment par les valeurs individuelles qui s’y trouvent. Cela est généralement utilisé pour les données où les valeurs ne sont normalement pas distribuées. Les données qui reflètent les activités humaines ou les caractéristiques humaines ont souvent une distribution de queue lourde. Il existe un grand nombre d’entrées de valeur inférieure, avec des valeurs qui peuvent être très volumineuses, mais de plus en plus rares. Il se peut qu’il n’y ait pas de limite quant à la taille des valeurs. Étant donné que ces données sont si répandues, il est difficile de créer un modèle statistique fort à partir de ces données. Si vous regroupez comme des données à la place, vous pouvez obtenir plus de données sur moins d’instances et ainsi créer un modèle plus fort.
Par exemple, nous voulons créer un modèle personnalisé qui utilise la fonctionnalité d’âge des cookies. L’âge du cookie étant stocké en minutes, il peut s’agir d’une valeur comprise entre 1 minute et plusieurs mois (100 000 minutes). Bien que nous puissions voir une différence significative dans les actions de l’utilisateur pour les utilisateurs avec des cookies entre 1 minute et 60 minutes, nous ne verrons probablement pas une différence significative entre les utilisateurs avec des cookies datant de 99 000 minutes et les utilisateurs avec des cookies qui ont 99 060 anciens. Nous avons besoin d’un moyen de créer des compartiments plus petits et plus étroitement espadés pour les valeurs plus petites et des compartiments plus larges et plus répartis pour les plus grandes valeurs.
Pour ce faire, Xandr utilise une technique appelée compartimentage de journal linéaire.
Fonctionnement du compartimentage des journaux linéaires
Le compartimentage de journaux linéaires combine les approches adoptées par le compartimentage linéaire et le compartimentage de journal.
Le compartimentage linéaire augmente la taille de chaque compartiment du même montant pour chaque intervalle. Par exemple, si vous avez créé des compartiments qui ont augmenté de 2 à chaque fois, vous auriez des compartiments à 2, 4, 6, 8, 10, 12, 14, etc. Cela fonctionne bien pour regrouper les valeurs les plus petites dans des compartiments uniformément espadés, mais cela ne résout pas le problème de regroupement des valeurs plus grandes et plus largement espaquées. Même si vous n’avez que des points de données compris entre 100 000 et 100 050, vous avez toujours des compartiments à 100 002 ... 100,048.
Le compartimentage de journal augmente la taille du compartiment d’une puissance de deux pour chaque intervalle. Il en résulte des compartiments à 2, 4, 8, 16, 32, 64, 128, et ainsi de suite. Cela fonctionne bien pour le regroupement de valeurs importantes et largement réparties, mais a moins d’équilibrage pour les intervalles entre des nombres plus petits.
Le compartimentage des journaux linéaires utilise le compartimentage linéaire pour une plage initiale spécifiée, puis effectue un compartimentage logarithmique pour le reste des valeurs.
Ce graphique trace l’augmentation de la taille des compartiments. L’axe x est la valeur de la fonctionnalité et l’axe y est le numéro de compartiment.
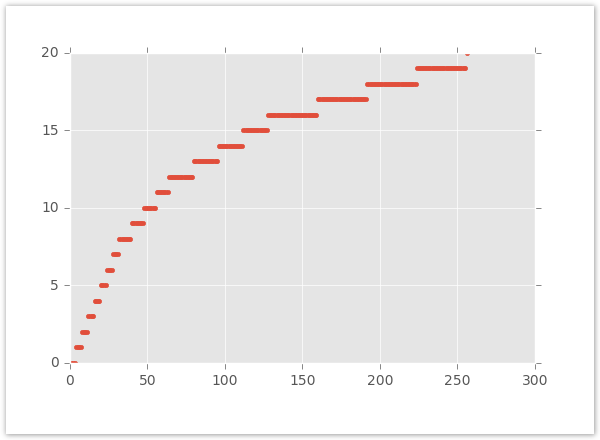
Xandr prend également en charge le sous-compartimentage pour réduire la marge d’erreur et vous donner plus de contrôle sur le fonctionnement du compartimentage. Vous pouvez créer des sous-compartiments pour subdiviser chaque compartiment en quelques compartiments plus petits. Cela est particulièrement utile à l’extrémité plus large de votre plage logarithmique.