Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Pour soutenir la capacité de notre client à prédire la réponse des utilisateurs à leur publicité numérique, Xandr fournit des modèles personnalisés basés sur des arbres de décision. Nous avons développé un langage de programmation facile à utiliser appelé Bonsai qui permet aux utilisateurs de créer des arbres de décision pour remplir dynamiquement les paramètres des éléments de ligne.
Les arbres de décision fonctionnent bien pour les modèles discrets simples qui correspondent à des formes de prédiction traditionnelles basées sur le ciblage, mais qui ont du mal à modéliser efficacement ce qui équivaut à une matrice éparse de nombreuses dimensions et de grandes caractéristiques catégorielles. Bonsai est facile à comprendre et facile à utiliser, mais pas toujours suffisant pour les machines et les scientifiques des données, car il n’autorise pas la représentation efficace des relations entre les fonctionnalités. Pour ces besoins plus complexes, Xandr utilise des modèles de régression logistique.
La régression logistique est l’approche de base pour prédire la probabilité d’une réponse binaire (cliquer ou ne pas cliquer ; acheter ou ne pas acheter) à partir d’une combinaison de plusieurs signaux. En utilisant la régression logistique, les scientifiques des données peuvent exécuter des modèles plus expressifs qui produisent des prédictions plus précises et qui peuvent être rapidement entraînés à grande échelle. En créant des algorithmes personnalisés, les clients disposant d’outils sophistiqués de science des données peuvent obtenir de meilleures performances que l’optimisation intégrée fournie par Xandr et peuvent exécuter des modèles hors connexion complexes en temps réel.
Formule de régression logistique
La régression logistique est un algorithme de classification. Il est utilisé pour prédire un résultat binaire (par exemple, cliquer, ne cliquera pas) en fonction d’un ensemble de variables indépendantes.
La formule de régression logistique est la suivante :
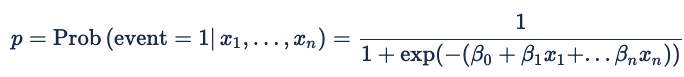
Où la probabilité (p) d’être modélisée est celle d’un résultat binaire : événement = 1 ou événement = 0. Pour la publicité en ligne, l’événement est un clic, un feu de pixels ou une autre action en ligne. La probabilité est conditionnelle aux prédicteurs x1 à xn et à un ensemble implicite de variables qui représentent les caractéristiques d’une demande d’offre. Les coefficients bêta sont les pondérations que le modèle attribue aux différents prédicteurs.
Nous convertissons cette probabilité qu’un événement se produise en valeur attendue en multipliant la probabilité par la valeur de l’événement (par exemple, l’objectif eCPC pour une prédiction de clic), en ajoutant un décalage additif à l’estimation, puis en appliquant des limites de valeur minimale/maximale attendue pour réduire l’impact des erreurs de prédiction.
La formule permettant de dériver une valeur attendue pour une impression à partir de la probabilité qu’un événement se produise est la suivante :
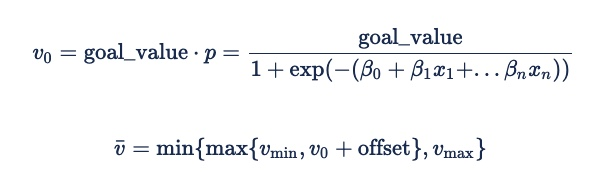
Le décalage est généralement égal à 0. Toutefois, une valeur négative peut être utile en tant que facteur de sécurité pour garantir les performances au détriment de la livraison sur des stocks peu performants. Cela permettra de s’assurer que l’annonceur ne soumissionne pas au lieu d’enchérir très peu et peut entraîner des frais fixes.
Exemple utilisant des fonctionnalités catégorielles de la publicité en ligne
La publicité en ligne a de nombreuses caractéristiques catégorielles, c’est-à-dire des fonctionnalités qui peuvent avoir de nombreuses valeurs possibles. Le navigateur, le domaine et le jour de la semaine en sont des exemples. Ces fonctionnalités sont généralement représentées avec un encodage « à chaud » (utilisant « variables factices »), ce qui signifie que x1 serait 1 si « browser = safari » et 0 si ce n’est pas le cas, x2 serait 1 si « browser = firefox », et ainsi de suite.
Si nous mettons ceci dans la formule de régression logistique, nous obtenons :

Étant donné que le navigateur est une fonctionnalité catégorielle, nous pouvons exprimer les coefficients dans une table :
| Navigateur | Coefficient |
|---|---|
| Safari | 1.2 |
| Firefox | 0.8 |
Chaque ligne de cette table est convertie en un terme dans la formule de régression logistique, donc x1 = 1 si « browser = safari » et β safari = 1,2 et x2 = 1 si « browser = firefox » et β firefox = 0,8. L’équation globale est alors la suivante :
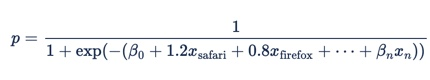
D’autres caractéristiques catégorielles peuvent également être exprimées de cette façon. Supposons que nous avons affecté les valeurs suivantes en tant que coefficients aux domaines suivants :
| Domain | Coefficient |
|---|---|
| cnn.com | 2.1 |
| nytimes.com | 0.8 |
| yahoo.com | 0.3 |
Ces valeurs deviennent ensuite des termes incrémentiels dans la formule (x3 est 1 si « domaine = cnn.com » et β 3 est 2.1), ce qui donne l’équation globale :

Lorsque l’impression publicitaire est servie, Xandr identifie le navigateur comme Safari et le domaine comme nytimes.com. Les variables correspondantes pour browser = Safari et domain = nytimes.com sont définies sur 1 et les autres variables sont définies sur 0, ce qui aboutit à l’équation :
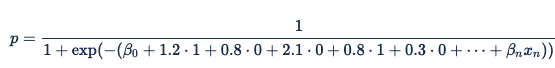
Prédicteurs d’ordre supérieur
Xandr prend en charge les prédicteurs d’ordre supérieur (combinaisons de caractéristiques), ce qui permet aux modèles personnalisés de gérer les interactions complexes entre les prédicteurs. Commencez par l’exemple précédent pour calculer une valeur basée sur les valeurs catégorielles de domaine et de navigateur. Imaginez maintenant que domaine et navigateur ne sont pas indépendants et que vous devez modéliser la relation entre eux. Pour ce faire, vous pouvez créer une fonctionnalité catégorielle bidirectionnel avec un coefficient pour chaque paire de caractéristiques, en utilisant les valeurs spécifiées dans le tableau ci-dessous :
| Navigateur | Domain | Coefficient |
|---|---|---|
| Safari | cnn.com | 1.1 |
| Safari | nytimes.com | 1.3 |
| Safari | yahoo.com | 1.2 |
| Firefox | cnn.com | 3.3 |
| Firefox | nytimes.com | 0.7 |
| Firefox | yahoo.com | 0,1 |
Chacun de ces prédicteurs jumelés devient un terme dans l’équation de régression logistique :
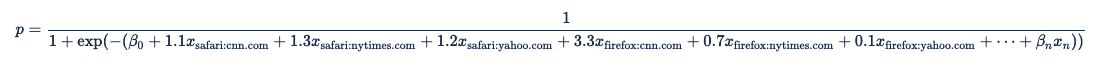
Prédicteurs hachés
La combinaison de plusieurs prédicteurs catégoriels crée des tables extrêmement volumineuses qui ne peuvent pas être facilement mappées en mémoire pour un système en temps réel. Au lieu d’essayer d’extraire des valeurs de ces tables, vous pouvez hacher les combinaisons de caractéristiques pour créer des collisions, ce qui réduit le nombre de combinaisons qui doivent être mappées à la mémoire en temps réel.
Exemple de prédicteurs hachés
Par exemple, vous pouvez hacher les combinaisons navigateur-domaine de l’exemple précédent à l’aide d’une fonction de hachage 2 bits :
| Navigateur | Domain | Coefficient |
|---|---|---|
| Safari | cnn.com | 0 |
| Safari | nytimes.com | 1 |
| Safari | yahoo.com | 3 |
| Firefox | cnn.com | 2 |
| Firefox | nytimes.com | 0 |
| Firefox | yahoo.com | 1 |
Calculez ensuite un coefficient pour chaque valeur de hachage. Notez qu’il y a moins de fonctionnalités que dans l’exemple précédent, ce qui peut capturer une partie de l’interaction entre les fonctionnalités sans nécessiter autant de mémoire.
| hachage Browser-Domain | Coefficient |
|---|---|
| 0 | 1.3 |
| 1 | 0.7 |
| 2 | 1,5 |
| 3 | 0.9 |
Une fois que vous remplacez les variables par ces valeurs, l’équation de régression logistique devient :
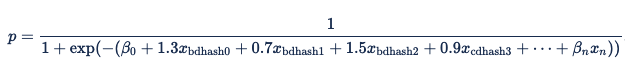
Pour prédire la réponse sur une impression particulière, Xandr hache les fonctionnalités détectées (à l’aide de la même fonction de hachage appliquée pendant l’ingénierie des caractéristiques pour l’entraînement des modèles et l’inférence en ligne). Pour certaines fonctionnalités, nous utilisons des fonctions de hachage pour hacher les valeurs de caractéristique brutes sur celles utilisées dans la formule ci-dessus et exécuter la prédiction. Si le navigateur est Safari et que le domaine est nytimes.com (ou toute autre paire navigateur-domaine qui hache la même valeur), nous les hachons pour trouver la valeur 1 et la remplacer dans l’équation de régression logistique :
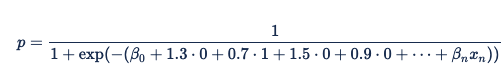
Conversion de vecteurs codés à chaud et de poids en tables
L’encodage des caractéristiques catégorielles garantit que, pour chaque caractéristique catégorielle, au plus une variable recevra la valeur 1 et que toutes les autres recevront la valeur zéro. Le produit point du poids des fonctionnalités du navigateur et les variables du navigateur est donc un moyen détourné d’activer le poids prédéterminé pour le navigateur sur la demande d’enchère. L’API De plateforme numérique utilise l’équation ci-dessous, qui est une fonction sigmoïde standard :
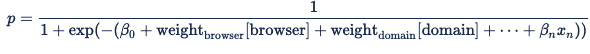
Si nous avons reçu la demande d’annonce suivante :
Si le type de navigateur est Firefox, avec un encodage à chaud x_firefox est défini sur 1 et x_safari est défini sur 0. Le poids activé pour le type Firefox serait son poids prédéterminé de 0,8 multiplié par la valeur codée de 1. Par conséquent , x_firefox équivaudrait à 0,8. Le poids activé pour le type Safari est 0, son poids est prédéterminé, 1,2 multiplié par le paramètre x_safari de 0.
Nous obtenons une équation avec la pondération suivante :

Pour définir le mappage de la fonctionnalité catégorielle au poids, Xandr utilise des appels d’API pour créer et mettre à jour des tables de recherche. Le modèle de régression logistique lui-même fait référence à ces tables et non à un vecteur de variables codées à chaud. Le modèle peut également faire référence directement à des valeurs cardinales ou réelles, y compris l’âge du segment, la valeur du segment et les informations de fréquence ou de récurrence pour un annonceur, un élément créatif ou un élément de ligne.
Exemple de flux de travail
Nous allons utiliser les informations ci-dessus pour créer un exemple de workflow.
Supposons que vous configurez une campagne exploratoire pour collecter des données d’entraînement avec un petit budget. Vous souhaitez optimiser un élément de ligne de reciblage donné pour réduire le coût par clic. Chaque impression gagnée génère une ligne dans les flux de données au niveau du journal avec la is_click colonne définie sur .false Lorsqu’un clic est généré, une ligne identique est générée dans le flux de données avec la is_click colonne définie sur true. Vous partitionnez les données entre les jeux d’apprentissage, de validation et de test en examinant les derniers bits de user_id_64. détermine user_id_64 la partie à laquelle les données seront affectées. Vous déterminez finalement que les variables clés sont les suivantes :
- Navigateur de l’utilisateur (catégoriel)
- Pays et jour de la semaine de l’utilisateur (catégorie supérieure)
- Combinaison de l’éditeur et du pays de l’utilisateur (catégorie supérieure)
- Durée écoulée depuis qu’une annonce pour cet annonceur a été montrée pour la dernière fois à cet utilisateur (récurrence de l’annonceur, valeur cardinale)
Étant donné qu’il n’y a pas beaucoup de navigateurs, il est raisonnable d’avoir un poids pour chaque navigateur dans votre jeu d’entraînement. Le produit croisé, le pays et le jour de la semaine sont également relativement petits. La combinaison de l’éditeur et du pays, cependant, a une cardinalité élevée, donc vous décidez arbitrairement de l’entraîner avec une table hachée de 4 096 entrées. Enfin, la fréquence quotidienne de l’élément de ligne est une valeur cardinale.
Pour chaque ligne dans LLD, vous filtrez d’abord les lignes qui ne proviennent pas de votre campagne de formation. Maintenant que vous avez défini les événements qui vous intéressent, vous pouvez extraire les variables :
- ID de navigateur
- ID de pays
- jour de la semaine de l’utilisateur (en ajoutant le décalage de fuseau horaire à l’horodatage de l’impression et en le mappant à une semaine de 7 jours)
- ID d’éditeur
- la récence de l’annonceur, avec un maximum d’une heure (s’il s’agit de la première annonce que nous affichons à cet utilisateur, la récence par défaut est d’une heure)
Vous réservez un ID de fonctionnalité pour la récence et 4096 ID pour le hachage (publisher :country) et générez dynamiquement des ID de fonctionnalité pour chaque paire de navigateur et (pays :jour de la semaine). La fonctionnalité hachée a besoin d’une étape supplémentaire : vous prenez les deux ID (éditeur et pays), vous les écrivez dans un petit vecteur endian de 8 entiers 32 bits et vous recherchez le compartiment avec MurmurHash3_x86_32 (vecteur, 32, 0xC0FFEE) % 4096 (0xC0FFEE est une valeur initiale arbitraire). Cela vous donne un vecteur (éparse) de valeurs de caractéristiques pour chaque ligne, ce qui vous permet de compter le nombre d’impressions et le nombre de clics pour chaque vecteur de ce type.
Après une journée d’achat lentement d’impressions, vous essayez le modèle de régression logistique que vous avez entraîné sur (un sous-ensemble de) LLD. Le vecteur éparse des valeurs de caractéristique est un encodage à chaud de l’espace des caractéristiques. Vous devez revenir de cet encodage aux fonctions plus logiques, de la valeur catégorielle au poids (tables de recherche). Pour ce faire, joignez la table de caractéristique à l’ID de caractéristique et au vecteur de pondérations pour obtenir les éléments suivants :
| Fonctionnalité | Index | Pondération |
|---|---|---|
| Récurrence de l’annonceur | 0 | -0.2 |
| publisher :country-bucket 0 | 1 | 1.4 |
| publisher :country-bucket 1 | 2 | -2.1 |
| ... | ... | ... |
| publisher :country-bucket 4095 | 4096 | -0.5 |
| browser=safari | 4097 | 5.2 |
| country :day-of-week=US :monday | 4098 | 0.7 |
| ... | ... | ... |
Vous déterminez les pondérations pour chaque fonctionnalité :
- Récurrence de l’annonceur : vous lisez le poids directement à partir du modèle entraîné.
- Table hachée : vous lisez les pondérations des caractéristiques 4096 et vous les placez dans un tableau.
- Navigateur : vous parcourez la carte dynamique de la fonctionnalité à l’ID, les fonctionnalités sont les clés et l’ID les valeurs, et vous créez une table de recherche à partir de l’ID de navigateur au poids non nul (avec zéro comme valeur par défaut) pour créer une liste de mappages de navigateur à pondération.
- Pays :jour de la semaine : vous parcourez la carte dynamique de la fonctionnalité à l’ID et vous créez une table de recherche à partir de l’ID de navigateur au poids non nul (avec zéro comme valeur par défaut) pour créer une liste de mappages de navigateur à poids.
Il s’agit de toutes les données dont vous avez besoin pour appeler l’API AppNexus.
Ce qui se passe au moment de la vente aux enchères
Une fois que l’élément de ligne a réussi le ciblage, Xandr utilise son modèle de régression logistique pour déterminer le prix de l’offre :
- Pour chaque table de recherche dans sa description, Xandr extrait la ou les valeurs du champ (ou des champs) de la demande d’offre et recherche une entrée dans la table. S’il existe une entrée, cette valeur est ajoutée à l’argument linéaire de la fonction logistique. Sinon, la valeur par défaut de la table, qui est généralement 0, est utilisée.
- Il en va de même pour les tables hachées, sauf que Xandr hache les valeurs pour rechercher un compartiment, puis recherche ce compartiment dans la liste des mappages de compartiments -> valeur de la table hachée. Là encore, la valeur par défaut est utilisée si la valeur spécifiée n’apparaît pas dans la table.
- Enfin, Xandr recherche des fonctionnalités Bonsai. Nous effectuons la recherche pour chaque fonctionnalité, multiplions par le poids et appliquons des limites minimales/maximales.
- Xandr additionne ensuite les composants et Beta0 et passe cela à la fonction logistique pour calculer la probabilité estimée d’un clic. La probabilité estimée est multipliée par la valeur de l’objectif pour obtenir la valeur attendue, qui est ensuite limitée entre 1 et 100 CPM pour limiter les évaluations irréalistes.
- Xandr utilise ensuite la valeur attendue et la quantité d’inventaire disponible pour calculer une enchère. Les calculs exacts varient en fonction de la configuration de l’élément de ligne, mais le résultat est que Xandr réduit automatiquement la valeur attendue jusqu’à ce que les enchères soient juste assez élevées pour que l’élément de ligne dépense son budget quotidien à la fin de chaque jour. Pour plus d’informations sur cette mise à l’échelle, consultez Adaptive Pacing (connexion obligatoire) dans la documentation.