이 자습서에서는 의미 체계 링크를 사용하여 공개 Synthea 데이터 세트에서 관계를 감지하는 방법을 보여 줍니다.
새 데이터로 작업하거나 기존 데이터 모델 없이 작업하는 경우 관계를 자동으로 검색하는 것이 유용할 수 있습니다. 이 관계 감지를 통해 다음을 수행할 수 있습니다.
- 상위 수준에서 모델을 이해하기
- 탐색적 데이터 분석 중에 더 많은 인사이트 획득
- 업데이트된 데이터 또는 새로 들어오는 데이터의 유효성 검사
- 데이터 정리
관계가 미리 알려진 경우에도 관계를 검색하면 데이터 모델을 더 잘 이해하거나 데이터 품질 문제를 식별하는 데 도움이 될 수 있습니다.
이 자습서에서는 세 개의 테이블만 실험하는 간단한 기준 예시로 시작하여 테이블 간의 연결을 쉽게 따를 수 있도록 합니다. 그런 다음, 더 큰 테이블 세트를 사용하여 더 복잡한 예시를 보여 줍니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Power BI와의 통합을 지원하고 데이터 분석을 자동화하는 데 도움이 되는 의미 체계 링크의 Python 라이브러리(SemPy) 구성 요소를 사용합니다. 이러한 구성 요소는 다음과 같습니다.
- FabricDataFrame - 추가적인 의미 체계 정보를 통해 향상된 Pandas와 유사한 구조입니다.
- Fabric 작업 영역에서 Notebook으로 의미 체계 모델을 당겨오기 위한 함수입니다.
- 의미 체계 모델에서 관계 발견 및 시각화를 자동화하는 함수입니다.
- 여러 테이블과 상호 종속성이 있는 의미 체계 모델에 대한 관계 발견 프로세스 문제를 해결합니다.
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

- 왼쪽 탐색 창에서 작업 영역을 선택하여 내 작업 영역을 찾아 선택합니다. 이 작업 영역은 현재 작업 영역이 됩니다.
노트북에서 따라오세요
이 자습서에는 relationships_detection_tutorial.ipynb 노트북이 함께 제공됩니다.
이 튜토리얼에 대한 동반 Notebook을 열려면 데이터 과학 튜토리얼을 위한 시스템 준비의 지침에 따라 Notebook을 작업 공간으로 가져오세요.
이 페이지에서 코드를 복사하여 붙여넣으려는 경우 새 Notebook을 만들 수 있습니다.
코드 실행을 시작하기 전에 노트북에 레이크하우스를 연결해야 합니다.
Notebook 설정
이 섹션에서는 필요한 모듈 및 데이터를 통해 Notebook 환경을 설정합니다.
Notebook 내의
SemPy인라인 설치 기능을 사용하여 PyPI에서%pip를 설치합니다.%pip install semantic-link나중에 필요한 SemPy 모듈을 가져옵니다.
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )출력 서식 지정에 도움이 되는 구성 옵션을 적용하기 위해 Pandas를 가져옵니다.
import pandas as pd pd.set_option('display.max_colwidth', None)샘플 데이터를 가져옵니다. 이 자습서에서는 합성 의료 기록의 Synthea 데이터 세트(간소하게 사용하기 위한 소규모 버전)를 사용합니다.
download_synthea(which='small')
Synthea 테이블의 작은 하위 집합에서 관계 감지
더 큰 집합에서 세 개의 테이블을 선택합니다.
-
patients는 환자 정보를 지정합니다. -
encounters는 의료 접촉이 있었던 환자(예: 진료 예약, 수술)를 지정합니다. -
providers는 환자를 진료한 의료 제공자를 지정합니다.
encounters테이블은patients와providers사이의 다 대 다 관계를 해결하며 연관 엔터티로 설명할 수 있습니다.patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
SemPy의
find_relationships함수를 사용하여 테이블 간의 관계를 찾습니다.suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsSemPy의
plot_relationship_metadata함수를 사용하여 관계 DataFrame을 그래프로 시각화합니다.plot_relationship_metadata(suggested_relationships)
해당 함수는 왼쪽에서 오른쪽으로 관계 계층을 배치하는데, 이는 출력의 ‘시작’ 및 ‘대상’ 테이블에 해당합니다. 즉, 왼쪽의 독립적인 ‘시작’ 테이블은 외래 키를 사용하여 오른쪽의 ‘대상’ 종속성 테이블을 가리킵니다. 각 엔터티 상자에는 관계의 ‘출발’ 또는 ‘목적지’ 측에 참여하는 열이 표시됩니다.
기본적으로 관계는 ‘m:1’(‘1:m’이 아님) 또는 ‘1:1’로 생성됩니다. ‘1:1’ 관계는 매핑된 값과 모든 값의 비율이 단방향 또는 양방향으로
coverage_threshold를 초과하는지에 따라 단방향 또는 양방향으로 생성될 수 있습니다. 이 자습서의 뒷부분에서는 빈도가 낮은 ‘m:m’ 관계의 사례를 다룹니다.

관계 감지 문제 해결
기준 예시에서는 클린 Synthea 데이터에 대한 성공적인 관계 감지를 보여 줍니다. 실제로 데이터는 거의 명확하지 않아 성공적인 감지가 불가능합니다. 데이터가 정리되지 않은 경우 유용할 수 있는 몇 가지 기술이 있습니다.
이 자습서의 이 섹션에서는 의미 체계 모델에 더티 데이터가 포함된 경우의 관계 감지에 대해 설명합니다.
먼저 원래 데이터 프레임을 조작하여 ‘더티’ 데이터를 가져오고 더티 데이터의 크기를 인쇄합니다.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))비교를 위해 원래 테이블의 인쇄 크기는 다음과 같습니다.
print(len(patients)) print(len(providers))SemPy의
find_relationships함수를 사용하여 테이블 간의 관계를 찾습니다.find_relationships([patients_dirty, providers_dirty, encounters])코드의 출력은 이전에 ‘더티’ 의미 체계 모델을 만들기 위해 도입한 오류로 인해 관계가 감지되지 않았음을 보여줍니다.
유효성 검사 사용
유효성 검사는 다음과 같은 이유로 관계 감지 실패 문제를 해결하는 데 가장 적합한 도구입니다.
- 특정 관계가 외래 키 규칙을 따르지 않기 때문에 감지할 수 없는 이유를 명확하게 보고합니다.
- 선언된 관계에만 초점을 맞추고 검색을 수행하지 않으므로 대규모 의미 체계 모델에서 빠르게 실행됩니다.
유효성 검사는 find_relationships에서 생성된 것과 유사한 열이 있는 모든 DataFrame을 사용할 수 있습니다. 다음 코드 에서 suggested_relationships DataFrame은 patients가 아닌 patients_dirty를 참조하지만 사전을 사용하여 DataFrame에 별칭을 지정할 수 있습니다.
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
검색 조건 완화
좀 더 모호한 시나리오에서는 검색 조건을 완화해 볼 수 있습니다. 이 방법은 거짓 긍정이 나올 가능성을 증가시킵니다.
include_many_to_many=True를 설정하고 도움이 되는지 평가합니다.find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)결과는
encounters에서patients까지 관계가 검색되었음을 보여 주지만 다음 두 가지 문제가 있습니다.- 관계가 예상 관계와 반대인
patients에서encounters까지로의 방향을 나타냅니다. 이는 환자 행이 누락되었기 때문에 모든patients가encounters에 포함되는 반면(Coverage From= 1.0)encounters는patients에 의해 부분적으로만 포함되기 때문입니다(Coverage To= 0.85). - 낮은 카디널리티
GENDER열에 실수로 일치하는 항목이 있는데, 이는 두 테이블의 이름과 값이 일치하지만 관심 있는 ‘m:1’ 관계는 아닙니다. 낮은 카디널리티는Unique Count From및Unique Count To열로 표시됩니다.
- 관계가 예상 관계와 반대인
‘m:1’ 관계만 찾으려면
find_relationships를 다시 실행하되coverage_threshold=0.5보다 낮게 실행합니다.find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)결과는
encounters에서providers까지의 관계가 올바른 방향을 가지고 있음을 보여줍니다. 그러나encounters에서patients까지의 관계는patients가 고유하지 않아 검색되지 않으므로 ‘m:1’ 관계의 ‘한’ 측에 있을 수 없습니다.include_many_to_many=True및coverage_threshold=0.5모두 느슨하게 하세요.find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)이제 두 관심 관계가 모두 보이지만 노이즈가 훨씬 많이 있습니다.
-
GENDER에 낮은 카디널리티의 일치가 있습니다. -
ORGANIZATION에서 더 높은 카디널리티 'm:m' 일치가 나타나ORGANIZATION이 두 테이블에서 정규화가 해제된 열일 가능성이 높다는 것이 분명해졌습니다.
-
열 이름을 맞추기
기본적으로 SemPy는 이름 유사성을 표시하는 특성만 일치로 간주하며, 데이터베이스 설계자는 일반적으로 관련 열의 이름을 같은 방식으로 지정한다는 사실을 활용합니다. 이 동작은 카디널리티 정수 키가 낮을 때 가장 자주 발생하는 가짜 관계를 방지하는 데 도움이 됩니다. 예를 들어 제품 범주가 1,2,3,...,10이고 주문 상태 코드가 1,2,3,...,10인 경우 열 이름을 고려하지 않고 값 매핑만 살펴보면 서로 혼동될 수 있습니다. 잘못된 관계는 GUID와 유사한 키에서는 문제가 아닙니다.
SemPy는 열 이름과 테이블 이름 간의 유사성을 살펴봅니다. 일치는 대략적이며 대/소문자를 구분하지 않습니다. "id", "code", "name", "key", "pk", "fk"와 같이 가장 자주 발생하는 "decorator" 하위 문자열을 무시합니다. 결과적으로 가장 일반적인 일치 사례는 다음과 같습니다.
- 'foo' 엔터티의 'column'이라는 속성은 'bar' 엔터티의 'column'('COLUMN' 또는 'Column')이라는 속성과 일치합니다.
- 엔터티 'foo'의 'column'이라는 특성이 'bar'의 'column_id'라는 특성과 일치합니다.
- 엔터티 'foo'의 'bar'라는 특성이 'bar'의 'code'라는 특성과 일치합니다.
열 이름을 먼저 일치시키면 감지 속도가 더 빨라집니다.
열 이름을 일치시킵니다.
- 추가 평가를 위해 어떤 열이 선택되었는지 알아보려면
verbose=2옵션을 사용합니다(verbose=1은 처리 중인 엔터티만 나열합니다). -
name_similarity_threshold매개 변수는 열을 비교하는 방법을 결정합니다. 임계값 1은 100% 일치에만 관심이 있음을 나타냅니다.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);100% 유사성으로 실행하면 이름 사이의 작은 차이점을 고려하지 못합니다. 예시에서 테이블에는 ‘s’ 접미사가 있는 복수형이 있으므로 정확한 일치가 없습니다. 이는 기본값
name_similarity_threshold=0.8을 사용하면 잘 처리됩니다.- 추가 평가를 위해 어떤 열이 선택되었는지 알아보려면
기본값
name_similarity_threshold=0.8을 사용하여 다시 실행합니다.find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);이제 복수형
patients의 ID가 실행 시간에 너무 많은 다른 허위 비교를 추가하지 않고 단수형patient와 비교됩니다.기본값
name_similarity_threshold=0을 사용하여 다시 실행합니다.find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);name_similarity_threshold를 0으로 변경하는 것은 다른 극단적인 방법으로, 모든 열을 비교하려고 한다는 것을 나타냅니다. 이는 거의 필요하지 않으며 실행 시간이 늘어나고 검토해야 하는 허위 일치가 발생합니다. 자세한 출력에서 비교 횟수를 관찰할 수 있습니다.
문제 해결 팁 요약
- ‘m:1’ 관계(즉, 기본값
include_many_to_many=False및coverage_threshold=1.0)에 대한 정확한 일치부터 시작합니다. 이것은 보통 당신이 원하는 것입니다. - 테이블의 작은 하위 집합에 좁은 초점을 맞춥니다.
- 유효성 검사를 통해 데이터 품질 문제를 감지합니다.
- 관계에 대해 고려되는 열을 알아보려면
verbose=2를 사용합니다. 이로 인해 많은 양의 출력이 생성될 수 있습니다. - 검색 인수의 상충점에 주의를 기울이세요.
include_many_to_many=True,coverage_threshold<1.0는 분석하기 어려운 허위 관계를 생성할 수 있으므로 필터링이 필요합니다.
전체 Synthea 데이터 세트에서 관계 감지
간단한 기준 예시는 편리한 학습 및 문제 해결 도구였습니다. 실제로는 훨씬 더 많은 테이블이 있는 전체 Synthea 데이터 세트와 같은 의미 체계 모델에서 시작할 수 있습니다. 다음과 같이 전체 synthea 데이터 세트를 탐색해 볼 수 있습니다.
synthea/csv 디렉터리에서 모든 파일을 읽습니다.
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }SemPy의
find_relationships함수를 사용하여 테이블 간의 관계를 찾습니다.suggested_relationships = find_relationships(all_tables) suggested_relationships관계 시각화
plot_relationship_metadata(suggested_relationships)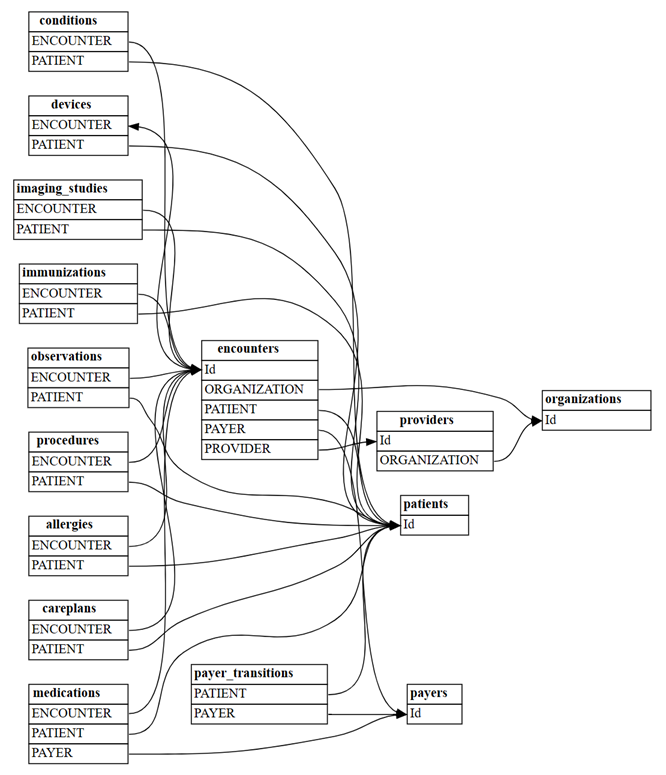
include_many_to_many=True를 사용하면 얼마나 많은 ‘m:m’ 관계가 발견될지 계산합니다. 이러한 관계는 이전에 표시된 ‘m:1’ 관계에 추가되므로multiplicity를 필터링해야 합니다.suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']관계 데이터를 다양한 열별로 정렬하여 해당 특성을 더 깊이 이해할 수 있습니다. 예를 들어 출력을
Row Count From및Row Count To순으로 정렬하여 가장 큰 테이블을 식별할 수 있습니다.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)다른 의미 체계 모델에서는 null의 개수
Null Count From이나Coverage To에 초점을 맞추는 게 중요할 수도 있습니다.이 분석은 어떤 관계가 유효하지 않은지 파악하고, 해당 관계를 후보 목록에서 제거해야 하는지 확인하는 데 도움이 될 수 있습니다.

관련 콘텐츠
의미 체계 링크/SemPy에 대한 다른 자습서를 확인해 볼 수 있습니다.