Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie opisano typy wizualizacji dostępnych do użycia na pulpitach nawigacyjnych sztucznej inteligencji/analizy biznesowej i pokazano, jak utworzyć przykład każdego typu wizualizacji. Aby uzyskać instrukcje dotyczące tworzenia pulpitu nawigacyjnego, zobacz Tworzenie pulpitu nawigacyjnego. Możesz użyć języka naturalnego, aby nakłonić asystenta do tworzenia wykresów słupkowych, liniowych, punktowych, rozrzutu, kołowych i licznikowych. Zobacz Tworzenie wizualizacji za pomocą asystenta usługi Databricks.
Ważne
Ta strona obejmuje wizualizacje pulpitów nawigacyjnych sztucznej inteligencji/analizy biznesowej. Aby uzyskać informacje o wizualizacjach w notesach usługi Azure Databricks i edytorze SQL, zobacz Typy wizualizacji notesu i edytora SQL.
Aby uzyskać informacje na temat limitów renderowania wizualizacji, zobacz Limity pulpitu nawigacyjnego.
Wizualizacja obszaru
Wizualizacje obszarów łączą elementy wizualizacji linii i słupków, aby pokazać, jak wartości liczbowe jednej lub więcej grup zmieniają się w czasie lub innym zmiennym parametrze. Często służą do prezentowania zmian w lejku sprzedaży na przestrzeni czasu.
Aby dostosować układ:
- Kliknij
 menu kebab w sekcji Oś Y panelu edycji wizualizacji.
menu kebab w sekcji Oś Y panelu edycji wizualizacji. - W sekcji Układ wybierz opcję Stack lub 100% Stack.

Wartości konfiguracji: w podanym przykładzie wizualizacji obszaru ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: obszar
- Tytuł:
Total price and order year by order priority and clerk - oś X
- Pole:
o_orderdate - Przekształć:
Yearly - Typ skalowania:
Continuous - Tytuł osi:
Order year
- Pole:
- Oś y:
- Pole:
o_totalprice - Tytuł osi:
Total price - Typ skalowania:
Continuous - Przekształć:
Sum
- Pole:
- Kolor:
- Pole:
o_orderpriority - Tytuł legendy:
Order priority
- Pole:
- Filtr
- Pole:
TPCH orders.o_clerk
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji obszaru użyto następującego zapytania SQL do wygenerowania zestawu danych o nazwie TPCH orders.
SELECT * FROM samples.tpch.orders;
Wykres słupkowy
Wykresy słupkowe przedstawiają, w jaki sposób metryki zmieniają się w czasie lub w różnych kategoriach, oraz obrazują proporcjonalność, podobnie jak wizualizacja kołowa.
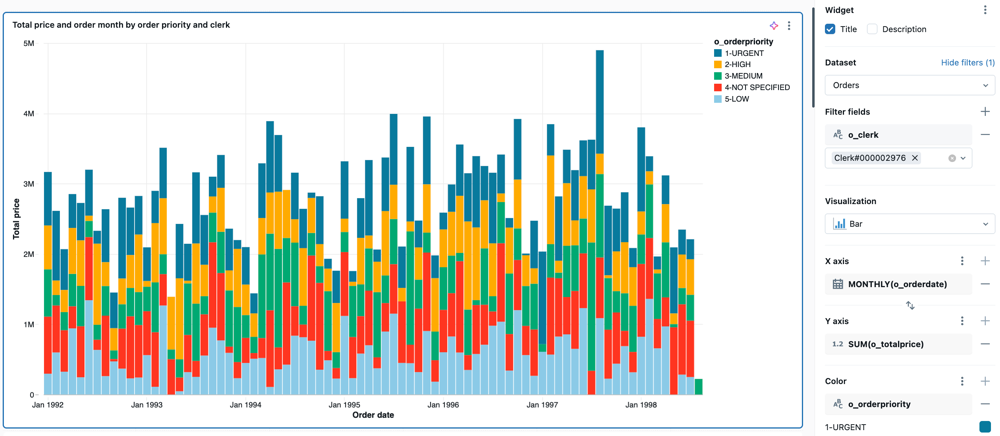
Aby dostosować układ:
- Kliknij menu kebab w sekcji Oś Y panelu edycji wizualizacji.
- W sekcji Układ wybierz pozycję Stos lub 100% Stack lub Grupa.
Wartości konfiguracji: w podanym przykładzie wykresu słupkowego ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: wykres słupkowy
- Tytuł:
Total price and order month by order priority and clerk - oś X
- Pole:
o_orderdate - Przekształć:
Monthly - Typ skalowania:
Continuous - Tytuł osi:
Order month
- Pole:
- Oś y:
- Pole:
o_totalprice - Typ skalowania:
Continuous - Przekształć:
Sum - Tytuł osi:
Total price
- Pole:
- Kolor:
- Pole:
o_orderpriority - Tytuł legendy:
Order priority
- Pole:
- Filtr
- Pole:
TPCH orders.o_clerk
- Pole:
Zapytanie SQL: następujące zapytanie SQL wygenerowało zestaw TPCH orders danych dla tej wizualizacji paska.
SELECT * FROM samples.tpch.orders;
Wykres skrzynkowy
Wizualizacja wykresu skrzynkowego przedstawia podsumowanie rozkładu danych liczbowych, opcjonalnie pogrupowane według kategorii. Korzystając z wizualizacji wykresu skrzynkowego, można szybko porównać zakresy wartości między kategoriami i wizualizować lokalność, rozkład i niesymetryczność grup wartości za pomocą ich kwartylów. W każdym polu ciemniejsza linia pokazuje zakres międzykwartylowy. Aby uzyskać więcej informacji na temat interpretowania wizualizacji wykresu skrzynkowego, zobacz artykuł Box chart w witrynie Wikipedia.

W podanym przykładzie wykresu skrzynkowego ustawiono następujące wartości:
- Kolumna X (kolumna zestawu danych):
l-returnflag - Kolumny Y (kolumna zestawu danych):
l_extendedprice - Tytuł osi X:
Return flag1 - Tytuł osi Y:
Extended price
Zapytanie SQL: w przypadku tej wizualizacji wykresu pola do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT * FROM samples.tpch.lineitem;
Wykres bąbelkowy
Wykresy bąbelkowe to wykresy punktowe, w których rozmiar każdego znacznika punktu odzwierciedla odpowiednią metrykę. Aby utworzyć wykres bąbelkowy, wybierz pozycję Rozrzut jako typ wizualizacji. W ustawieniu Rozmiar wybierz metryki, które mają być reprezentowane przez rozmiar znaczników.

Wartości konfiguracji: w podanym przykładzie wykresu bąbelkowego ustawiono następujące wartości:
- Zestaw danych: przejazdy taksówkami w NOWYM Jorku
- Wizualizacja: punktowa
- Tytuł:
Trip distance, fares, and trip duration - oś X
- Pole:
trip_distance - Typ skalowania:
Continuous - Przekształć:
None
- Pole:
- Oś y:
- Pole:
fare_amount - Typ skalowania:
Continuous - Przekształć:
None
- Pole:
- Kolor według:
- Pole:
pickup_zip
- Pole:
- Rozmiar:
- Pole:
minutes_in_taxi - Przekształć:
None
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji wykresu bąbelkowego do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT
*,
TIMESTAMPDIFF(MINUTE, tpep_pickup_datetime, tpep_dropoff_datetime) AS minutes_in_taxi
FROM samples.nyctaxi.trips
LIMIT 500;
Mapa choropletyczna
W wizualizacjach choropleth lokalizacje geograficzne, takie jak kraje lub stany, są kolorowane zgodnie z zagregowanymi wartościami każdej kolumny klucza. Zapytanie musi zwracać lokalizacje geograficzne według nazwy. Użytkownicy mogą tworzyć mapy, które wyświetlają granice administracyjne na poziomie kraju, stanu lub prowincji oraz powiatu lub okręgu.

Wartości konfiguracji: W tej wizualizacji choropleth ustawiono następujące wartości.
- Zestaw danych: samples.tpch.customer
- Kraj:
Country - Kolor: sum(c_acct_bal)
Zapytanie SQL: w przypadku tej wizualizacji choropleth do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT
INITCAP(n_name) AS Country,
SUM(c_acctbal)
FROM samples.tpch.customer
JOIN samples.tpch.nation WHERE n_nationkey = c_nationkey
GROUP BY 1;
Wykres kohorty
Wykresy kohortowe wizualizuj wzorce przechowywania i zachowania użytkowników w czasie, grupując użytkowników na podstawie udostępnionej charakterystyki (takiej jak data rejestracji) i śledząc ich aktywność w kolejnych okresach. Ta wizualizacja pomaga zrozumieć, jak różne kohorty użytkowników angażują się w produkt lub usługę w czasie.

Aby utworzyć wykres kohortowy, użyj wizualizacji przestawnej z danymi retencji. Poniższy przykład śledzi utrzymanie klientów, obliczając, kiedy klienci po raz pierwszy złożyli zamówienie (ich data kohorty) i mierząc, jak wielu klientów z każdej kohorty pozostaje aktywnych w kolejnych latach. Skala kolorów wskazuje współczynniki przechowywania z ciemniejszymi kolorami pokazującymi wyższe przechowywanie.
Wartości konfiguracji: dla tego przykładu wykresu kohortowego ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: przestawna
- Tytuł:
Customer retention by cohort year - Wiersze
- Pole:
Cohort - Przekształć:
Yearly
- Pole:
- Kolumny:
- Pole:
Active Period
- Pole:
- Komórka:
- Pole:
Retention - Styl:
Color Scale
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji wykresu kohortowego do wygenerowania zestawu Orders cohort analysisdanych użyto następującego zapytania SQL.
-- get the list of customers and when they were active
WITH history AS (
SELECT o_orderdate, o_custkey -- replace with the right columns representing date and id
FROM samples.tpch.orders -- replace with desired table
GROUP BY ALL
),
-- find the date of the first order for each customer
cohort AS (
SELECT o_custkey, MIN(o_orderdate) AS first_date
FROM history
GROUP BY 1
),
-- combine the customer activity table with the date of first activity, and choose a granularity (e.g. YEAR)
joined AS (
SELECT
DATE_TRUNC("YEAR", first_date) AS cohort,
CAST(DATE_DIFF(YEAR, cohort, o_orderdate) AS STRING) AS active,
o_custkey
FROM history LEFT JOIN cohort USING(o_custkey)
),
-- calculate the number of distinct customers by cohort and date active
grouped AS (
SELECT cohort, active, COUNT(DISTINCT o_custkey) AS customers
FROM joined
GROUP BY 1, 2
),
-- calculate the number of initial customers for each cohort
initial_customers AS (
SELECT cohort, customers AS t0_customers
FROM grouped
WHERE active = 0
)
-- calculate the retention by cohort and date active
SELECT
cohort AS Cohort,
active AS Active,
CASE WHEN active = 1 THEN CONCAT(active, " year")
ELSE CONCAT(active, " years") END AS `Active Period`,
customers AS Customers,
t0_customers AS `Initial Customers`,
TRY_DIVIDE(customers, t0_customers) AS Retention
FROM grouped LEFT JOIN initial_customers USING (cohort)
WHERE active > 0;
Kombinowany wykres
Wykresy kombi łączą wykresy liniowe i słupkowe, aby przedstawić zmiany w czasie z proporcjonalnością.

Wartości konfiguracji: dla tej wizualizacji wykresu kombi ustawiono następujące wartości:
- Zestaw danych: samples.tpch.partsupp
- Wizualizacja: kombinacja
- Oś X:
ps_partkey- Typ skalowania:
Continuous
- Typ skalowania:
- Oś y:
- Pasek:
ps_availqty - Typ agregacji:
SUM - Linia:
ps_supplycost - Typ agregacji:
AVG
- Pasek:
- Kolor według serii Y:
Sum of ps_availqtyAverage ps_supplycost
Zapytanie SQL: w przypadku tej wizualizacji wykresu kombi następujące zapytanie SQL zostało użyte do wygenerowania zestawu danych.
SELECT * FROM samples.tpch.partsupp;
Wykres kombi z podwójną osią
Możesz użyć wykresów kombinowanych, aby wyświetlić dwie różne osie y. Po wybraniu widżetu wykresu kombi kliknij ![]() w ustawieniach osi Y w panelu konfiguracji wykresu. Włącz opcję Włącz podwójną oś .
w ustawieniach osi Y w panelu konfiguracji wykresu. Włącz opcję Włącz podwójną oś .

Wartości konfiguracji: opcja Włącz podwójną oś jest włączona dla tego wykresu kombi. Pozostałe konfiguracje są ustawiane w następujący sposób:
- Zestaw danych: samples.nyctaxi.trips
- Wizualizacja: kombinacja
- Oś X:
tpep_pickup_datetime- Przekształć:
Weekly - Typ skalowania:
Continuous
- Przekształć:
- Oś y:
- Lewa oś Y (Słupek):
trip_distance- Przekształć:
AVG
- Przekształć:
- Prawa oś Y (linia):
fare_amount- Przekształć:
AVG
- Przekształć:
- Lewa oś Y (Słupek):
Kolor według serii Y:
Average trip_distanceAverage fare_amount
Zapytanie SQL: następujące zapytanie SQL zostało użyte do wygenerowania zestawu danych:
SELECT * FROM samples.nyctaxi.trips;
Wizualizacja licznika
Liczniki wyświetlają pojedynczą wartość z opcją porównywania ich z wartością odniesienia. Aby użyć liczników, określ, które dane mają być wyświetlane na wizualizacji licznika dla kolumn Value (Wartość ) i Comparison (Porównanie ). Opcjonalnie wybierz kolumnę z datą i agregację, aby pokazać iskrolinię na wykresie.

Możesz ustawić formatowanie warunkowe i dostosować styl tekstu w szczegółach konfiguracji wartości.

Wartości konfiguracji: dla tego przykładu wizualizacji licznika ustawiono następujące wartości:
- Zbiór danych:
samples.tpch.orders - Wizualizacja: licznik
- Tytuł:
Orders: Total price by date (compared to the previous day) - Wartość:
- Data:
DAILY(o_orderdate) - Wartość:
total price
- Data:
- Porównanie:
- Pole:
o_orderdate - Dni temu przesunięcie: -1
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji licznika użyto następującego zapytania SQL do wygenerowania zestawu danych:
SELECT
SUM(o_totalprice) AS `total price`,
o_orderdate
FROM
samples.tpch.orders
GROUP BY o_orderdate
ORDER BY o_orderdate DESC;
Wykres lejkowy
Wykres lejkowy pomaga analizować zmianę metryki na różnych etapach. Aby użyć lejka, określ kolumnę stepvalue i .
Na przykład poniższy wykres lejkowy pokazuje, jak użytkownicy przechodzą przez etapy przepływu rejestracji. Każdy etap reprezentuje krok w procesie, a jego rozmiar odzwierciedla liczbę użytkowników, którzy osiągnęli ten krok.
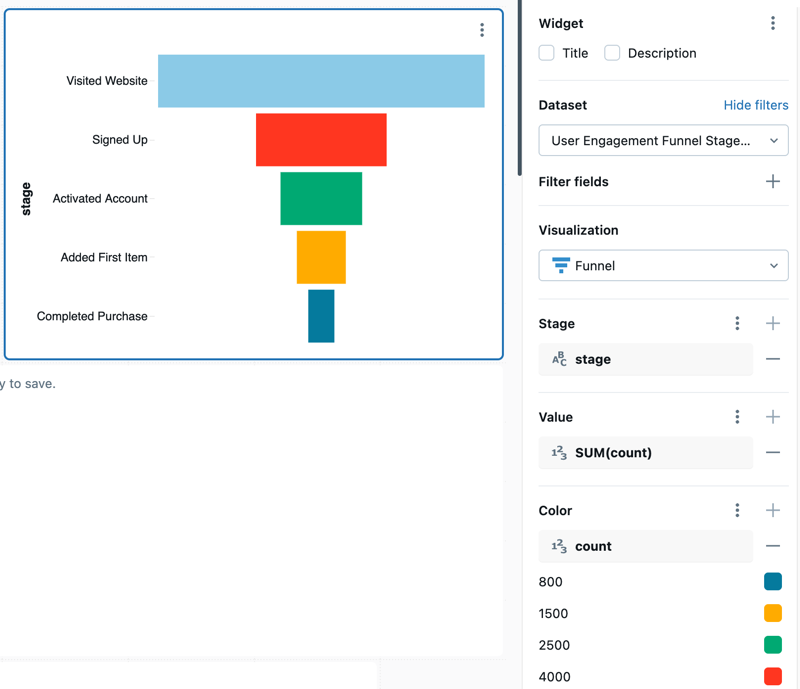
Wartości konfiguracji: dla tego wykresu lejkowego ustawiono następujące wartości:
- Zestaw danych: Etapy lejka zaangażowania użytkowników
- Wizualizacja: lejek
- Oś X:
stage - Oś Y:
count- Typ agregacji:
SUM
- Typ agregacji:
- Kolumna koloru:
- Kolumna zestawu danych:
count
- Kolumna zestawu danych:
Zapytanie SQL: następujące zapytanie SQL wygenerowało zestaw danych dla tej wizualizacji wykresu lejkowego.
SELECT *
FROM VALUES
('Visited Website', 10000),
('Signed Up', 4000),
('Activated Account', 2500),
('Added First Item', 1500),
('Completed Purchase', 800)
AS funnel(stage, count);
Wykres mapy cieplnej
Wykresy cieplne łączą funkcje wykresów słupkowych, skumulowanych wykresów i wykresów bąbelkowych, co pozwala wizualizować dane liczbowe przy użyciu kolorów.
Na przykład poniższa mapa cieplna wizualizuje liczbę zamówień na podstawie ich priorytetu i metody wysyłki. Oś x reprezentuje różne priorytety kolejności, a oś y reprezentuje różne metody wysyłki. Intensywność koloru wskazuje sumę liczby zamówień z legendą pokazującą skalę liczby zamówień.
Uwaga
Mapa cieplna może wyświetlać maksymalnie 64 000 wierszy lub 10 MB.

Wartości konfiguracji: dla tej wizualizacji wykresu mapy cieplnej ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: Mapa cieplna
- Oś X:
priority - Oś Y:
ship_mode - Kolumna koloru:
- Kolumna zestawu danych:
order_count - Typ agregacji:
SUM
- Kolumna zestawu danych:
- Nazwa osi X (zastąpij wartość domyślną):
Order Priority - Nazwa osi Y (Zastąp wartość domyślną):
Shipping method - Rampa kolorów:
Green Blue
Zapytanie SQL: w przypadku tej wizualizacji wykresu mapy cieplnej do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT
o.o_orderpriority AS priority,
l.l_shipmode AS ship_mode,
COUNT(*) AS order_count,
o.o_orderdate
FROM
samples.tpch.orders AS o
JOIN
samples.tpch.lineitem AS l
ON
o.o_orderkey = l.l_orderkey
GROUP BY
o.o_orderpriority,
l.l_shipmode,
o.o_orderdate
ORDER BY
priority,
ship_mode;
Wykres histogramu
Histogram kreśli częstotliwość występowania danej wartości w zestawie danych. Histogram pomaga zrozumieć, czy zestaw danych zawiera wartości, które są grupowane wokół niewielkiej liczby zakresów, czy są bardziej rozłożone. Histogram jest wyświetlany jako wykres słupkowy, w którym kontrolujesz liczbę odrębnych słupków (nazywanych również pojemnikami).
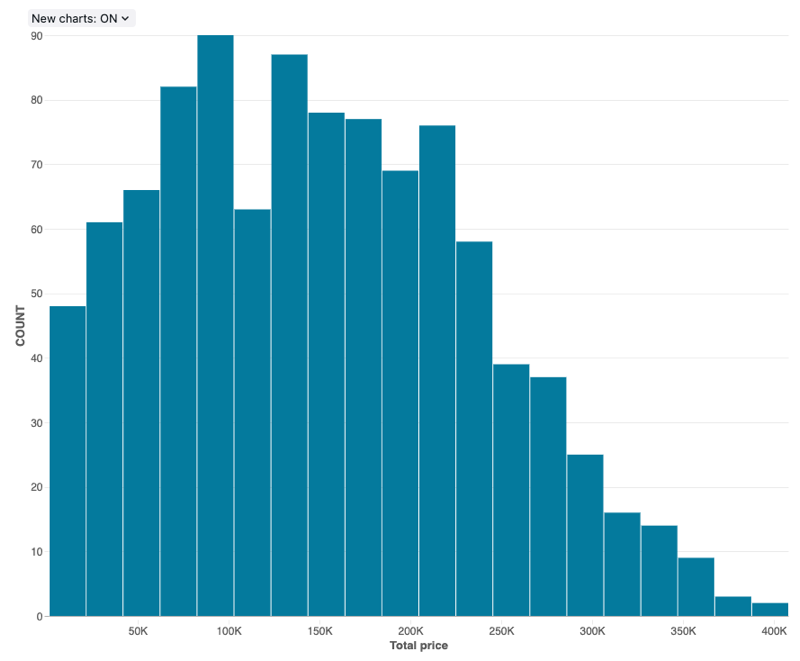
Wartości konfiguracji: dla tej wizualizacji wykresu histogramu ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: Histogram
- Kolumna X (kolumna zestawu danych):
o_totalprice - Liczba pojemników: 20
- Nazwa osi X (zastąpij wartość domyślną):
Total price
Opcje konfiguracji: Aby uzyskać opcje konfiguracji wykresu histogramu, zobacz opcje konfiguracji wykresu histogramu.
Zapytanie SQL: na potrzeby tej wizualizacji wykresu histogramu do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT * FROM samples.tpch.orders;
Wizualizacja linii
Wizualizacje liniowe przedstawiają zmianę w co najmniej jednej metryce w czasie.

Wartości konfiguracji: w tym przykładzie wizualizacji wiersza ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: linia
- Tytuł:
Average price and order year by order priority and clerk - oś X
- Pole:
o_orderdate - Przekształć:
Yearly - Typ skalowania:
Continuous - Tytuł osi:
Order year
- Pole:
- Oś y:
- Pole:
o_totalprice - Przekształć:
Average - Typ skalowania:
Continuous - Tytuł osi:
Average price
- Pole:
- Kolor:
- Pole:
o_orderpriority - Tytuł legendy:
Order priority
- Pole:
Zapytanie SQL: W przypadku tej wizualizacji wykresu liniowego do wygenerowania zestawu danych o nazwie Orders dataużyto następującego zapytania SQL.
SELECT * FROM samples.tpch.orders;
Wizualizacja wykresu kołowego
Wizualizacje kołowe pokazują proporcjonalność między metrykami. Nie są one przeznaczone do przekazywania danych szeregów czasowych.

Wartości konfiguracji: dla tego przykładu wizualizacji kołowej ustawiono następujące wartości:
- Zestaw danych: samples.tpch.orders
- Wizualizacja: Wykres kołowy
- Tytuł:
Total price by order priority and clerk - Kąt:
- Pole:
o_totalprice - Przekształć:
Sum - Tytuł osi:
Total price
- Pole:
- Kolor:
- Pole:
o_orderpriority - Tytuł legendy:
Order priority
- Pole:
- Filtr
- Pole:
TPCH orders.o_clerk
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji kołowej użyto następującego zapytania SQL do wygenerowania zestawu danych o nazwie TPCH orders.
SELECT * FROM samples.tpch.orders;
Wizualizacja przestawna
Wizualizacja przestawna agreguje rekordy z wyniku zapytania do wyświetlania tabelarycznego. Jest to podobne do instrukcji PIVOT lub GROUP BY w języku SQL. Wizualizację przestawną można skonfigurować, przeciągając i upuszczając pola.
Aby uzyskać szczegółowe informacje na temat opcji konfiguracji tabeli przestawnej, w tym nagłówków przylepnych, formatowania warunkowego i dodawania linków, zobacz Konfiguracja tabeli przestawnej.
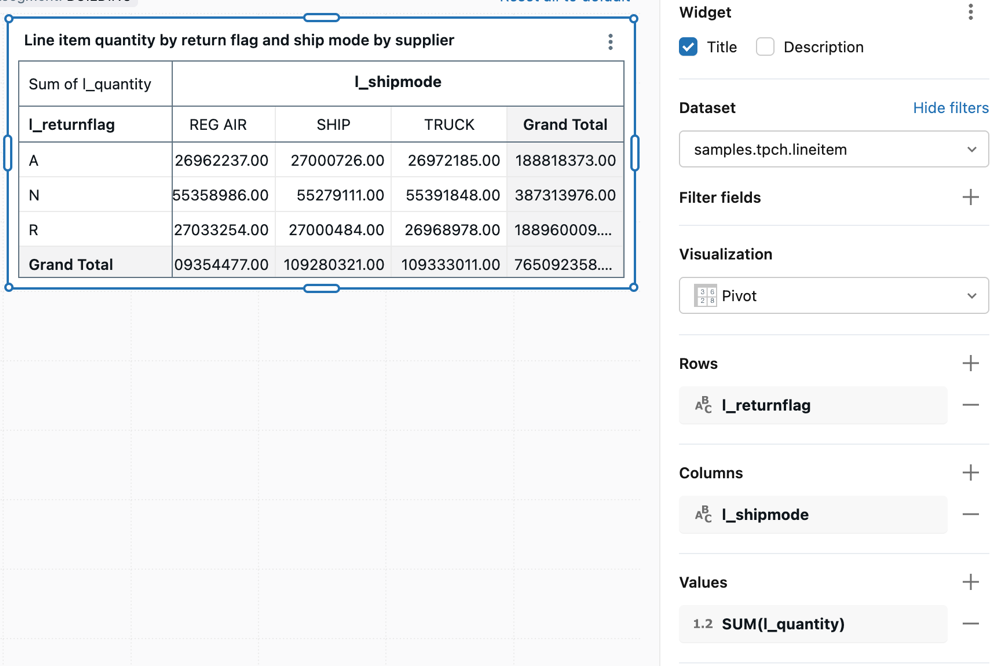
Wartości konfiguracji: w tym przykładzie wizualizacji przestawnej ustawiono następujące wartości:
- Zestaw danych: samples.tpch.lineitem
- Wizualizacja: przestawna
- Tytuł:
Line item quantity by return flag and ship mode by supplier - Wiersze
- Pole:
l_returnflag - Wyświetl sumę: zaznaczone
- Pole:
- Kolumny:
- Pole:
l_shipmode - Wyświetl sumę: zaznaczone
- Pole:
- Wartości
- Pole:
l_quantity - Transformacja: Suma
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji przestawnej użyto następującego zapytania SQL do wygenerowania zestawu danych o nazwie TPCH lineitem.
SELECT * FROM samples.tpch.lineitem;
Mapa punktów
Mapy punktów wyświetlają dane ilościowe jako symbole umieszczone w określonych lokalizacjach mapy. Znaczniki są rozmieszczone przy użyciu współrzędnych szerokości i długości geograficznej, które należy uwzględnić w zestawie wyników dla tego typu wykresu. W poniższym przykładzie użyto danych z kolizji pojazdów samochodowych w Nowym Jorku, NY.

Wartości konfiguracji: dla tej wizualizacji mapy punktów ustawiono następujące wartości:
- Zestaw danych: Analiza cen domów w Seattle
- Wizualizacja: Mapa punktowa
- Współrzędne:
- Szerokość geograficzna:
LATITUDE - Długość:
LONGITUDE
- Szerokość geograficzna:
- Kolor:
- Pole:
avg(bedrooms)- Typ skalowania: kategorialny
- Pole:
- Rozmiar:
- Pole:
avg(price)
- Pole:
Uwaga
Żadne zestawy danych usługi Databricks nie zawierają danych szerokości geograficznej lub długości geograficznej, więc w tym przykładzie nie podano przykładowego zapytania SQL.
Diagram typu Sankey
Diagram sankey wizualizuje przepływ z jednego zestawu wartości do innego.

Wartości konfiguracji: dla tego diagramu sankey ustawiono następujące wartości:
- Zestaw danych: samples.nyctaxi.trips
- Wizualizacja: Sankey
- Etapach
stage1stage2
- Wartość
- SUM(wartość)
Zapytanie SQL: w przypadku tej wizualizacji Sankey do wygenerowania zestawu danych użyto następującego zapytania SQL.
SELECT pickup_zip AS stage1, dropoff_zip AS stage2, SUM(fare_amount) AS value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10;
Wizualizacja punktowa
Wizualizacje punktowe są często używane do pokazywania relacji między dwiema zmiennymi liczbowymi. Możesz zakodować trzeci wymiar z kolorem, aby pokazać, jak zmienne liczbowe różnią się między grupami.

Wartości konfiguracji: dla tego przykładu wizualizacji punktowej ustawiono następujące wartości:
- Zestaw danych: samples.tpch.lineitem
- Wizualizacja: punktowa
- Tytuł:
Total price and quantity by ship mode and supplier - oś X
- Pole:
l_quantity - Tytuł osi:
Quantity - Typ skalowania:
Continuous - Przekształć:
None
- Pole:
- Oś y:
- Pole:
l_extendedprice - Typ skalowania:
Continuous - Przekształć:
None - Tytuł osi:
Price
- Pole:
- Kolor:
- Pole:
l_shipmode - Tytuł legendy:
Ship mode
- Pole:
- Filtr
- Pole:
TPCH lineitem.l_supplierkey
- Pole:
Zapytanie SQL: w przypadku tej wizualizacji punktowej użyto następującego zapytania SQL do wygenerowania zestawu danych o nazwie TPCH lineitem.
SELECT * FROM samples.tpch.lineitem
Wizualizacja tabeli
Wizualizacja tabeli przedstawia dane w standardowej tabeli, ale umożliwia ręczne zmienianie kolejności, ukrywanie i formatowanie danych.
Uwaga
Tabele mogą wyświetlać maksymalnie 64 000 wierszy lub 10 MB.
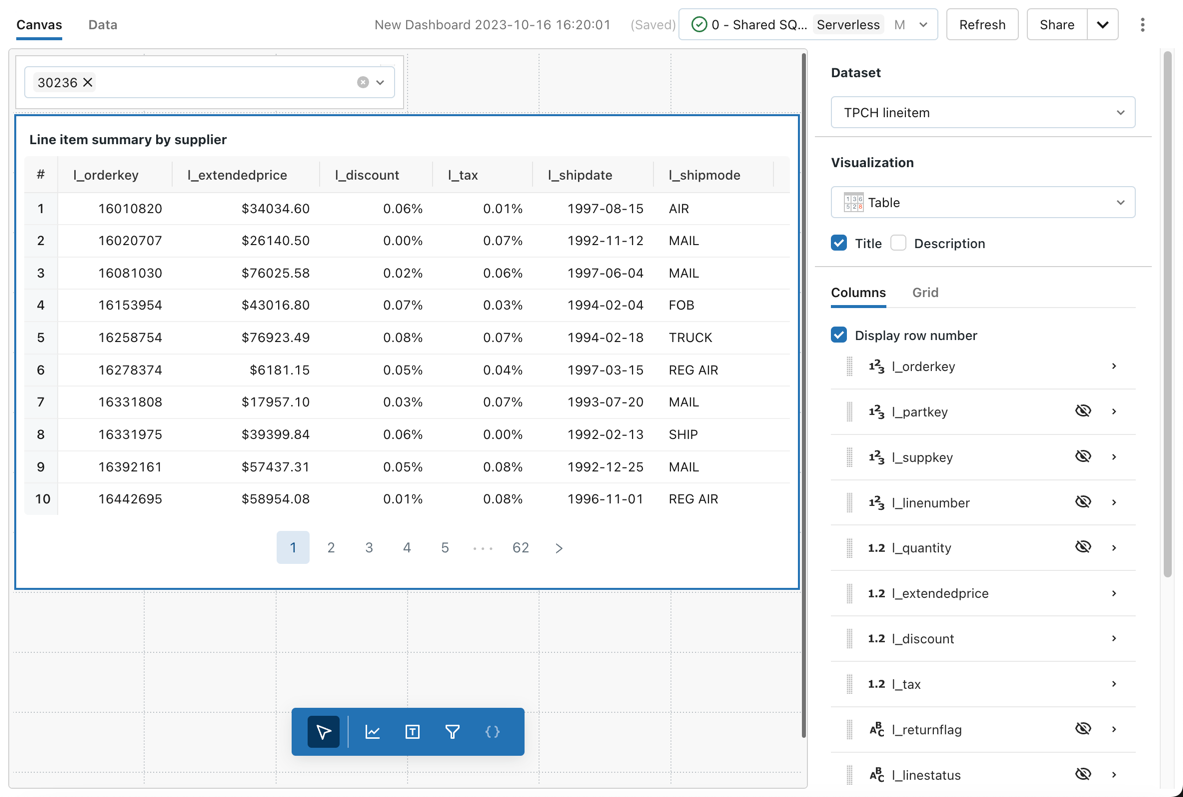
Wartości konfiguracji: w tym przykładzie wizualizacji tabeli ustawiono następujące wartości:
- Zestaw danych: samples.tpch.lineitem
- Wizualizacja: Tabela
- Tytuł:
Line item summary by supplier - Kolumny:
- Wyświetl numer wiersza: Włączony
- Pole:
l_orderkey - Pole:
l_extendedprice- Wyświetl jako:
Number - Format liczb: 0,00 PLN
- Wyświetl jako:
- Pole:
l_discount- Wyświetl jako:
Number - Format liczb: %0.00
- Wyświetl jako:
- Pole:
l_tax- Wyświetl jako:
Number - Format liczb: %0.00
- Wyświetl jako:
- Pole:
l_shipdate - Pole:
l_shipmode
- Filtr
- Pole:
TPCH lineitem.l_supplierkey
- Pole:
Opcje konfiguracji: aby uzyskać opcje konfiguracji wizualizacji tabeli, zobacz Opcje tabeli.
Zapytanie SQL: w przypadku tej wizualizacji tabeli użyto następującego zapytania SQL do wygenerowania zestawu danych o nazwie TPCH lineitem.
SELECT * FROM samples.tpch.lineitem
Wykres kaskadowy
Wykresy kaskadowe wyświetlają skumulowany efekt sekwencyjnych wartości dodatnich i ujemnych, pokazując, jak wartość początkowa jest modyfikowana przez serię wartości pośrednich dodatnich i ujemnych. Są one często używane do wizualizowania danych finansowych, takich jak sprawozdania z zysków i strat, lub pokazania, jak różne czynniki przyczyniają się do całkowitej zmiany.

Wartości konfiguracji: dla tego przykładu wykresu kaskadowego ustawiono następujące wartości:
- Zestaw danych: wygenerowany przez zapytanie
- Wizualizacja: Wodospad
- Oś X: MONTHLY(date_col)
- Oś Y: SUM(kwota)
Zapytanie SQL: w przypadku tej wizualizacji tabeli użyto następującego zapytania SQL do wygenerowania zestawu danych.
with base as (
SELECT
*
FROM
VALUES
(2535, '2025-01-01'),
(-853, '2025-02-01'),
(3229, '2025-03-01'),
(1820, '2025-04-01'),
(3195, '2025-05-01'),
(-1800, '2025-06-01'),
(-562, '2025-07-01'),
(-332, '2025-08-01'),
(1750, '2025-09-01'),
(-330, '2025-10-01'),
(3300, '2025-11-01'),
(4400, '2025-12-01') AS t (amount, date_str)
)
SELECT
amount,
cast(date_str as date) as date_col
from
base