Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Silnik wykonawczy to przełomowe usprawnienie dla wykonywania zadań w Apache Spark w usłudze Microsoft Fabric. Ten wektoryzowany aparat optymalizuje wydajność i efektywność zapytań Spark, uruchamiając je bezpośrednio w infrastrukturze lakehouse. Płynna integracja silnika oznacza, że nie wymaga modyfikacji kodu i unika uzależnienia od dostawcy. Obsługuje ona interfejsy API platformy Apache Spark i jest zgodna ze środowiskiem Uruchomieniowym 1.3 (Apache Spark 3.5) i współpracuje zarówno z formatami Parquet, jak i Delta. Niezależnie od lokalizacji danych w usłudze OneLake, czy uzyskujesz dostęp do danych za pomocą skrótów, natywne środowisko wykonawcze maksymalizuje efektywność i sprawność.
Silnik wykonywania natywnego znacznie podnosi wydajność zapytań przy jednoczesnym obniżeniu kosztów operacyjnych. Zapewnia niezwykłą szybkość, osiągając maksymalnie cztery razy szybszą wydajność w porównaniu z tradycyjnym systemem operacyjnym (oprogramowaniem open source) Spark, zweryfikowanym przez test porównawczy TPC-DS 1 TB. Silnik jest biegły w zarządzaniu szeroką gamą scenariuszy przetwarzania danych, począwszy od rutynowego wczytywania danych, zadań wsadowych i zadań ETL (ekstrakcja, transformacja, ładowanie) do złożonych analiz danych i interaktywnych zapytań. Użytkownicy korzystają z przyspieszonego czasu przetwarzania, zwiększonej przepływności i zoptymalizowanego wykorzystania zasobów.
Aparat wykonywania natywnego opiera się na dwóch kluczowych składnikach OSS: Velox, bibliotece przyspieszającej bazę danych C++ wprowadzonej przez Meta, oraz Apache Gluten (inkubowanie) — warstwie pośredniej odpowiedzialnej za przekazywanie wykonania silników SQL opartych na JVM do natywnych silników wprowadzonych przez Intel.
Kiedy należy używać natywnego silnika wykonawczego
Silnik natywnej egzekucji oferuje rozwiązanie do uruchamiania zapytań na dużą skalę w zestawach danych; optymalizuje wydajność, wykorzystując natywne możliwości bazowych źródeł danych, minimalizując narzut typowo związany z przenoszeniem i serializacją danych w tradycyjnych środowiskach Spark. Silnik obsługuje różne operatory i typy danych, w tym agregację przez funkcję skrótu, łączenie przez zagnieżdżoną pętlę transmisji (BNLJ) i dokładne formaty znacznika czasu. Jednak aby w pełni korzystać z możliwości silnika, należy wziąć pod uwagę jego optymalne przypadki użycia:
- Silnik jest skuteczny podczas pracy z danymi w formatach Parquet i Delta, które przetwarza natywnie i wydajnie.
- Zapytania obejmujące skomplikowane przekształcenia i agregacje znacznie korzystają z możliwości przetwarzania kolumnowego i wektoryzacji silnika.
- Zwiększenie wydajności jest najbardziej istotne w scenariuszach, w których zapytania nie wyzwalają mechanizmu rezerwowego, unikając nieobsługiwanych funkcji lub wyrażeń.
- Silnik jest dobrze dopasowany do zapytań, które są intensywnie obliczeniowe, a nie prostych lub związanych z operacjami wejścia-wyjścia.
Aby uzyskać informacje na temat operatorów i funkcji obsługiwanych przez aparat wykonywania natywnego, zobacz dokumentację Apache Gluten.
Włącz aparat wykonywania natywnego
Aby korzystać z pełnych możliwości natywnego aparatu wykonawczego w fazie zapoznawczej, niezbędne są określone konfiguracje. Poniższe procedury pokazują, jak aktywować tę funkcję dla notesów, definicji zadań platformy Spark i całych środowisk.
Ważne
Natywny aparat wykonywania obsługuje najnowszą wersję ogólnodostępnego środowiska uruchomieniowego, czyli Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Po wydaniu natywnego aparatu wykonawczego w Runtime 1.3, wsparcie dla poprzedniej wersji — Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4) — zostało zakończone. Zachęcamy wszystkich klientów do uaktualnienia do najnowszego środowiska uruchomieniowego 1.3. Jeśli używasz Natywnego Silnika Wykonawczego w Runtime 1.2, przyspieszenie natywne zostanie wyłączone.
Włącz na poziomie środowiska
Aby zapewnić jednolite zwiększenie wydajności, włącz natywny silnik wykonywania we wszystkich zadaniach i notesach związanych z twoim środowiskiem.
Przejdź do obszaru roboczego zawierającego Twoje środowisko i wybierz to środowisko. Jeśli nie masz utworzonego środowiska, zobacz Tworzenie, konfigurowanie i używanie środowiska w Fabric.
W obszarze Obliczenia platformy Spark wybierz pozycję Przyspieszanie.
Zaznacz pole wyboru z etykietą Włącz natywny silnik wykonywania.
Zapisz i opublikuj zmiany.
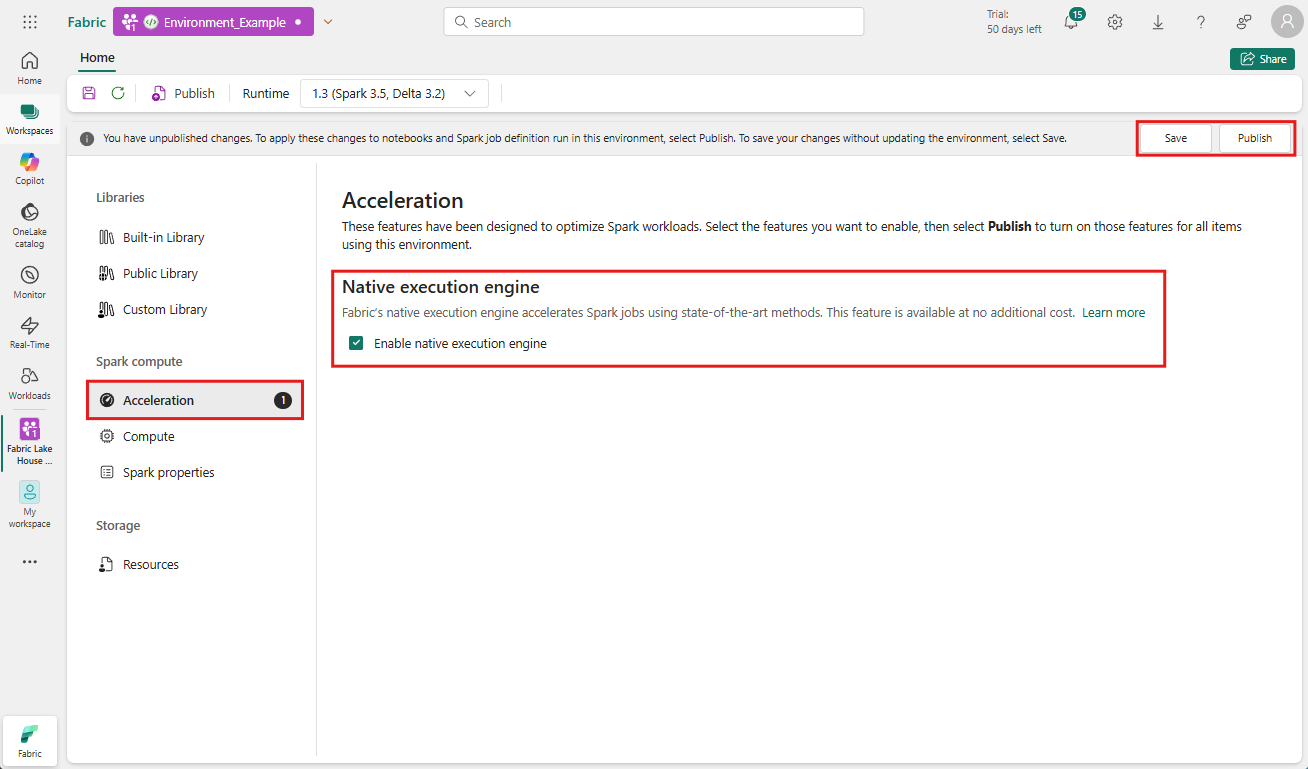

Po włączeniu na poziomie środowiska wszystkie kolejne zadania i notesy przejmują ustawienie. Dziedziczenie gwarantuje, że wszystkie nowe sesje lub zasoby utworzone w środowisku automatycznie korzystają z ulepszonych możliwości wykonywania operacji.
Ważne
Wcześniej natywny silnik wykonawczy był włączany poprzez ustawienia Spark w konfiguracji środowiska. Silnik wykonawczy natywny można teraz łatwiej włączyć za pomocą przełącznika na karcie Akceleracja ustawień środowiska. Aby kontynuować korzystanie z niego, przejdź do karty Przyspieszanie i włącz przełącznik. Można ją również włączyć za pomocą właściwości platformy Spark, jeśli jest to preferowane.
Włącz dla notesu lub definicji zadania Spark
Możesz włączyć mechanizm wykonawczy natywny dla pojedynczego notesu lub definicji zadania Spark, musisz uwzględnić niezbędne konfiguracje na początku skryptu wykonywania:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
W przypadku notebooków wstaw wymagane polecenia konfiguracji w pierwszej komórce. W przypadku definicji zadań platformy Spark uwzględnij konfiguracje w pierwszej linii definicji zadania platformy Spark. Silnik wykonywania natywnego jest zintegrowany z pulami na żywo, więc po włączeniu tej funkcji działa ona natychmiast, nie trzeba inicjować nowej sesji.
Kontrola na poziomie zapytania
Mechanizmy umożliwiające włączenie natywnego aparatu wykonawczego na poziomie najemcy, w obszarze roboczym i środowisku, są bezproblemowo zintegrowane z interfejsem użytkownika i są aktywnie opracowywane. W międzyczasie można wyłączyć wbudowany silnik wykonawczy dla określonych zapytań, szczególnie w przypadku operatorów, które nie są obecnie obsługiwane (zobacz ograniczenia). Aby wyłączyć, ustaw w konfiguracji Spark opcję spark.native.enabled na false dla określonej komórki zawierającej zapytanie.
%%sql
SET spark.native.enabled=FALSE;

Po wykonaniu zapytania, w którym natywny silnik wykonywania jest wyłączony, należy ponownie go włączyć dla kolejnych komórek, ustawiając opcję spark.native.enabled na wartość true. Ten krok jest niezbędny, ponieważ platforma Spark wykonuje sekwencyjnie komórki kodu.
%%sql
SET spark.native.enabled=TRUE;
Identyfikowanie operacji wykonywanych przez aparat
Istnieje kilka metod, aby określić, czy operator w zadaniu Apache Spark został przetworzony przy użyciu silnika natywnego wykonania.
Interfejs użytkownika platformy Spark i serwer historii platformy Spark
Uzyskaj dostęp do serwera historii platformy Spark lub interfejsu użytkownika platformy Spark, aby zlokalizować zapytanie, które należy sprawdzić. Aby uzyskać dostęp do internetowego interfejsu użytkownika platformy Spark, przejdź do definicji zadania platformy Spark i uruchom go. Na zakładce Uruchomienia wybierz ... obok nazwy aplikacji i wybierz Otwórz internetowy interfejs użytkownika platformy Spark. Możesz także uzyskać dostęp do interfejsu Spark z zakładki Monitor w obszarze roboczym. Wybierz notatnik lub potok, na stronie monitorującej znajduje się bezpośredni link do interfejsu użytkownika platformy Spark dla aktywnych zadań.

W planie zapytania wyświetlanym w interfejsie interfejsu użytkownika platformy Spark wyszukaj nazwy węzłów, które kończą się sufiksem Transformer, *NativeFileScan lub VeloxColumnarToRowExec. Sufiks oznacza, że silnik wykonawczy natywnego wykonania przeprowadził operację. Na przykład węzły mogą być oznaczone jako RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer lub BroadcastNestedLoopJoinExecTransformer.

Wyjaśnienie DataFrame
Alternatywnie możesz wykonać df.explain() polecenie w notesie, aby wyświetlić plan wykonania. W danych wyjściowych wyszukaj te same sufiksy Transformer, *NativeFileScan lub VeloxColumnarToRowExec. Ta metoda zapewnia szybki sposób potwierdzenia, czy określone operacje są obsługiwane przez natywny aparat wykonywania.

Mechanizm rezerwowy
W niektórych przypadkach natywny silnik wykonawczy może nie być w stanie wykonać zapytania z takich powodów jak nieobsługiwane funkcje. W takich przypadkach operacja wraca do tradycyjnego silnika Spark. Ten automatyczny mechanizm zapasowy gwarantuje, że przepływ pracy nie będzie przerywany.


Monitoruj zapytania i ramki danych wykonywane przez silnik
Aby lepiej zrozumieć, jak silnik natywnego wykonania jest stosowany do zapytań SQL i operacji na DataFrame'ach, a także aby szczegółowo zbadać poziomy etapów i operatorów, możesz skorzystać z Spark UI oraz Spark History Server, aby uzyskać bardziej szczegółowe informacje na temat wykonywania tego silnika.
Karta Silnik wykonywania natywnego
Możesz przejść do nowej karty "Gluten SQL / DataFrame", aby wyświetlić informacje o kompilacji Gluten i szczegóły wykonywania zapytań. Tabela Zapytania dostarcza informacji o liczbie węzłów uruchomionych na silniku natywnym i tych, które wracają do JVM dla każdego zapytania.

Wykres wykonywania zapytań
Możesz również wybrać opis zapytania dla wizualizacji planu wykonywania zapytań platformy Apache Spark. Wykres wykonywania zawiera natywne szczegóły wykonywania na różnych etapach i ich odpowiednich operacjach. Kolory tła odróżniają silniki wykonawcze: zielony reprezentuje Natywny Silnik Wykonawczy, a jasnoniebieski wskazuje, że operacja jest uruchomiona na domyślnej maszynie JVM.

Ograniczenia
Silnik wykonania natywnego (NEE) w Microsoft Fabric znacznie zwiększa wydajność zadań Apache Spark, ale obecnie ma następujące ograniczenia:
Istniejące ograniczenia
Niezgodne funkcje platformy Spark: natywny silnik wykonawczy nie obsługuje obecnie funkcji zdefiniowanych przez użytkownika (UDF),
array_containsfunkcji ani strumieniowania strukturalnego. Jeśli te funkcje lub nieobsługiwane cechy są używane bezpośrednio lub za pośrednictwem zaimportowanych bibliotek, Spark powróci do swojego silnika domyślnego.Nieobsługiwane formaty plików: zapytania dla
JSON,XMLiCSVformat nie są przyspieszane przez natywny aparat wykonywania. Te domyślne ustawienia wracają do regularnego silnika Spark JVM w celu wykonania.Tryb ANSI nie jest obsługiwany: natywny silnik wykonawczy nie obsługuje trybu ANSI SQL. Jeśli to ustawienie jest włączone, wykonywanie powraca do aparatu vanilla Spark.
Niezgodności typów danych filtru daty: Aby skorzystać z przyspieszenia natywnego silnika wykonawczego, upewnij się, że obie strony porównania dat mają zgodne typy danych. Na przykład, zamiast porównywać kolumnę
DATETIMEz literałem tekstowym, jawnie zrzutuj ją, jak pokazano:CAST(order_date AS DATE) = '2024-05-20'
Inne zagadnienia i ograniczenia
Niezgodność rzutowania dziesiętnego na zmiennoprzecinkowy: podczas rzutowania z
DECIMALdoFLOATSpark zachowuje precyzję, konwertując na ciąg i parsując go. NEE (za pośrednictwem Velox) wykonuje bezpośrednie rzutowanie z reprezentacji wewnętrznejint128_t, co może spowodować zaokrąglenie rozbieżności.Błędy konfiguracji strefy czasowej : ustawienie nierozpoznanej strefy czasowej na platformie Spark powoduje niepowodzenie zadania w obszarze NEE, podczas gdy maszyny Spark JVM obsługują ją bezpiecznie. Przykład:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEENiespójne zachowanie zaokrąglania:
round()funkcja działa inaczej w środowisku NEE ze względu na zależność odstd::roundmetody, która nie replikuje logiki zaokrąglania platformy Spark. Może to prowadzić do niespójności liczbowych w zaokrągleniu wyników.Brak sprawdzenia zduplikowanych kluczy w funkcji
map(): Gdyspark.sql.mapKeyDedupPolicyjest ustawiony na WYJĄTEK, Spark zgłasza błąd dla zduplikowanych kluczy. NEE obecnie pomija to sprawdzanie i umożliwia nieprawidłowe wykonanie zapytania.
Przykład:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Wariancja kolejności w
collect_list()z sortowaniem: Kiedy używaszDISTRIBUTE BYiSORT BY, platforma Spark zachowuje kolejność elementów wcollect_list(). NEE może zwracać wartości w innej kolejności z powodu różnic w mieszaniu, co może prowadzić do niespójności względem oczekiwań logiki wrażliwej na kolejność.Niezgodność typu pośredniego dla
collect_list()/collect_set(): platforma Spark używaBINARYjako typu pośredniego dla tych agregacji, natomiast NEE używaARRAY. Ta niezgodność może prowadzić do problemów ze zgodnością podczas planowania lub wykonywania zapytań.