Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Środowisko uruchomieniowe sieci szkieletowej oferuje bezproblemową integrację z platformą Azure. Zapewnia zaawansowane środowisko zarówno dla projektów inżynierii danych, jak i nauki o danych korzystających z platformy Apache Spark. Ten artykuł zawiera omówienie podstawowych funkcji i składników środowiska Fabric Runtime 1.3, najnowszego środowiska uruchomieniowego do obliczeń danych big data.
Środowisko uruchomieniowe Microsoft Fabric Runtime 1.3 to najnowsza wersja środowiska uruchomieniowego ogólnie dostępnego i obejmuje następujące składniki i uaktualnienia zaprojektowane w celu zwiększenia możliwości przetwarzania danych:
Apache Spark 3.5
System operacyjny: Mariner 2.0
Java: 11
Scala: 2.12.17
Python: 3.11
Delta Lake: 3.2
R: 4.4.1
Napiwek
Środowisko Uruchomieniowe Fabric 1.3 obejmuje obsługę natywnego silnika wykonawczego, co może znacznie zwiększyć wydajność bez dodatkowych kosztów. Aby włączyć aparat wykonywania natywnego we wszystkich zadaniach i notesach w danym środowisku, przejdź do ustawień środowiska, wybierz pozycję Obliczenia platformy Spark, przejdź do karty Przyspieszanie i zaznacz pole wyboru Włącz aparat wykonywania natywnego. Po zapisaniu i opublikowaniu to ustawienie jest stosowane w całym środowisku, więc wszystkie nowe zadania i notesy automatycznie dziedziczą i korzystają z ulepszonych możliwości wydajności.
Integracja środowiska Runtime 1.3
Skorzystaj z poniższych instrukcji, aby zintegrować środowisko uruchomieniowe 1.3 z obszarem roboczym i korzystać z jego nowych funkcji:
Przejdź do karty Ustawienia obszaru roboczego w obszarze roboczym Sieć szkieletowa.
Przejdź do karty inżynierowie danych/nauki i wybierz pozycję Ustawienia platformy Spark.
Wybierz kartę Środowisko.
W obszarze Wersje środowiska uruchomieniowego rozwiń listę rozwijaną.
Wybierz 1.3 (Spark 3.5, Delta 3.2) i zapisz zmiany. Ta akcja ustawia 1.3 jako domyślne środowisko uruchomieniowe dla obszaru roboczego.
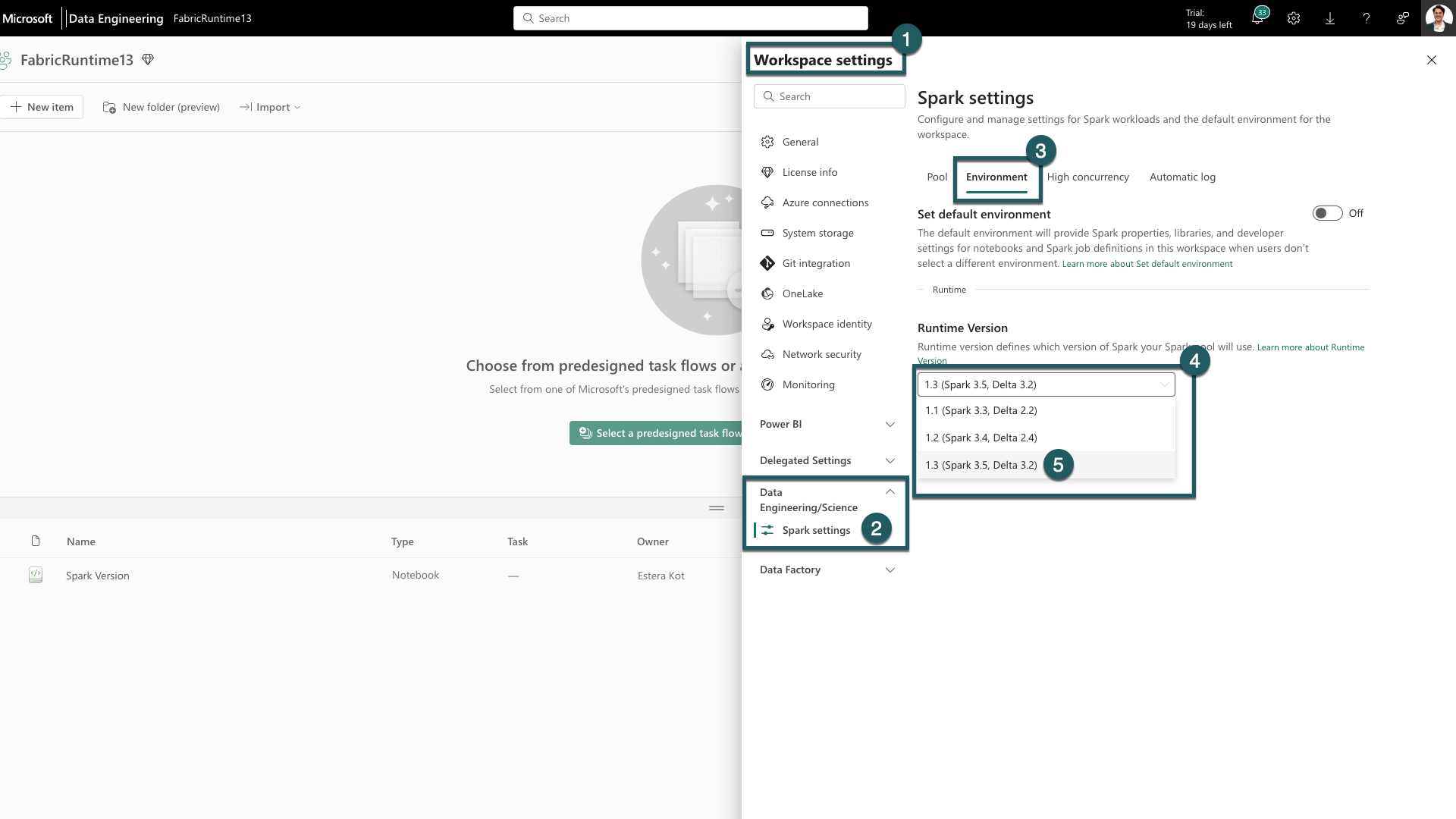

Teraz możesz rozpocząć pracę z najnowszymi ulepszeniami i funkcjami wprowadzonymi w środowisku uruchomieniowym sieci Szkieletowej 1.3 (Spark 3.5 i Delta Lake 3.2).
Dowiedz się więcej o platformie Apache Spark 3.5
Apache Spark 3.5.0 to szósta wersja z serii 3.x. Ta wersja jest produktem rozbudowanej współpracy w społeczności open source, zajmując się ponad 1300 problemami zarejestrowanymi w programie Jira.
W tej wersji istnieje uaktualnienie w zgodności ze strukturą przesyłania strumieniowego. Ponadto ta wersja rozszerza funkcjonalność programu PySpark i SQL. Dodaje ona funkcje, takie jak klauzula identyfikatora SQL, nazwane argumenty w wywołaniach funkcji SQL i włączenie funkcji SQL dla przybliżonych agregacji funkcji HyperLogLog.
Inne nowe możliwości obejmują również funkcje tabeli zdefiniowane przez użytkownika w języku Python, uproszczenie trenowania rozproszonego za pośrednictwem deepSpeed oraz nowe funkcje przesyłania strumieniowego ze strukturą, takie jak propagacja znaku wodnego i operacja dropDuplicatesWithinWatermark .
Pełną listę i szczegółowe zmiany można sprawdzić tutaj: Spark Release 3.5.0 (Wersja platformy Spark 3.5.0).
Dowiedz się więcej o platformie Delta Spark
Usługa Delta Lake 3.2 oznacza zbiorowe zobowiązanie do współpracy usługi Delta Lake w różnych formatach, łatwiejsze do pracy i bardziej wydajne. Platforma Delta Spark 3.2 jest oparta na platformie Apache Spark™ 3.5. Nazwa artefaktu maven Delta Spark została zmieniona z delta-core na delta-spark.
Pełną listę i szczegółowe zmiany można sprawdzić tutaj: https://docs.delta.io/index.html.
Składniki i biblioteki
Aby uzyskać aktualne informacje, szczegółową listę zmian i konkretne informacje o wersji dla środowisk uruchomieniowych sieci Szkieletowej, sprawdź i subskrybuj wersje i aktualizacje środowiska uruchomieniowego platformy Spark.
Uwaga / Notatka
EventHubConnector jest przestarzały w Fabric Runtime 1.3 (Spark 3.5) i zostanie usunięty z przyszłych wersji Fabric Runtime. Zachęcamy klientów do korzystania z łącznika Platformy Spark platformy Kafka, ponieważ usługa Event Hubs jest już zgodna z platformą Kafka. Więcej informacji na temat korzystania z łącznika Spark-Kafka dla Event Hubs można znaleźć tutaj: Samouczek Event Hubs Kafka Spark
Powiązana zawartość
- Przeczytaj o środowiskach uruchomieniowych platformy Apache Spark w sieci szkieletowej — omówienie, przechowywanie wersji, obsługa wielu środowisk uruchomieniowych i uaktualnianie protokołu Delta Lake
- Przewodnik migracji platformy Spark Core
- Przewodniki migracji sql, zestawów danych i ramki danych
- Przewodnik po migracji przesyłania strumieniowego ze strukturą
- Przewodnik migracji biblioteki MLlib (Machine Learning)
- Przewodnik migracji rozwiązania PySpark (Python on Spark)
- Przewodnik migracji platformy SparkR (R na platformie Spark)