Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga / Notatka
Środowisko Fabric Runtime 2.0 jest obecnie na etapie eksperymentalnej wersji zapoznawczej. Aby uzyskać więcej informacji, zobacz ograniczenia i uwagi.
Środowisko wykonawcze Fabric zapewnia bezproblemową integrację w ekosystemie Microsoft Fabric, oferując solidne środowisko dla projektów inżynierii danych i data science, obsługiwanych przez platformę Apache Spark.
W tym artykule przedstawiono środowisko uruchomieniowe Fabric Runtime 2.0 Eksperymentalne (wersja zapoznawcza), najnowsze środowisko uruchomieniowe przeznaczone do obliczeń danych big data w usłudze Microsoft Fabric. Wyróżnia ona kluczowe funkcje i składniki, które sprawiają, że ta wersja stanowi znaczący krok naprzód w zakresie skalowalnych analiz i zaawansowanych obciążeń.
Środowisko Fabric Runtime 2.0 obejmuje następujące składniki i uaktualnienia zaprojektowane w celu zwiększenia możliwości przetwarzania danych:
- Apache Spark 4.0
- System operacyjny: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Delta Lake: 4.0
Włączanie środowiska uruchomieniowego 2.0
Środowisko uruchomieniowe 2.0 można włączyć na poziomie obszaru roboczego lub na poziomie elementu środowiska. Użyj ustawień przestrzeni roboczej, aby zastosować środowisko wykonawcze Runtime 2.0 jako domyślne dla wszystkich obciążeń Spark w przestrzeni roboczej. Alternatywnie utwórz element Środowisko z Runtime 2.0 do użycia z określonymi notatnikami lub definicjami zadań platformy Spark, który zastępuje domyślne ustawienia obszaru roboczego.
Włączanie środowiska uruchomieniowego 2.0 w ustawieniach obszaru roboczego
Aby ustawić środowisko uruchomieniowe 2.0 jako wartość domyślną dla całego obszaru roboczego:
Przejdź do karty Ustawienia obszaru roboczego w obszarze roboczym Sieć szkieletowa.
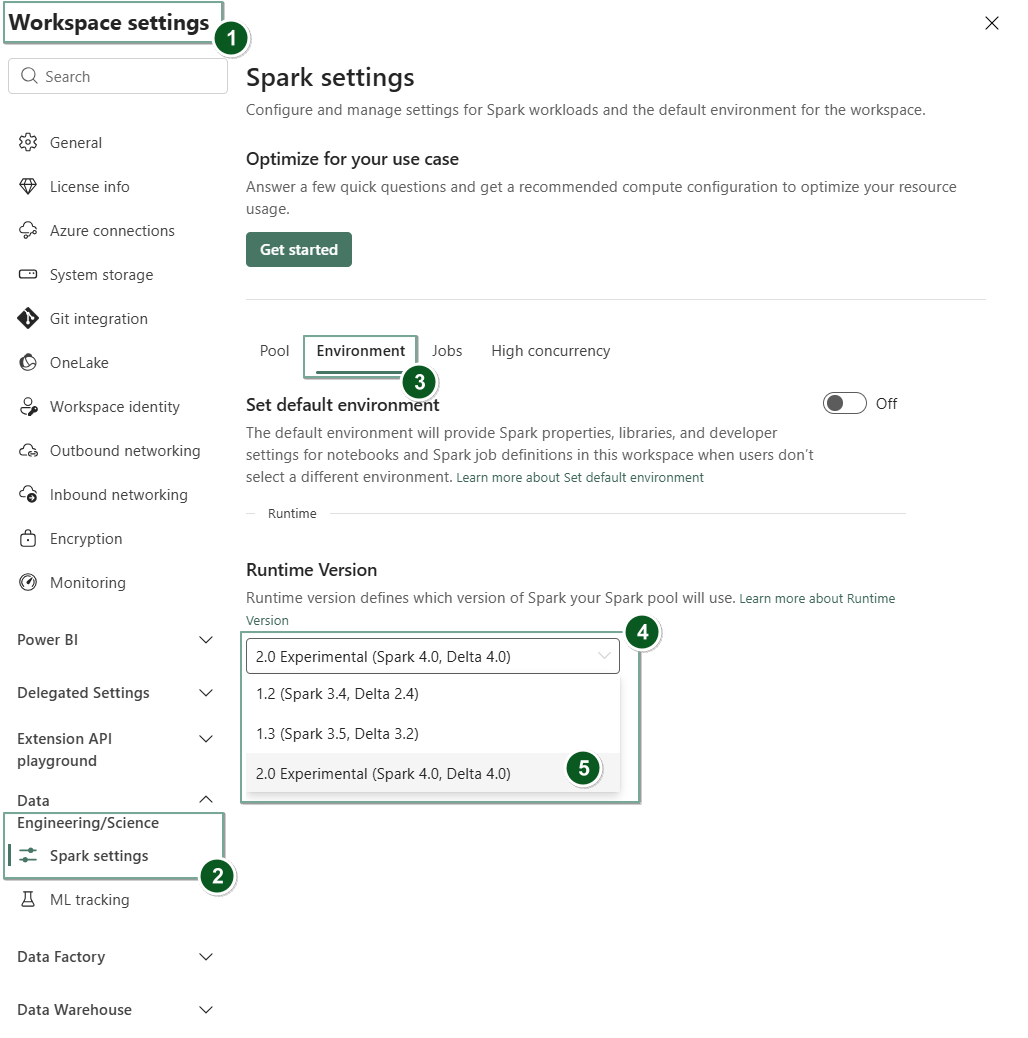
Przejdź do karty Inżynieria danych/Nauka i wybierz pozycję Ustawienia platformy Spark.
Wybierz kartę Środowisko.
Na liście rozwijanej Wersja środowiska uruchomieniowego wybierz pozycję 2.0 Eksperymentalne (Spark 4.0, Delta 4.0) i zapisz zmiany. Ta akcja ustawia środowisko uruchomieniowe 2.0 jako domyślne środowisko uruchomieniowe dla obszaru roboczego.

Włączanie środowiska uruchomieniowego 2.0 w elemencie Środowisko
Aby użyć środowiska wykonawczego 2.0 z określonymi notatnikami lub definicjami zadań platformy Spark:
Utwórz nowy element środowisko lub otwórz istniejący.
Na liście rozwijanej Środowisko uruchomieniowe wybierz pozycję 2.0 Eksperymentalne (Spark 4.0, Delta 4.0),
Savei zastosujPublishzmiany.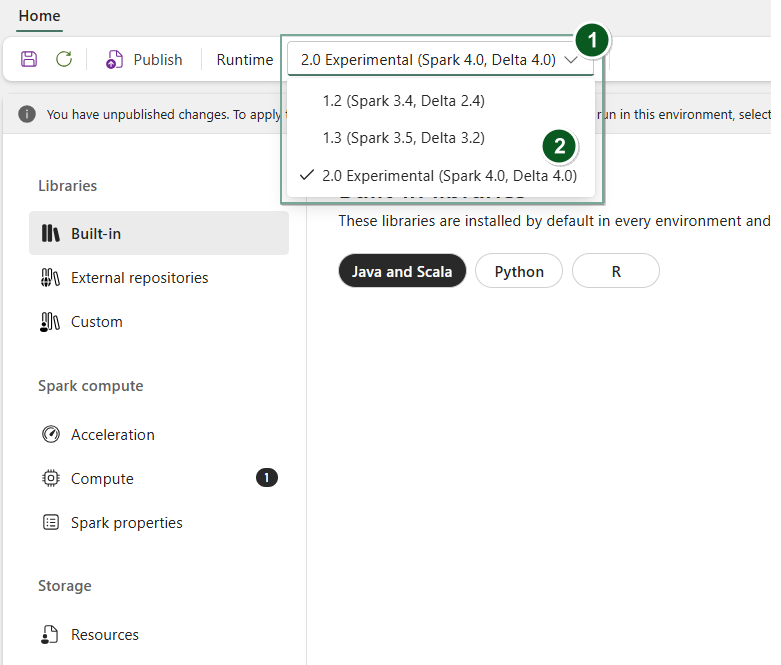
Ważne
Rozpoczęcie sesji platformy Spark 2.0 może potrwać około 2–5 minut, ponieważ pule początkowe nie są częścią wczesnej wersji eksperymentalnej.
Następnie możesz użyć tego elementu Środowisko ze swoim
NotebooklubSpark Job Definition.

Teraz możesz rozpocząć eksperymentowanie z najnowszymi ulepszeniami i funkcjami wprowadzonymi w środowisku Fabric Runtime 2.0 (Spark 4.0 i Delta Lake 4.0).
Eksperymentalna publiczna wersja zapoznawcza
Etap eksperymentalnej wersji zapoznawczej Fabric runtime 2.0 zapewnia wczesny dostęp do nowych funkcji i interfejsów API zarówno z Spark 4.0, jak i Delta Lake 4.0. Wersja zapoznawcza umożliwia od razu korzystanie z najnowszych ulepszeń opartych na platformie Spark, zapewniając bezproblemową gotowość i przejście na przyszłe zmiany, takie jak nowsze wersje języka Java, Scala i Python.
Wskazówka
Aby uzyskać aktualne informacje, szczegółową listę zmian i konkretne informacje o wersji dla środowisk uruchomieniowych sieci Szkieletowej, sprawdź i subskrybuj wersje i aktualizacje środowiska uruchomieniowego platformy Spark.
Ograniczenia i uwagi
Środowisko Fabric Runtime 2.0 jest obecnie na eksperymentalnym etapie publicznej wersji zapoznawczej, przeznaczone dla użytkowników do eksplorowania i eksperymentowania z najnowszymi funkcjami i interfejsami API platformy Spark i usługi Delta Lake w środowiskach deweloperskich lub testowych. Chociaż ta wersja oferuje dostęp do podstawowych funkcji, istnieją pewne ograniczenia:
Możesz używać sesji platformy Spark 4.0, pisać kod w notesach, planować definicje zadań platformy Spark i używać ich z narzędziami PySpark, Scala i Spark SQL. Jednak język R nie jest obsługiwany w tej wczesnej wersji.
Biblioteki można zainstalować bezpośrednio w kodzie za pomocą pip i conda. Ustawienia platformy Spark można ustawić za pomocą opcji %%configure w notesach i definicjach zadań platformy Spark (SJD).
Możesz odczytywać i zapisywać w Lakehouse za pomocą Delta Lake 4.0, ale niektóre zaawansowane funkcje, takie jak V-order, natywne zapisywanie w formacie Parquet, autokompaktowanie, optymalizacja zapisu, scalanie, scalanie z minimalnym przegrupowaniem, ewolucja schematu i podróże w czasie, nie są uwzględniane w tej wczesnej wersji.
Usługa Spark Advisor jest obecnie niedostępna. Jednak narzędzia do monitorowania, takie jak interfejs użytkownika platformy Spark i dzienniki, są obsługiwane w tej wczesnej wersji.
Funkcje, takie jak integracja nauki o danych, w tym Copilot i łączniki, w tym Kusto, SQL Analytics, Cosmos DB i MySQL Java Connector, nie są obecnie obsługiwane w tej wczesnej wersji. Biblioteki nauki o danych nie są obsługiwane w środowiskach PySpark. PySpark działa tylko z podstawową konfiguracją Conda, która obejmuje sam PySpark bez dodatkowych bibliotek.
Integracje z elementem środowiska i programem Visual Studio Code nie są obsługiwane w tej wczesnej wersji.
Nie obsługuje odczytywania i zapisywania danych na kontach usługi Azure Storage ogólnego przeznaczenia w wersji 2 (GPv2) z protokołami WASB lub ABFS.
Uwaga / Notatka
Podziel się swoją opinią na temat środowiska Fabric Runtime na platformie Pomysły. Pamiętaj, aby wspomnieć o etapie wersji i wydania, do którego się odwołujesz. Cenimy opinie społeczności i ustalamy priorytety ulepszeń na podstawie głosów, upewniając się, że spełniamy potrzeby użytkowników.
Najważniejsze aspekty
Apache Spark 4.0
Platforma Apache Spark 4.0 stanowi znaczący krok milowy jako wydanie inauguracyjne w serii 4.x, odzwierciedlając wspólny wysiłek żywej społeczności open source.
W tej wersji usługa Spark SQL jest znacząco wzbogacona o zaawansowane nowe funkcje mające na celu zwiększenie ekspresywności i wszechstronności obciążeń SQL, takich jak obsługa typów danych VARIANT, funkcje zdefiniowane przez użytkownika SQL, zmienne sesji, składnia potoku i sortowanie ciągów. PySpark charakteryzuje się ciągłym rozwojem zarówno poszerzaniu swojej funkcjonalności, jak i ogólnej poprawie doświadczenia dewelopera, przynosząc natywny interfejs API do wykresów, nowy interfejs API źródła danych dla języka Python, obsługę funkcji UDTF języka Python oraz ujednolicone profilowanie dla funkcji UDF w PySpark, a także wiele innych ulepszeń. Strukturalne przesyłanie strumieniowe ewoluuje z kluczowymi dodatkami, które zapewniają większą kontrolę i łatwość debugowania, w szczególności poprzez wprowadzenie Arbitrary State API w wersji 2 do bardziej elastycznego zarządzania stanem oraz State Data Source dla łatwiejszego debugowania.
Pełną listę i szczegółowe zmiany można sprawdzić tutaj: https://spark.apache.org/releases/spark-release-4-0-0.html.
Uwaga / Notatka
Na platformie Spark 4.0 usługa SparkR jest przestarzała i może zostać usunięta w przyszłej wersji.
Delta Lake 4.0
Delta Lake 4.0 oznacza wspólne zaangażowanie w zwiększenie interoperacyjności Delta Lake z różnymi formatami, ułatwienie pracy z nimi oraz poprawę wydajności. Delta 4.0 to przełomowa wersja z zaawansowanymi nowymi funkcjami, optymalizacjami wydajności i podstawowymi ulepszeniami dla przyszłości otwartych magazynów typu data lakehouse.
Pełną listę i szczegółowe zmiany wprowadzone w usłudze Delta Lake 3.3 i 4.0 można sprawdzić tutaj: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Ważne
Funkcje specyficzne dla usługi Delta Lake 4.0 są eksperymentalne i działają tylko w środowiskach platformy Spark, takich jak notesy i definicje zadań platformy Spark. Jeśli musisz używać tych samych tabel usługi Delta Lake w wielu obciążeniach usługi Microsoft Fabric, nie włączaj tych funkcji. Aby dowiedzieć się więcej o tym, które wersje i funkcje protokołu są zgodne w całym środowisku Microsoft Fabric, przeczytaj interoperacyjność formatu tabeli Delta Lake.
Treści powiązane
- Środowiska uruchomieniowe platformy Apache Spark w sieci szkieletowej — omówienie, przechowywanie wersji i obsługa wielu środowisk uruchomieniowych
- Przewodnik migracji platformy Spark Core
- Przewodniki migracji sql, zestawów danych i ramki danych
- Przewodnik po migracji przesyłania strumieniowego ze strukturą
- Przewodnik migracji biblioteki MLlib (Machine Learning)
- Przewodnik migracji rozwiązania PySpark (Python on Spark)
- Przewodnik migracji platformy SparkR (R na platformie Spark)