Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera najlepsze rozwiązania dotyczące tworzenia procesów przepływu pracy w czasie rzeczywistym i zarządzania nimi.
Unikaj nieskończonych pętli
Istnieje możliwość utworzenia logiki w przepływie pracy w czasie rzeczywistym, który inicjuje nieskończoną pętlę, która zużywa zasoby serwera i wpływa na wydajność. Typową sytuacją, w której może wystąpić nieskończona pętla, jest skonfigurowanie przepływu pracy w czasie rzeczywistym do uruchomienia po zaktualizowaniu kolumny, a następnie zaktualizowanie tej kolumny w logice przepływu pracy. Akcja aktualizacji wyzwala ten sam przepływ pracy w czasie rzeczywistym, który aktualizuje rekord i ponownie wyzwala przepływ pracy w czasie rzeczywistym.
Przepływy pracy, które tworzysz zawierają logikę wykrywania i kończenia niekończonych pętli. Jeśli proces przepływu pracy w czasie rzeczywistym jest uruchamiany więcej niż określoną liczbę razy w określonym rekordzie w krótkim czasie, proces kończy się niepowodzeniem z powodu następującego błędu: To zadanie przepływu pracy zostało anulowane, ponieważ przepływ pracy, który go uruchomił, zawierał nieskończoną pętlę. Popraw logikę przepływu pracy i spróbuj ponownie. Limit wynosi 16.
Korzystanie z szablonów przepływów pracy w czasie rzeczywistym
Jeśli masz podobne przepływy pracy i przewidujesz utworzenie większej liczby przepływów pracy, które są zgodne z tym samym wzorcem, zapisz przepływ pracy w czasie rzeczywistym jako szablon przepływu pracy. W ten sposób przy następnym utworzeniu podobnego przepływu pracy możesz utworzyć przepływ pracy w czasie rzeczywistym przy użyciu szablonu i uniknąć wprowadzania wszystkich warunków i akcji od podstaw.
W oknie dialogowym Utwórz proces wybierz opcję Nowy proces z istniejącego szablonu (wybierz z listy).
Używaj podrzędnych przepływów pracy
Jeśli zastosujesz tę samą logikę w różnych przepływach pracy lub w gałęziach warunkowych, zdefiniuj tę logikę jako podrzędny przepływ pracy w czasie rzeczywistym, aby nie trzeba było replikować tej logiki ręcznie w każdym przepływie pracy lub gałęzi warunkowej w czasie rzeczywistym. Dzięki temu utrzymanie przepływów pracy będzie łatwiejsze. Zamiast badać wiele przepływów pracy, które mogą stosować tę samą logikę, wystarczy zaktualizować jeden przepływ pracy.
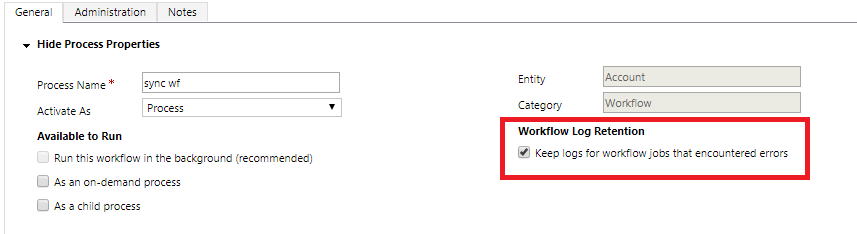
Zachowaj dzienniki dla zadań przepływu pracy w czasie rzeczywistym, które napotkały błędy
W przypadku przepływów pracy, które nie działają w tle (synchroniczne), zalecamy wybranie opcji Zachowaj dzienniki dla zadań przepływu pracy, które napotkały błędy w definicji przepływu pracy w czasie rzeczywistym. Wybranie tej opcji umożliwia zapisanie dzienników z nieudanych wykonań przepływu pracy w czasie rzeczywistym na potrzeby rozwiązywania problemów. Dzienniki z pomyślnych wykonań synchronicznych przepływów pracy zawsze będą usuwane w celu zaoszczędzenia miejsca.
Ogranicz liczbę przepływów pracy, które aktualizują tę samą tabelę
Uruchamianie więcej niż jednego przepływu pracy w czasie rzeczywistym, który aktualizuje tę samą tabelę, może powodować problemy z blokowaniem zasobów. Wyobraź sobie kilka przepływów pracy działających tam, gdzie każda aktualizacja szansy sprzedaży powoduje aktualizację dla skojarzonego klienta. Wiele wystąpień tych uruchomionych przepływów pracy próbujących zaktualizować ten sam rekord klienta w tym samym czasie może powodować blokowanie zasobów. Występują błędy przepływu pracy w czasie rzeczywistym i rejestrowany jest komunikat o błędzie, taki jak SQL: przekroczenie limitu czasu - Nie można uzyskać blokady zasobu nazwa zasobu.
Używaj notatek jako metody śledzenia zmian
Podczas edytowania przepływów pracy należy użyć karty Notatki i wpisać to, co zrobiłeś i dlaczego. Dzięki temu ktoś inny łatwiej zrozumie wprowadzone zmiany.
Dalsze kroki
Konfigurowanie procesów przepływu pracy w czasie rzeczywistym
Monitorowanie procesów przepływu pracy w czasie rzeczywistym i zarządzanie nimi