Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na poprzednim etapie tego samouczka zainstalowano narzędzie PyTorch na maszynie. Teraz użyjemy go do skonfigurowania kodu z danymi, których użyjemy do utworzenia modelu.
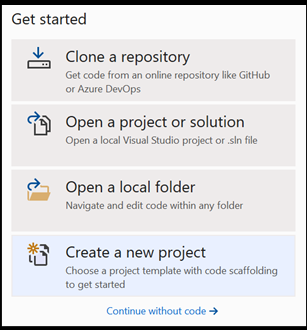
Otwórz nowy projekt w programie Visual Studio.
- Otwórz program Visual Studio i wybierz pozycję
create a new project.
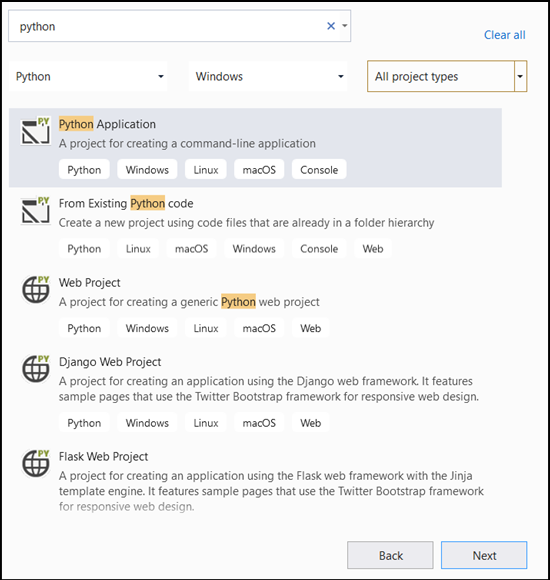
- Na pasku wyszukiwania wpisz
Pythoni wybierz jakoPython Applicationszablon projektu.
- W oknie konfiguracji:
- Nadaj projektowi nazwę. W tym miejscu nazywamy go DataClassifier.
- Wybierz lokalizację projektu.
- Jeśli używasz programu VS2019, upewnij się, że
Create directory for solutionjest zaznaczone. - Jeśli używasz programu VS2017, upewnij się, że
Place solution and project in the same directorynie jest zaznaczona.
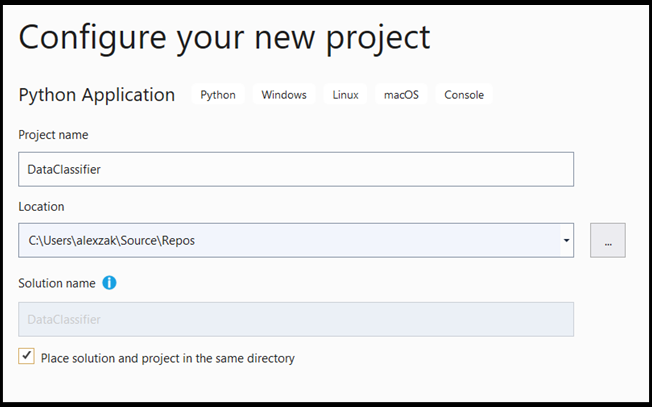
Naciśnij create , aby utworzyć projekt.
Tworzenie interpretera języka Python
Teraz musisz zdefiniować nowy interpreter języka Python. Musi to obejmować ostatnio zainstalowany pakiet PyTorch.
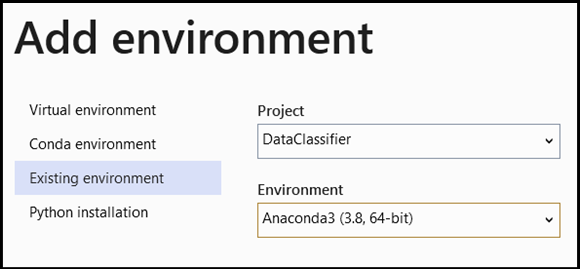
- Przejdź do zaznaczenia interpretera i wybierz pozycję
Add Environment:

-
Add EnvironmentW oknie wybierz pozycjęExisting environment, a następnie wybierz pozycjęAnaconda3 (3.6, 64-bit). Obejmuje to pakiet PyTorch.
Aby przetestować nowy interpreter języka Python i pakiet PyTorch, wprowadź następujący kod do DataClassifier.py pliku:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
Dane wyjściowe powinny być losowym tensorem 5x3 podobnym do poniższego.
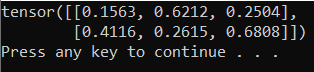
Uwaga / Notatka
Chcesz dowiedzieć się więcej? Odwiedź oficjalną stronę internetową PyTorch.
Informacje o danych
Wytrenujemy model na zestawie danych fisher's Iris flower. Ten słynny zestaw danych zawiera 50 rekordów dla każdego z trzech gatunków Iris Iris setosa, Iris virginica i Iris versicolor.
Opublikowano kilka wersji zestawu danych. Zestaw danych Iris można znaleźć w repozytorium UCI Machine Learning, zaimportować zestaw danych bezpośrednio z biblioteki Scikit-learn języka Python lub użyć dowolnej innej wersji, która została wcześniej opublikowana. Aby dowiedzieć się więcej o zestawie danych z kwiatami Iris, odwiedź stronę Wikipedii.
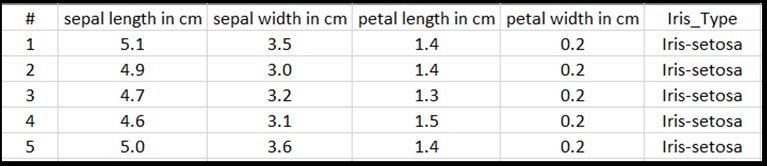
W tym samouczku nauczysz się, jak trenować model z użyciem tabelarycznych danych wejściowych, korzystając z zestawu danych Iris wyeksportowanego do pliku Excel.
Każda linia tabeli programu Excel będzie zawierać cztery cechy irysów: długość sepa w cm, szerokość sepa w cm, długość płatka w cm i szerokość płatka w cm. Te funkcje będą służyć jako dane wejściowe. Ostatnia kolumna zawiera typ Iris powiązany z tymi parametrami i będzie stanowić dane wyjściowe regresji. W sumie zestaw danych zawiera 150 danych wejściowych czterech cech, każda z nich dopasowana do odpowiedniego typu irysa.
Analiza regresji analizuje relację między zmiennymi wejściowymi a wynikiem. Na podstawie danych wejściowych model nauczy się przewidywać prawidłowy typ danych wyjściowych — jeden z trzech typów Iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Ważne
Jeśli zdecydujesz się użyć dowolnego innego zestawu danych do utworzenia własnego modelu, musisz określić zmienne wejściowe i wyjściowe modelu zgodnie ze scenariuszem.
Załaduj zestaw danych.
Pobierz zestaw danych Iris w formacie programu Excel. Możesz go znaleźć tutaj.
DataClassifier.pyW pliku w folderze Pliki Eksploratora rozwiązań dodaj następującą instrukcję importu, aby uzyskać dostęp do wszystkich potrzebnych pakietów.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Jak widać, pakiet pandas (Analiza danych języka Python) będzie używany do ładowania i manipulowania danymi i pakietem torch.nn zawierającym moduły i rozszerzalne klasy do tworzenia sieci neuronowych.
- Załaduj dane do pamięci i sprawdź liczbę klas. Oczekujemy, że zobaczymy 50 sztuk każdej odmiany irysa. Pamiętaj, aby określić lokalizację zestawu danych na komputerze.
Dodaj następujący kod do pliku DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
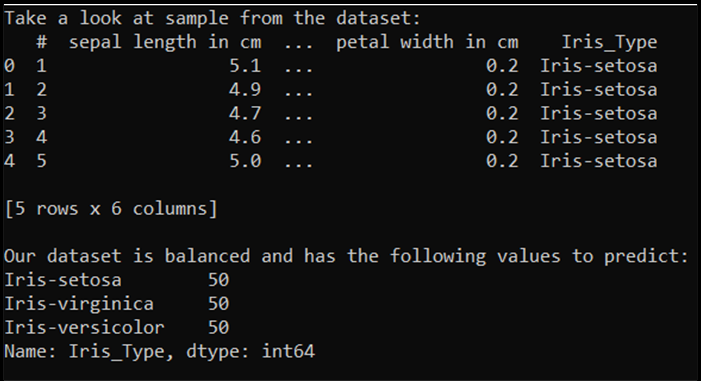
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Po uruchomieniu tego kodu oczekiwane dane wyjściowe są następujące:
Aby móc używać zestawu danych i trenować model, musimy zdefiniować dane wejściowe i wyjściowe. Dane wejściowe zawierają 150 wierszy funkcji, a dane wyjściowe to kolumna typu Iris. Używana sieć neuronowa wymaga zmiennych liczbowych, więc przekonwertujesz zmienną wyjściową na format liczbowy.
- Utwórz nową kolumnę w zestawie danych, która będzie reprezentować dane wyjściowe w formacie liczbowym i zdefiniuj dane wejściowe i wyjściowe regresji.
Dodaj następujący kod do pliku DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
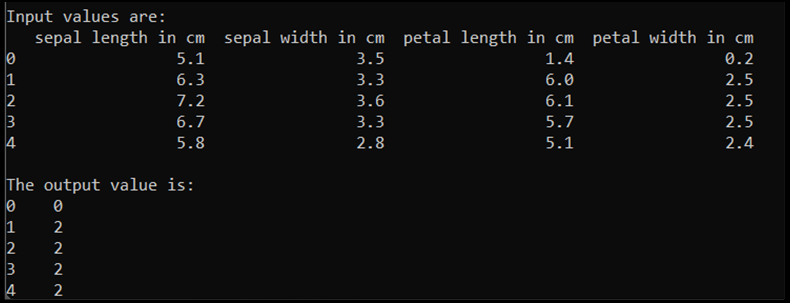
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Po uruchomieniu tego kodu oczekiwane dane wyjściowe są następujące:
Aby wytrenować model, musimy przekonwertować dane wejściowe i wyjściowe modelu na format Tensor:
- Przekonwertuj na tensor:
Dodaj następujący kod do pliku DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Jeśli uruchomimy kod, oczekiwane dane wyjściowe będą wyświetlać format danych wejściowych i wyjściowych, jak pokazano poniżej:

Istnieją 150 wartości wejściowych. Około 60% będzie częścią danych treningowych modelu. Będziesz przechowywać 20% na potrzeby weryfikacji i 30% na potrzeby testu.
W tym samouczku rozmiar partii zestawu danych trenowania jest definiowany jako 10. W zestawie treningowym znajduje się 95 elementów, co oznacza, że średnio istnieje 9 pełnych partii iterujących po zestawie treningowym (jedna epoka). Rozmiar partii zestawów weryfikacji i testów zachowasz jako 1.
- Podziel dane w celu trenowania, weryfikowania i testowania zestawów:
Dodaj następujący kod do pliku DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Dalsze kroki
Gdy dane będą gotowe do użycia, nadszedł czas, aby wytrenować nasz model PyTorch