Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W poprzednim etapie tego samouczka uzyskaliśmy zestaw danych, który będziemy używać do trenowania modelu analizy danych za pomocą rozwiązania PyTorch. Teraz nadszedł czas, aby wykorzystać te dane.
Aby wytrenować model analizy danych za pomocą narzędzia PyTorch, należy wykonać następujące kroki:
- Załaduj dane. Jeśli zrobiłeś poprzedni krok tego samouczka, już sobie z tym poradziłeś.
- Zdefiniuj sieć neuronową.
- Zdefiniuj funkcję utraty.
- Wytrenuj model na danych treningowych.
- Przetestuj sieć na danych testowych.
Definiowanie sieci neuronowej
W tym samouczku utworzysz podstawowy model sieci neuronowej z trzema warstwami liniowymi. Struktura modelu jest następująca:
Linear -> ReLU -> Linear -> ReLU -> Linear
Warstwa liniowa stosuje transformację liniową do danych przychodzących. Należy określić liczbę funkcji wejściowych i liczbę funkcji wyjściowych, które powinny odpowiadać liczbie klas.
Warstwa ReLU to funkcja aktywacji służąca do definiowania wszystkich przychodzących cech o wartości 0 lub większej. W związku z tym po zastosowaniu warstwy ReLU dowolna liczba mniejsza niż 0 jest zmieniana na zero, podczas gdy inne są zachowywane tak samo. Zastosujemy warstwę aktywacji na dwóch ukrytych warstwach, a na ostatniej warstwie liniowej nie zastosujemy aktywacji.
Parametry modelu
Parametry modelu zależą od naszego celu i danych treningowych. Rozmiar danych wejściowych zależy od liczby funkcji, które udostępniamy modelowi — cztery w naszym przypadku. Rozmiar danych wyjściowych wynosi trzy, ponieważ istnieją trzy możliwe typy irysów.
Mając trzy warstwy liniowe, sieć (4,24) -> (24,24) -> (24,3) będzie miała 744 wag (96+576+72).
Wskaźnik uczenia (lr) określa, jak bardzo dostosowujesz wagi sieci w odniesieniu do gradientu strat. Im niższa jest, tym wolniej będzie trenowanie. W tym samouczku ustawisz parametr lr na 0,01.
Jak działa sieć?
W tym miejscu tworzysz sieć przekazywania dalej. Podczas procesu trenowania sieć przetworzy dane wejściowe we wszystkich warstwach, obliczy utratę, aby zrozumieć, jak daleko przewidywana etykieta obrazu spada z prawidłowego obrazu i propaguje gradienty z powrotem do sieci, aby zaktualizować wagi warstw. Iterując poprzez ogromny zbiór danych wejściowych, sieć będzie "uczyć się", aby ustawić swoje wagi w celu uzyskania najlepszych wyników.
Funkcja forward oblicza wartość funkcji straty, a funkcja wsteczna oblicza gradienty parametrów możliwych do poznania. Podczas tworzenia sieci neuronowej za pomocą biblioteki PyTorch wystarczy zdefiniować funkcję przesyłania dalej. Funkcja wsteczna zostanie automatycznie zdefiniowana.
- Skopiuj następujący kod do
DataClassifier.pypliku w programie Visual Studio, aby zdefiniować parametry modelu i sieć neuronową.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Należy również zdefiniować urządzenie wykonawcze na podstawie dostępnego urządzenia na komputerze. PyTorch nie ma dedykowanej biblioteki dla procesora GPU, ale można ręcznie zdefiniować urządzenie wykonawcze. Urządzenie będzie kartą GPU firmy Nvidia, jeśli taka istnieje w twoim komputerze, lub procesorem CPU, jeśli jej nie ma.
- Skopiuj następujący kod, aby zdefiniować urządzenie wykonawcze:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- W ostatnim kroku zdefiniuj funkcję do zapisania modelu:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Uwaga / Notatka
Chcesz dowiedzieć się więcej o sieci neuronowej za pomocą rozwiązania PyTorch? Zapoznaj się z dokumentacją usługi PyTorch.
Definiowanie funkcji utraty
Funkcja straty oblicza wartość, która szacuje, jak daleko dane wyjściowe pochodzą z obiektu docelowego. Głównym celem jest zmniejszenie wartości funkcji straty przez zmianę wartości wektora wagi poprzez propagację wsteczną w sieciach neuronowych.
Wartość straty różni się od dokładności modelu. Funkcja straty reprezentuje, jak dobrze zachowuje się nasz model po każdej iteracji optymalizacji w zestawie treningowym. Dokładność modelu jest obliczana na danych testowych i przedstawia procent poprawnych przewidywań.
W rozwiązaniu PyTorch pakiet sieci neuronowej zawiera różne funkcje utraty, które tworzą bloki konstrukcyjne głębokich sieci neuronowych. Jeśli chcesz dowiedzieć się więcej o tych szczegółowych informacjach, zacznij od powyższej notatki. W tym miejscu użyjemy istniejących funkcji zoptymalizowanych pod kątem klasyfikacji, takich jak ta, i użyjemy funkcji utraty między entropiami klasyfikacji i optymalizatora Adama. W optymalizatorze tempo uczenia (lr) kontroluje, jak bardzo dostosowujesz wagi naszej sieci na podstawie gradientu strat. Ustawisz go jako 0,001 tutaj - im niższa jest, tym wolniej będzie trenowanie.
- Skopiuj następujący kod do pliku
DataClassifier.pyw programie Visual Studio, aby zdefiniować funkcję straty i optymalizator.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Wytrenuj model na danych treningowych.
Aby wytrenować model, musisz iterować przez dane za pomocą iteratora, przesłać dane wejściowe do sieci i zoptymalizować. Aby zweryfikować wyniki, wystarczy porównać przewidywane etykiety z rzeczywistymi etykietami w zestawie danych weryfikacji po każdej epoki trenowania.
Program wyświetli utratę trenowania, utratę walidacji i dokładność modelu dla każdej epoki lub dla każdej pełnej iteracji w zestawie treningowym. Zapisze model z najwyższą dokładnością, a po 10 epokach program wyświetli ostateczną dokładność.
- Dodaj następujący kod do
DataClassifier.pypliku
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Przetestuj model na danych testowych.
Teraz, gdy wytrenowaliśmy model, możemy przetestować model przy użyciu testowego zestawu danych.
Dodamy dwie funkcje testowe. Pierwszy test sprawdza model, który zapisałeś w poprzedniej części. Przetestuje model przy użyciu zestawu danych testowych 45 elementów i wyświetli dokładność modelu. Druga jest opcjonalną funkcją do testowania zaufania modelu do przewidywania każdego z trzech gatunków irysów, reprezentowanych przez prawdopodobieństwo pomyślnej klasyfikacji każdego gatunku.
- Dodaj następujący kod do pliku
DataClassifier.py.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Na koniec dodajmy główny kod. Spowoduje to zainicjowanie trenowania modelu, zapisanie modelu i wyświetlenie wyników na ekranie. Uruchomimy tylko dwie iteracji [num_epochs = 25] w zestawie treningowym, więc proces trenowania nie potrwa zbyt długo.
- Dodaj następujący kod do pliku
DataClassifier.py.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Przeprowadźmy test! Upewnij się, że menu rozwijane na górnym pasku narzędzi są ustawione na Debug. Zmień Solution Platform na x64, aby uruchomić projekt na komputerze lokalnym, jeśli twoje urządzenie jest 64-bitowe, lub na x86, jeśli jest 32-bitowe.
- Aby uruchomić projekt, kliknij
Start Debuggingprzycisk na pasku narzędzi lub naciśnijF5.
Zostanie wyświetlone okno konsoli i zobaczysz proces trenowania. Zgodnie z twoją definicją, wartość straty zostanie wyświetlona w każdej epoce. Oczekuje się, że wartość straty spada wraz z każdą pętlą.
Gdy szkolenie się zakończy, możesz spodziewać się wyniku podobnego do poniższego. Liczby nie będą dokładnie takie same, ponieważ szkolenie zależy od wielu czynników i nie zawsze może zwracać identyczne wyniki, ale powinny wyglądać podobnie.
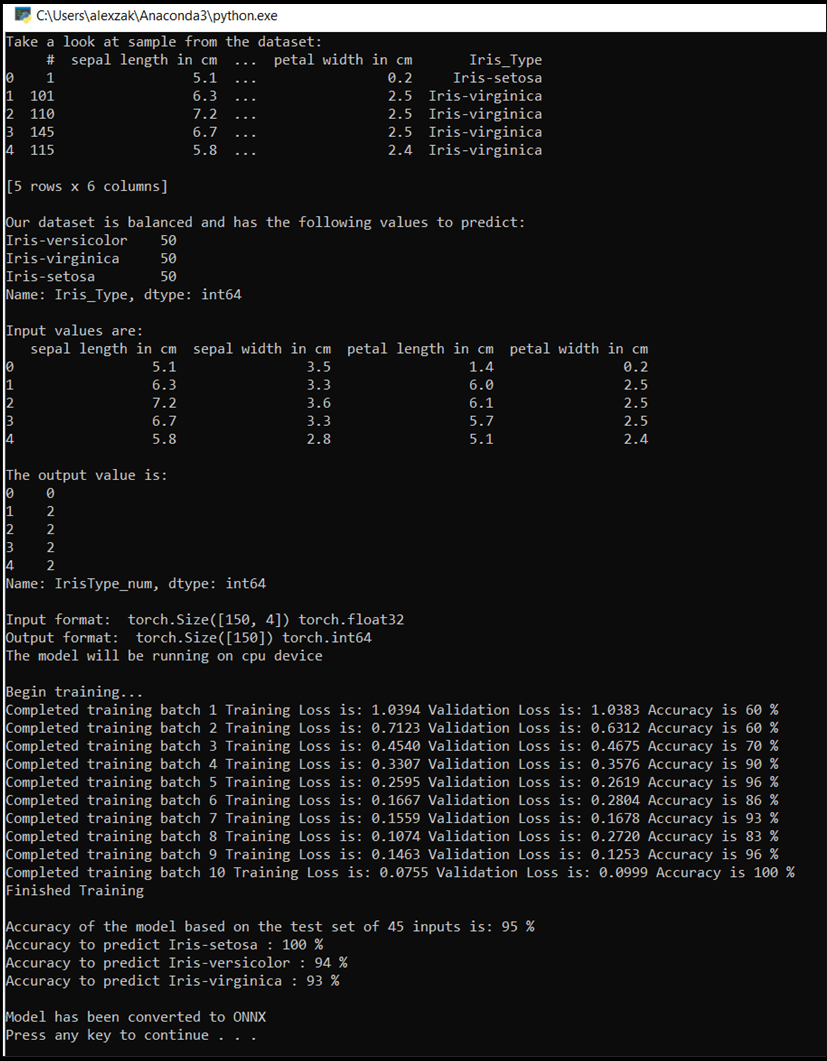
Dalsze kroki
Teraz, gdy mamy model klasyfikacji, następnym krokiem jest przekonwertowanie modelu na format ONNX.