Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
WinMLRunner to narzędzie do testowania, czy model działa pomyślnie podczas oceny przy użyciu interfejsów API uczenia maszynowego systemu Windows. Możesz również rejestrować czas oceny i użycie pamięci na GPU i/lub CPU. Modele w formacie .onnx lub PB można ocenić, gdzie zmienne wejściowe i wyjściowe są tensorami lub obrazami. Istnieją 2 sposoby używania programu WinMLRunner:
- Pobierz narzędzie wiersza polecenia języka Python.
- Użyj go na pulpicie nawigacyjnym WinML. Aby uzyskać więcej informacji, zobacz dokumentację pulpitu nawigacyjnego WinML
Uruchamianie modelu
Najpierw otwórz pobrane narzędzie języka Python. Przejdź do folderu zawierającego WinMLRunner.exei uruchom plik wykonywalny, jak pokazano poniżej. Pamiętaj, aby zastąpić lokalizację instalacji elementem zgodnym z Twoimi:
.\WinMLRunner.exe -model SqueezeNet.onnx
Możesz również uruchomić folder modeli za pomocą polecenia, takiego jak poniżej.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
Uruchamianie dobrego modelu
Poniżej przedstawiono przykład pomyślnego uruchomienia modelu. Zwróć uwagę, jak pierwszy model ładuje i generuje metadane modelu. Następnie model działa oddzielnie na procesorze CPU i procesorze GPU, wyprowadzając wyniki powiązania, powodzenie oceny i dane wyjściowe modelu.

Uruchamianie złego modelu
Poniżej przedstawiono przykład uruchamiania modelu z nieprawidłowymi parametrami. Zwróć uwagę na dane wyjściowe FAILED podczas oceny na procesorze GPU.

Wybór i optymalizacja urządzenia
Domyślnie model działa oddzielnie na procesorze CPU i procesorze GPU, ale można określić urządzenie z flagą -CPU lub -GPU. Oto przykład uruchamiania modelu 3 razy przy użyciu tylko CPU.
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
Rejestrowanie danych wydajności
Użyj flagi -perf, aby przechwycić dane wydajności. Oto przykład uruchamiania wszystkich modeli w folderze danych na procesorze CPU i procesorze GPU oddzielnie 3 razy i przechwytywaniu danych wydajności:
WinMLRunner.exe -folder c:\data iterations 3 -perf
Pomiary wydajności
Następujące pomiary wydajności będą wyjściem w wierszu polecenia oraz w pliku .csv dla każdej operacji ładowania, wiązania i oceny.
- Czas rzeczywisty (ms): jest czasem rzeczywistym, który upłynął między rozpoczęciem a zakończeniem operacji.
- Czas procesora GPU (ms): czas przekazywania operacji z procesora CPU do procesora GPU i wykonywania na procesorze GPU (uwaga: Load() nie jest wykonywany na procesorze GPU.
- Czas procesora CPU (ms): czas wykonania operacji na procesorze CPU.
- Użycie pamięci dedykowanej i współdzielonej (MB): Średnie użycie jądra i pamięci na poziomie użytkownika (w MB) podczas oceny procesora CPU lub procesora GPU.
- Pamięć zestawu roboczego (MB): Ilość pamięci DRAM wymaganej podczas oceny przez proces procesora CPU. Dedykowana pamięć (MB) — ilość pamięci używanej na pamięci VRAM dedykowanego procesora GPU.
- Pamięć współdzielona (MB): Ilość pamięci używanej na pamięci DRAM przez procesor GPU.
Przykładowe dane wyjściowe wydajności:
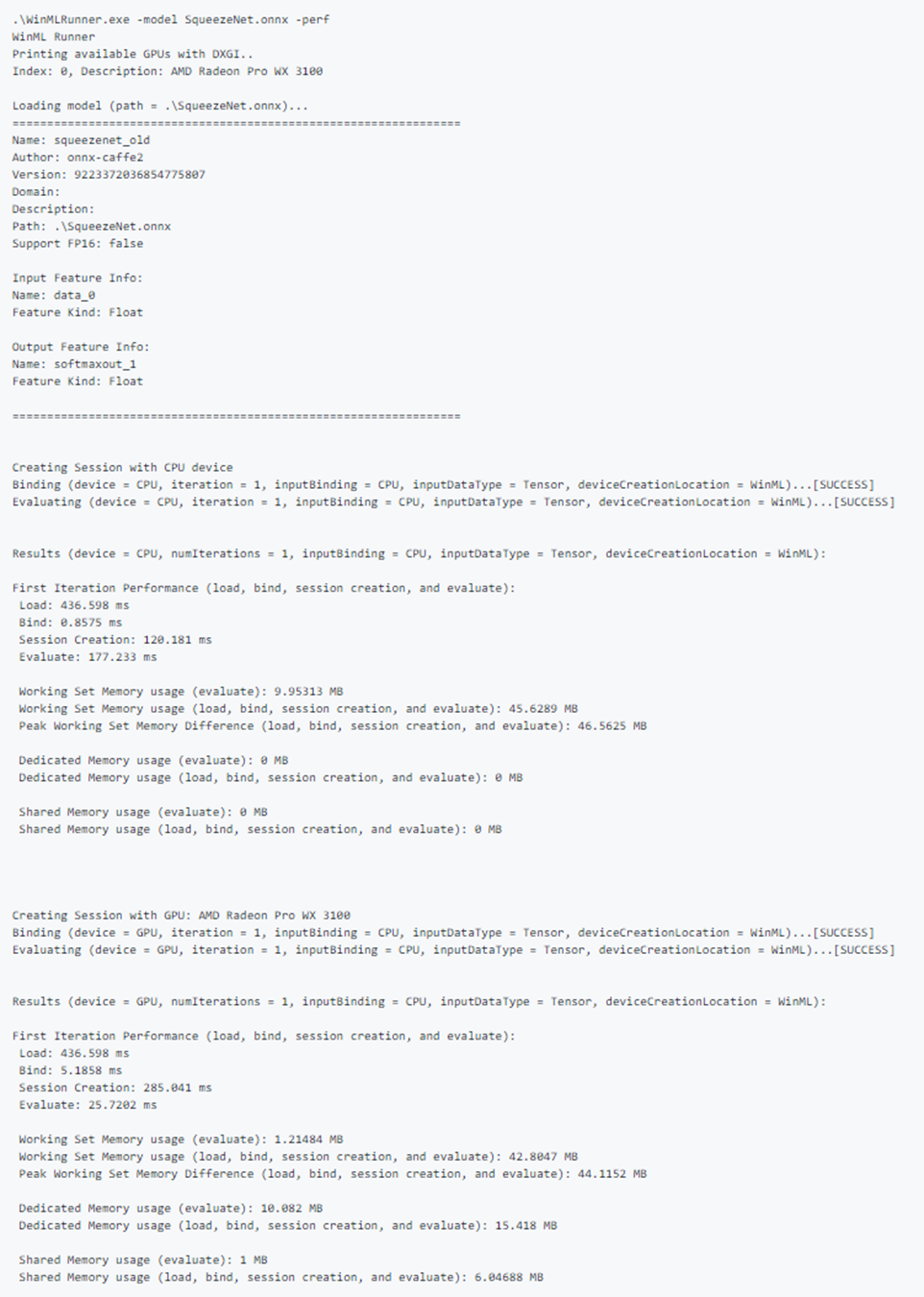
Testowanie przykładowych danych wejściowych
Uruchom model oddzielnie na CPU i GPU, a następnie powiąż wejście z CPU i GPU oddzielnie (w sumie 4 uruchomienia):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
Uruchom model na CPU z danymi wejściowymi powiązanymi z GPU, załadowanymi w formacie RGB.
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
Przechwytywanie dzienników śledzenia
Jeśli chcesz przechwycić dzienniki śledzenia za pomocą narzędzia, możesz użyć poleceń narzędzia logman w połączeniu z flagą debugowania:
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
Plik winmllog.etl zostanie wyświetlony w tym samym katalogu co WinMLRunner.exe.
Odczytywanie dzienników śledzenia
Za pomocą traceprt.exeuruchom następujące polecenie w wierszu polecenia.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
Następnie otwórz logdump.csv plik.
Alternatywnie możesz użyć Analizatora wydajności systemu Windows (z poziomu programu Visual Studio). Uruchom analizator wydajności systemu Windows i otwórz plik winmllog.etl.

Należy pamiętać, że -CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput nie wykluczają się wzajemnie (tj. można połączyć tyle, ile chcesz uruchomić model z różnymi konfiguracjami).
Dynamiczne ładowanie bibliotek DLL
Jeśli chcesz uruchomić program WinMLRunner z inną wersją winML (np. porównanie wydajności ze starszą wersją lub przetestowanie nowszej wersji), wystarczy umieścić pliki windows.ai.machinelearning.dll i directml.dll w tym samym folderze co WinMLRunner.exe. Program WinMLRunner najpierw wyszuka te biblioteki DLL i wróci do folderu C:/Windows/System32, jeśli ich nie znajdzie.
Znane problemy
- Dane wejściowe dla sekwencji lub mapy nie są jeszcze obsługiwane (model jest po prostu pomijany, aby nie blokować innych modeli w folderze);
- Nie można niezawodnie uruchomić wielu modeli z argumentem -folder z rzeczywistymi danymi. Ponieważ możemy określić tylko 1 dane wejściowe, rozmiar danych wejściowych będzie niezgodny z większością modeli. W tej chwili użycie argumentu -folder działa dobrze tylko w przypadku danych bezużytecznych;
- Generowanie wejściowych danych śmieciowych jako Gray lub YUV nie jest obecnie obsługiwane. W idealnym przypadku potok danych bezużytecznych usługi WinMLRunner powinien obsługiwać wszystkie typy danych wejściowych, które możemy dać winml.