Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Observação
Este artigo se concentra em uma arquitetura de solução das arquiteturas de solução CI/CD e ALM (Gerenciamento do Ciclo de Vida do Aplicativo) para o Dataflow Gen2 que depende do recurso de modo de parâmetros públicos e só é aplicável ao Dataflow Gen2 com suporte a CI/CD.
Os parâmetros no Fabric Dataflow Gen2 permitem definir entradas reutilizáveis que moldam como um fluxo de dados é projetado e, com o modo de parâmetros públicos , essas entradas podem ser definidas em runtime por meio de pipelines ou APIs. Isso torna um único fluxo de dados altamente flexível e versátil, pois você pode reutilizar a mesma lógica em muitos cenários simplesmente passando valores diferentes, habilitando fluxos de trabalho dinâmicos e automatizados sem precisar reescrever ou duplicar as transformações.
Este tutorial explica um exemplo que mostra como:
- Parametrizar uma fonte: usando um Lakehouse com o conjunto de dados de exemplo WideWorldImpoters como a origem
- Lógica de parametrização: usando os widgets de entrada disponíveis em toda a experiência de fluxo de dados
- Destino parametrizado: usando um Armazém como destino
- Enviar uma solicitação de execução com valores de parâmetro: passando valores de parâmetro por meio da experiência de atividade de fluxo de dados dentro de um pipeline do Fabric

Observação
Os conceitos mostrados neste artigo são universais ao Dataflow Gen2 e são aplicáveis a outras fontes e destinos além dos mostrados aqui.
O cenário

O fluxo de dados usado nesse cenário é simples, mas os princípios principais descritos se aplicam a todos os tipos de fluxos de dados. Conecta-se à tabela chamada dimension_city do conjunto de dados de exemplo Wide World Importers armazenado em um Lakehouse. Ele filtra as linhas em que a coluna SalesTerritory é igual a Sudeste e carrega o resultado em uma nova tabela chamada Cidade em um Armazém. Todos os componentes — Lakehouse, Warehouse e fluxo de dados — estão localizados no mesmo Espaço de Trabalho. Para tornar o fluxo de dados dinâmico, você parametriza a tabela de origem, o valor do filtro e a tabela de destino. Essas alterações permitem que o fluxo de dados seja executado com valores específicos em vez dos codificados.
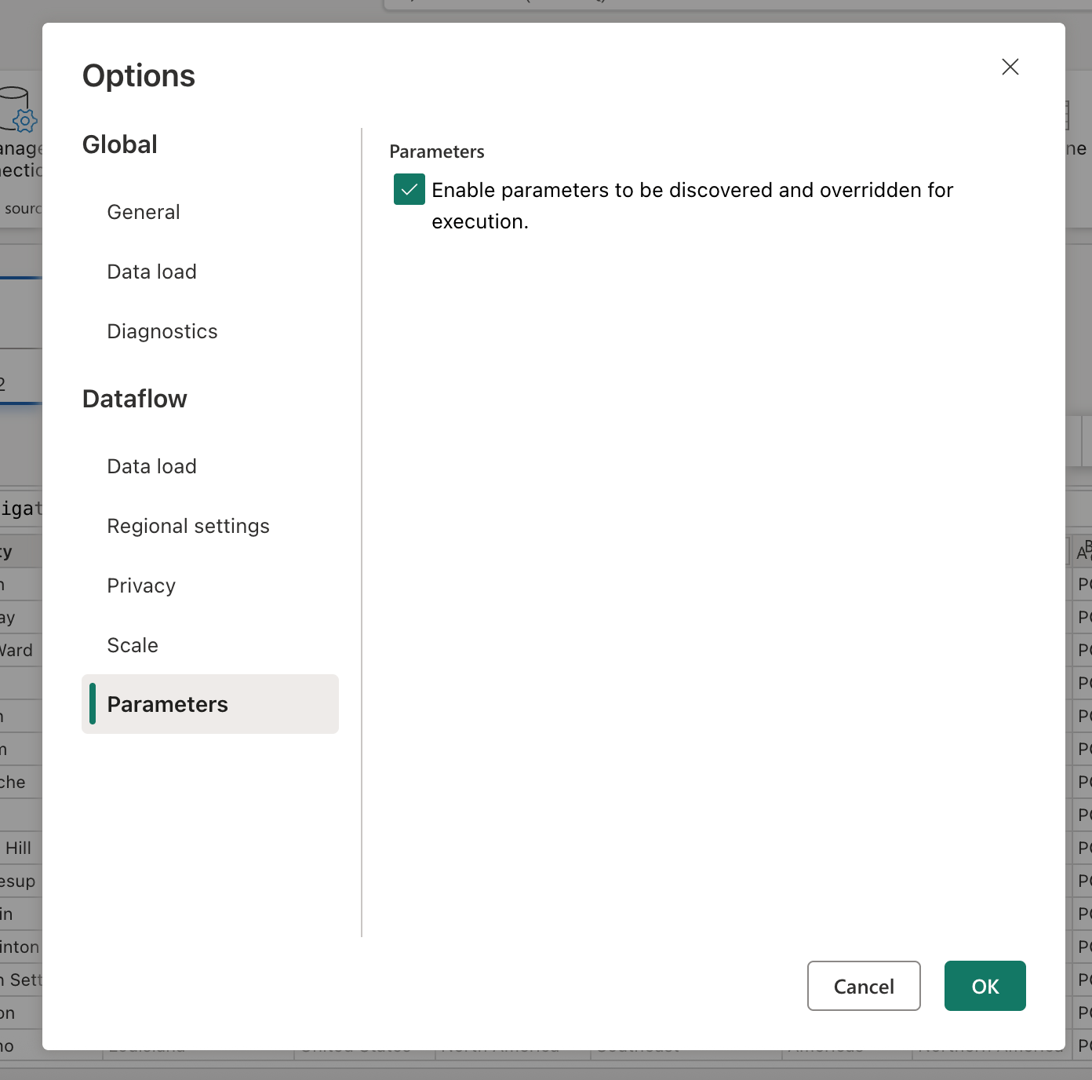
Antes de continuar, habilite o modo de parâmetros públicos acessando a guia Página Inicial , selecionando Opções e, na seção Parâmetros , marcando a caixa rotulada Habilitar parâmetros a serem descobertos e substituídos para execução e permitir que seu fluxo de dados aceite parâmetros durante a execução.
Parametrizar a origem
Ao usar qualquer um dos conectores do Fabric, como Lakehouse, Warehouse ou Fabric SQL, todos seguem a mesma estrutura de navegação e usam o mesmo formato de entrada. Nesse cenário, nenhum dos conectores requer entrada manual para estabelecer uma conexão. No entanto, cada um mostra a qual workspace e item ele se conecta por meio das etapas de navegação em sua consulta. Por exemplo, a primeira etapa de navegação inclui o workspaceId ao qual a consulta se conecta.

A meta é substituir os valores codificados na barra de fórmulas por parâmetros. Especificamente, você precisa criar um parâmetro para o WorkspaceId e outro para o LakehouseId. Para criar parâmetros, vá para a guia Página Inicial na faixa de opções, selecione Gerenciar parâmetros e escolha Novo parâmetro no menu suspenso.
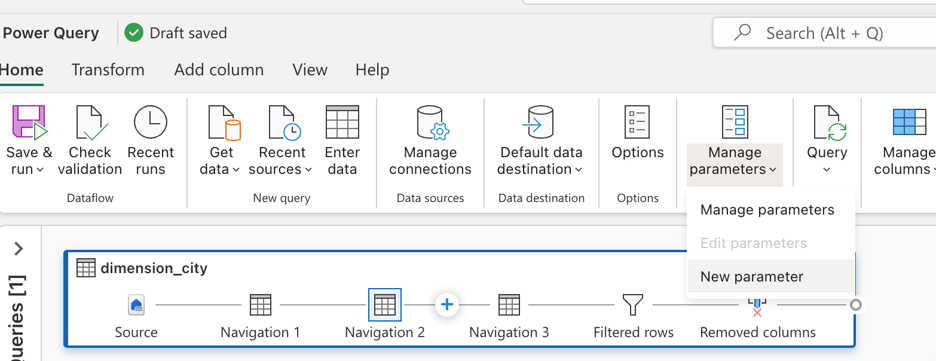
Ao criar os parâmetros, verifique se ambos estão marcados como necessários e definidos como o tipo de texto . Para seus valores atuais, use aqueles que correspondem aos valores correspondentes do seu ambiente específico.

Depois que ambos os parâmetros forem criados, você poderá atualizar o script de consulta para usá-los em vez de valores codificados. Isso envolve substituir manualmente os valores originais na barra de fórmulas por referências aos parâmetros ID do Workspace e ID do Lakehouse. O script de consulta original tem esta aparência:
let
Source = Lakehouse.Contents([]),
#"Navigation 1" = Source{[workspaceId = "8b325b2b-ad69-4103-93ae-d6880d9f87c6"]}[Data],
#"Navigation 2" = #"Navigation 1"{[lakehouseId = "2455f240-7345-4c8b-8524-c1abbf107d07"]}[Data],
#"Navigation 3" = #"Navigation 2"{[Id = "dimension_city", ItemKind = "Table"]}[Data],
#"Filtered rows" = Table.SelectRows(#"Navigation 3", each ([SalesTerritory] = "Southeast")),
#"Removed columns" = Table.RemoveColumns(#"Filtered rows", {"ValidFrom", "ValidTo", "LineageKey"})
in
#"Removed columns"
Depois de atualizar as referências nas etapas de navegação, o novo script atualizado poderá ter esta aparência:
let
Source = Lakehouse.Contents([]),
#"Navigation 1" = Source{[workspaceId = WorkspaceId]}[Data],
#"Navigation 2" = #"Navigation 1"{[lakehouseId = LakehouseId]}[Data],
#"Navigation 3" = #"Navigation 2"{[Id = "dimension_city", ItemKind = "Table"]}[Data],
#"Filtered rows" = Table.SelectRows(#"Navigation 3", each ([SalesTerritory] = "Southeast")),
#"Removed columns" = Table.RemoveColumns(#"Filtered rows", {"ValidFrom", "ValidTo", "LineageKey"})
in
#"Removed columns"
E você percebe que ele ainda avalia de maneira correta a visualização de dados no Editor de Fluxo de Dados.
Parametrizar lógica
Agora que a origem está usando parâmetros, você pode se concentrar em parametrizar a lógica de transformação do fluxo de dados. Nesse cenário, a etapa de filtro é onde a lógica é aplicada e o valor que está sendo filtrado, atualmente codificado como Sudeste, deve ser substituído por um parâmetro. Para fazer isso, crie um novo parâmetro chamado Territory, defina seu tipo de dados como texto, marque-o como não necessário e defina seu valor atual como Oriente Médio.

Considerando que a etapa de filtro foi criada usando a interface do usuário, você pode ir até a etapa linhas filtradas, selecioná-la duas vezes e obter a caixa de diálogo de configurações para a etapa de filtro. Essa caixa de diálogo permite que você selecione, por meio do widget de entrada, se desejar usar um parâmetro em vez de um valor estático:

Depois de selecionar a opção para Selecionar um parâmetro, uma lista suspensa aparecerá para mostrar todos os parâmetros disponíveis que correspondem ao tipo de dados necessário. Nesta lista, você pode selecionar o parâmetro Territory recém-criado.

Depois de selecionar OK, observe que o modo de exibição de diagrama já criou o link entre o parâmetro recém-criado e a consulta em uso. Não só isso, mas a visualização de dados agora mostra informações para o território do Oriente Médio .

Parametrizar o destino
Observação
É recomendável que você se familiarize com o conceito de destinos de dados no Dataflow Gen2 e como seu script de mashup é criado a partir do artigo sobre destinos de dados e configurações gerenciadas
O último componente a ser parametrizado nesse cenário é o destino. Embora as informações sobre o destino de dados possam ser encontradas no editor de fluxo de dados, parametrizar essa parte do fluxo de dados, você precisa usar o Git ou a API REST.

Este tutorial mostra como fazer as alterações por meio do Git. Antes de fazer alterações por meio do git, certifique-se de:
- Crie um parâmetro com o nome WarehouseId: use o ID correspondente do seu armazém como o valor atual, defina-o como obrigatório e do tipo de dados texto.
- Salvar o fluxo de dados: use o botão Salvar na guia Início da faixa de opções.
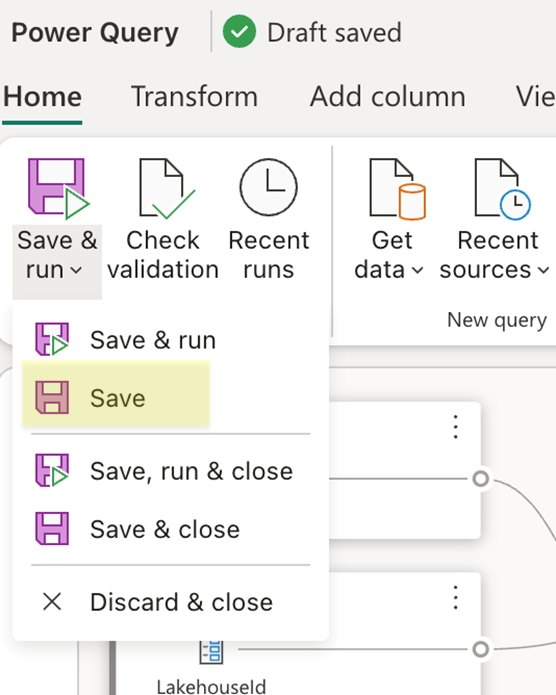
Depois que o fluxo de dados for salvo, confirme as alterações no repositório Git e vá até o repositório para ver o arquivo mashup.pq do fluxo de dados. Ao examinar o arquivo mashup.pq , procure a consulta à qual você associou o destino de dados. Nesse cenário, o nome dessa consulta é dimension_city. Você verá um atributo de registro acima desse nome de consulta:
[DataDestinations = {[Definition = [Kind = "Reference", QueryName = "dimension_city_DataDestination", IsNewTarget = true], Settings = [Kind = "Manual", AllowCreation = true, ColumnSettings = [Mappings = {[SourceColumnName = "CityKey", DestinationColumnName = "CityKey"], [SourceColumnName = "WWICityID", DestinationColumnName = "WWICityID"], [SourceColumnName = "City", DestinationColumnName = "City"], [SourceColumnName = "StateProvince", DestinationColumnName = "StateProvince"], [SourceColumnName = "Country", DestinationColumnName = "Country"], [SourceColumnName = "Continent", DestinationColumnName = "Continent"], [SourceColumnName = "SalesTerritory", DestinationColumnName = "SalesTerritory"], [SourceColumnName = "Region", DestinationColumnName = "Region"], [SourceColumnName = "Subregion", DestinationColumnName = "Subregion"], [SourceColumnName = "Location", DestinationColumnName = "Location"], [SourceColumnName = "LatestRecordedPopulation", DestinationColumnName = "LatestRecordedPopulation"]}], DynamicSchema = false, UpdateMethod = [Kind = "Replace"], TypeSettings = [Kind = "Table"]]]}]
shared dimension_city = let
Esse registro de atributo tem um campo com o nome QueryName, que contém o nome da consulta que tem toda a lógica de destino de dados associada a essa consulta. Esta consulta tem a seguinte aparência:
shared dimension_city_DataDestination = let
Pattern = Fabric.Warehouse([HierarchicalNavigation = null, CreateNavigationProperties = false]),
Navigation_1 = Pattern{[workspaceId = "8b325b2b-ad69-4103-93ae-d6880d9f87c6"]}[Data],
Navigation_2 = Navigation_1{[warehouseId = "527ba9c1-4077-433f-a491-9ef370e9230a"]}[Data],
TableNavigation = Navigation_2{[Item = "City", Schema = "dbo"]}?[Data]?
in
TableNavigation
Observe que, da mesma forma que o script da origem do Lakehouse, esse script para o destino tem um padrão semelhante em que codifica o workspaceid que precisa ser usado e também o warehouseId. Substitua esses valores fixos pelos identificadores dos parâmetros e seu script terá a seguinte aparência:
shared dimension_city_DataDestination = let
Pattern = Fabric.Warehouse([HierarchicalNavigation = null, CreateNavigationProperties = false]),
Navigation_1 = Pattern{[workspaceId = WorkspaceId]}[Data],
Navigation_2 = Navigation_1{[warehouseId = WarehouseId]}[Data],
TableNavigation = Navigation_2{[Item = "City", Schema = "dbo"]}?[Data]?
in
TableNavigation
Agora você pode confirmar essa alteração e atualizar seu fluxo de dados usando as alterações do fluxo de dados por meio do recurso de controle de origem em seu workspace. Você pode verificar se todas as alterações estão em vigor abrindo o fluxo de dados e revisando o destino de dados e as referências de parâmetro anteriores que foram adicionadas. Isso finaliza toda a parametrização do fluxo de dados e agora você pode passar para executar o fluxo de dados passando valores de parâmetro para execução.
Executar solicitação com valores de parâmetro
Você pode usar a API REST do Fabric para enviar uma solicitação de execução com um conteúdo personalizado que contém seus valores de parâmetro para essa operação de execução específica e também pode usar a API REST para descobrir parâmetros de fluxo de dados e entender o que o fluxo de dados espera para que ele possa disparar uma execução. Neste tutorial, você usará a experiência encontrada na atividade de fluxo de dados para pipelines do Fabric. Comece criando um Pipeline e adicione uma nova atividade de fluxo de dados à tela. Nas configurações da atividade, encontre o espaço de trabalho onde o fluxo de dados está localizado e, em seguida, selecione o fluxo de dados na lista suspensa.

Uma seção de parâmetros de fluxo de dados pode ser expandida para mostrar todos os parâmetros disponíveis no fluxo de dados e seus valores padrão. Você pode substituir todos os valores aqui e os valores passados serão usados para definir quais fontes, lógica e destino devem ser usados para avaliar a execução do fluxo de dados. Você também pode experimentar novos cenários criando um novo "Warehouse" e alterando o WarehouseId para a avaliação, ou utilizando esse padrão em um pipeline de implantação onde o WorkspaceId e outros parâmetros precisam ser passados para apontar para os itens corretos no ambiente correspondente.