Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
O Azure Data Factory (ADF) é um serviço de integração de dados baseado na nuvem que permite executar uma combinação de atividades nos dados. Use o ADF para criar fluxos de trabalho orientados por dados para orquestrar e automatizar a movimentação e a transformação de dados. A atividade do Comando do Azure Data Explorer no Azure Data Factory permite executar comandos de gerenciamento do Azure Data Explorer em um fluxo de trabalho do ADF. Este artigo ensina como criar um pipeline com uma atividade de pesquisa e uma atividade ForEach contendo uma atividade de comando do Azure Data Explorer.
Pré-requisitos
- Uma assinatura do Azure. Crie uma conta do Azure gratuita.
- Um cluster e um banco de dados do Azure Data Explorer. Crie um cluster e um banco de dados.
- Uma fonte de dados.
- Uma fábrica de dados. Crie uma fábrica de dados.
Criar um novo fluxo de trabalho
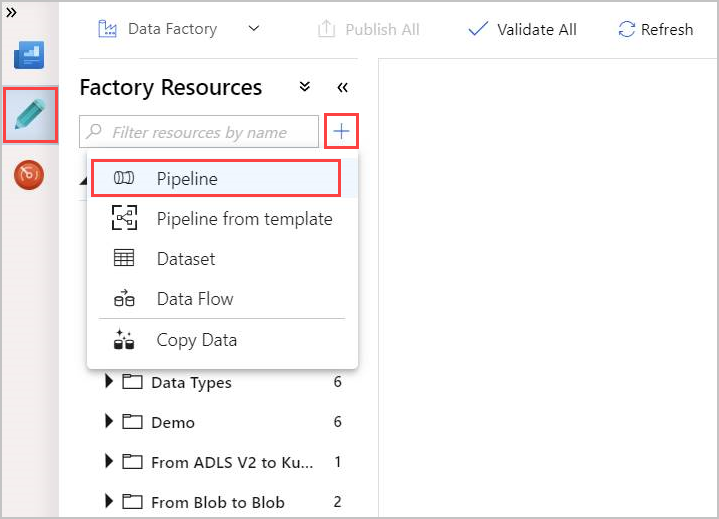
Selecione a ferramenta Lápis de autor .
Crie um novo pipeline ao selecionar + e, em seguida, escolher Pipeline na lista suspensa.
Criar uma atividade de Pesquisa
Uma atividade de pesquisa pode recuperar um conjunto de dados de qualquer fonte de dados com suporte do Azure Data Factory. A saída da atividade de pesquisa pode ser usada num ForEach ou noutra atividade.
No painel Atividades , em Geral, selecione a atividade Pesquisa . Arraste e solte-o na tela principal à direita.
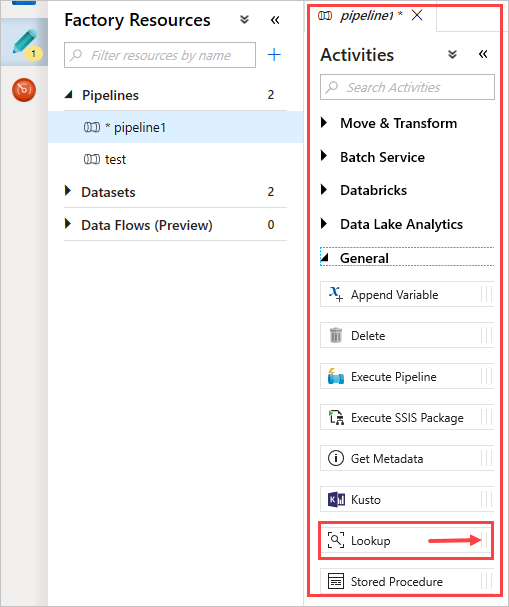
A tela agora contém a atividade Pesquisa que você criou. Use as guias abaixo da tela para alterar quaisquer parâmetros relevantes. Em Geral, renomeie a atividade.

Sugestão
Clique na área de desenho vazia para visualizar as propriedades do pipeline. Utilize o separador Geral para renomear o pipeline. O nosso pipeline é denominado pipeline-4-docs.
Criar um conjunto de dados do Azure Data Explorer na atividade de pesquisa
Em Configurações, selecione seu conjunto de dados de Origem do Azure Data Explorer pré-criado ou selecione + Novo para criar um novo conjunto de dados.

Selecione o conjunto de dados do Azure Data Explorer (Kusto) na janela Novo Conjunto de Dados . Selecione Continuar para adicionar o novo conjunto de dados.

Os novos parâmetros do conjunto de dados do Azure Data Explorer são visíveis em Configurações. Para atualizar os parâmetros, selecione Editar.

A nova guia AzureDataExplorerTable é aberta na tela principal.
- Selecione Geral e edite o nome do conjunto de dados.
- Selecione Conexão para editar as propriedades do conjunto de dados.
- Selecione o Serviço vinculado na lista suspensa ou selecione + Novo para criar um novo serviço vinculado.

Ao criar um novo serviço vinculado, a página Novo Serviço Vinculado (Azure Data Explorer) abre:

- Selecione Nome para o serviço vinculado do Azure Data Explorer. Adicione Descrição , se necessário.
- Em Connect via integration runtime, altere as configurações atuais, se necessário.
- Em Método de seleção de conta , selecione seu cluster usando um dos dois métodos:
- Selecione o botão de opção Da assinatura do Azure e selecione a sua conta Azure subscription. Em seguida, selecione o Cluster. Observe que a lista suspensa listará apenas os clusters que pertencem ao usuário.
- Em vez disso, selecione o botão de opção Inserir manualmente e introduza o seu ponto de extremidade (URL do cluster).
- Especifique o locatário.
- Insira ID do principal de serviço. Esse valor pode ser encontrado no portal do Azure em Registros de Aplicativos>Visão Geral>ID do Aplicativo (cliente). O principal deve ter as permissões adequadas, de acordo com o nível de permissão exigido pelo comando que está sendo usado.
- Selecione o botão Chave principal de serviço e insira Chave principal de serviço.
- Selecione o seu banco de dados no menu suspenso. Como alternativa, marque a caixa de seleção Editar e digite o nome do banco de dados.
- Selecione Testar conexão para testar a conexão de serviço vinculado que você criou. Se você puder se conectar à sua configuração, uma marca de seleção verde Conexão bem-sucedida aparecerá.
- Selecione Concluir para concluir a criação do serviço vinculado.
Depois de configurar um serviço vinculado, Em AzureDataExplorerTable>Connection, adicione o nome da tabela . Selecione Visualizar dados para garantir que os dados sejam apresentados corretamente.
Seu conjunto de dados agora está pronto e você pode continuar editando seu pipeline.
Adicionar uma consulta à sua atividade de pesquisa
EmConfigurações>, adicione uma consulta na caixa de texto Consulta, por exemplo:
ClusterQueries | where Database !in ("KustoMonitoringPersistentDatabase", "$systemdb") | summarize count() by DatabaseAltere as propriedades Tempo limite de consulta ou Sem truncamento e Somente primeira linha, conforme necessário. Nesse fluxo, mantemos o tempo limite de consulta padrão e desmarcamos as caixas de seleção.

Criar uma atividade For-Each
A atividade For-Each é usada para iterar sobre uma coleção e executar atividades específicas num ciclo.
Agora adicionas uma atividade For-Each ao pipeline. Essa atividade processará os dados retornados da atividade de pesquisa.
No painel Atividades , em Iteração & Condicionais, selecione a atividade ForEach e arraste-a e solte-a na tela.
Desenhe uma linha entre a saída da atividade Pesquisa e a entrada da atividade ForEach na tela para conectá-los.
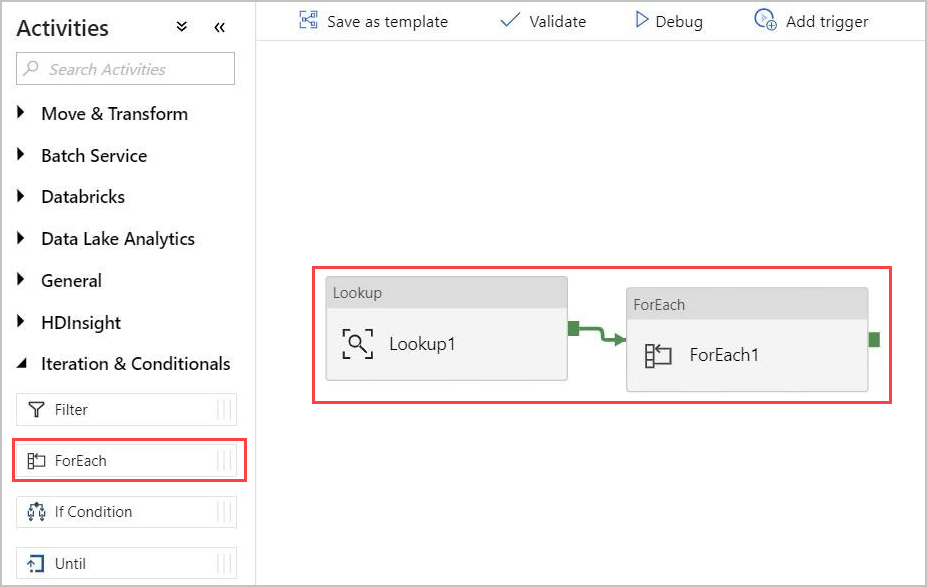
Selecione a atividade ForEach na tela. Na guia Configurações abaixo:
Marque a caixa de seleção Sequencial para obter um processamento sequencial dos resultados da Pesquisa ou deixe-a desmarcada para criar processamento paralelo.
Definir contagem de lotes.
Em Itens, forneça a seguinte referência ao valor de saída: @activity('Lookup1').output.value

Criar uma atividade de Comando do Azure Data Explorer dentro da atividade ForEach
Clique duas vezes na atividade ForEach na tela para abri-la em uma nova tela para especificar as atividades em ForEach.
No painel Atividades, em Azure Data Explorer, selecione a atividade Azure Data Explorer Command e arraste-a e solte-a no ecrã.
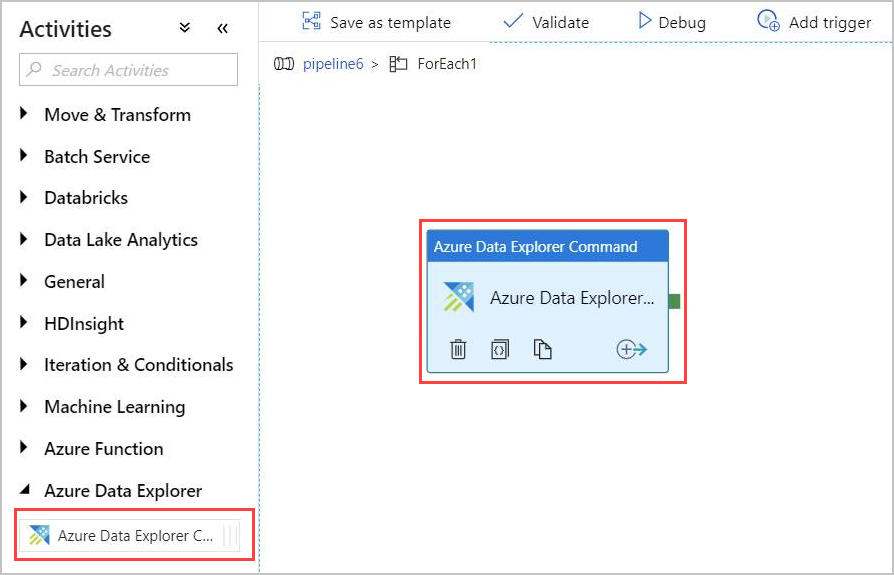
Na guia Conexão , selecione o mesmo Serviço Vinculado criado anteriormente.

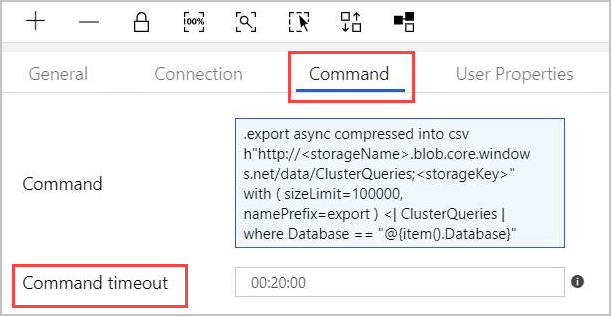
Na guia Comando , forneça o seguinte comando:
.export async compressed into csv h"http://<storageName>.blob.core.windows.net/data/ClusterQueries;<storageKey>" with ( sizeLimit=100000, namePrefix=export ) <| ClusterQueries | where Database == "@{item().Database}"O Comando instrui o Azure Data Explorer a exportar os resultados de uma determinada consulta para um armazenamento de blob, em um formato compactado. Ele é executado de forma assíncrona (usando o modificador assíncrono). A consulta aborda a coluna do banco de dados de cada linha no resultado da atividade de pesquisa. O tempo limite do comando pode ser deixado inalterado.
Observação
A atividade de comando tem os seguintes limites:
- Limite de tamanho: 1 MB de tamanho de resposta
- Limite de tempo: 20 minutos (padrão), 1 hora (máximo).
- Se necessário, você pode acrescentar uma consulta ao resultado usando AdminThenQuery, para reduzir o tamanho/tempo resultante.
Agora o gasoduto está pronto. Você pode voltar à visualização principal do pipeline clicando no nome do pipeline.

Selecione Depurar antes de publicar o pipeline. O progresso do pipeline pode ser monitorado na guia Saída .
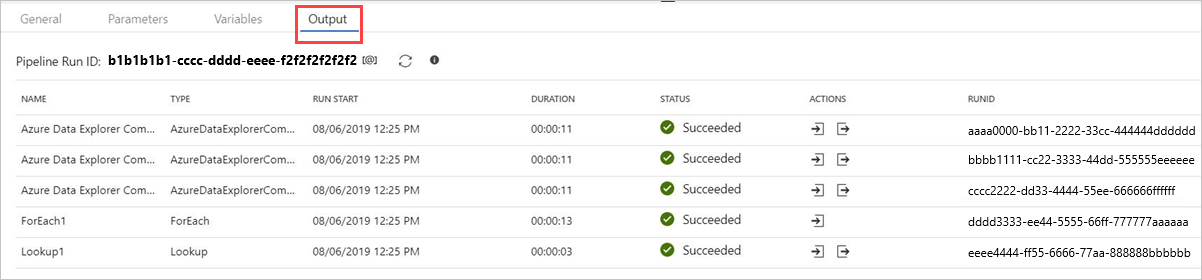
Você pode Publicar tudo e depois Adicionar um trigger para executar o pipeline.
Saídas de comando de gerenciamento
A estrutura da saída da atividade de comando é detalhada abaixo. Esta saída pode ser utilizada pela seguinte atividade no fluxo de trabalho.
Valor retornado de um comando de gerenciamento não assíncrono
Em um comando de gerenciamento não assíncrono, a estrutura do valor retornado é semelhante à estrutura do resultado da atividade de pesquisa. O count campo indica o número de registros retornados. Um campo value de matriz fixa contém uma lista de registros.
{
"count": "2",
"value": [
{
"ExtentId": "1b9977fe-e6cf-4cda-84f3-4a7c61f28ecd",
"ExtentSize": 1214.0,
"CompressedSize": 520.0
},
{
"ExtentId": "b897f5a3-62b0-441d-95ca-bf7a88952974",
"ExtentSize": 1114.0,
"CompressedSize": 504.0
}
]
}
Valor retornado de um comando de gerenciamento assíncrono
Em um comando de gerenciamento assíncrono, a atividade sonda a tabela de operações nos bastidores, até que a operação assíncrona seja concluída ou atinja o tempo limite. Portanto, o valor retornado conterá o resultado de .show operations OperationId para essa determinada propriedade OperationId . Verifique os valores das propriedades State e Status para verificar a conclusão bem-sucedida da operação.
{
"count": "1",
"value": [
{
"OperationId": "910deeae-dd79-44a4-a3a2-087a90d4bb42",
"Operation": "TableSetOrAppend",
"NodeId": "",
"StartedOn": "2019-06-23T10:12:44.0371419Z",
"LastUpdatedOn": "2019-06-23T10:12:46.7871468Z",
"Duration": "00:00:02.7500049",
"State": "Completed",
"Status": "",
"RootActivityId": "f7c5aaaf-197b-4593-8ba0-e864c94c3c6f",
"ShouldRetry": false,
"Database": "MyDatabase",
"Principal": "<some principal id>",
"User": "<some User id>"
}
]
}