Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Importante
Esse conector pode ser usado no Real-Time Intelligence no Microsoft Fabric. Use as instruções neste artigo com as seguintes exceções:
- Se necessário, crie bancos de dados usando as instruções em Criar um banco de dados KQL.
- Se necessário, crie tabelas usando as instruções em Criar uma tabela vazia.
- Obtenha URIs de consulta ou ingestão usando as instruções em Copiar URI.
- Execute consultas em um conjunto de consultas KQL.
O Azure Data Explorer é um serviço de análise de dados rápido e totalmente gerenciado. Ele oferece análise em tempo real sobre grandes volumes de dados que são transmitidos de muitas fontes, como aplicativos, sites e dispositivos IoT. Com o Azure Data Explorer, pode explorar iterativamente os dados e identificar padrões e anomalias para melhorar os produtos, melhorar as experiências dos clientes, monitorizar dispositivos e impulsionar as operações. Ajuda-o a explorar novas perguntas e a obter respostas em minutos.
O Azure Data Factory é um serviço de integração de dados totalmente gerenciado e baseado em nuvem. Você pode usá-lo para preencher seu banco de dados do Azure Data Explorer com dados do seu sistema existente. Ele pode ajudá-lo a economizar tempo ao criar soluções de análise.
Quando você carrega dados no Azure Data Explorer, o Data Factory oferece os seguintes benefícios:
- Configuração fácil: obtenha um assistente intuitivo de cinco etapas sem a necessidade de scripts.
- Suporte avançado a armazenamento de dados: obtenha suporte interno para um conjunto avançado de armazenamentos de dados locais e baseados em nuvem. Para obter uma lista detalhada, consulte a tabela de Armazenamentos de dados suportados.
- Seguro e compatível: os dados são transferidos por HTTPS ou Azure ExpressRoute. A presença do serviço global garante que seus dados nunca saiam do limite geográfico.
- Alto desempenho: a velocidade de carregamento de dados é de até 1 gigabyte por segundo (GBps) no Azure Data Explorer. Para obter mais informações, consulte Copiar desempenho da atividade.
Neste artigo, você usa a ferramenta Data Factory Copy Data para carregar dados do Amazon Simple Storage Service (S3) no Azure Data Explorer. Você pode seguir um processo semelhante para copiar dados de outros armazenamentos de dados, como:
- Armazenamento de Blobs em Azure
- Banco de Dados SQL do Azure
- Azure SQL Data Warehouse
- Google BigQuery
- Oráculo
- Sistema de Ficheiros
Pré-requisitos
- Uma assinatura do Azure. Crie uma conta do Azure gratuita.
- Um cluster e um banco de dados do Azure Data Explorer. Crie um cluster e um banco de dados.
- Uma fonte de dados.
Criar uma fábrica de dados
Inicie sessão no portal Azure.
No painel esquerdo, selecione Criar um recurso>Analytics>Data Factory.

No painel Novo fábrica de dados, forneça valores para os campos na tabela abaixo:

Configurações Valor a introduzir Nome Na caixa, insira um nome globalmente exclusivo para a sua fábrica de dados. Se receber um erro, o nome da fábrica de dados "LoadADXDemo" não está disponível, insira um nome diferente para a fábrica de dados. Para obter regras sobre como nomear artefatos do Data Factory, consulte Regras de nomenclatura do Data Factory. Subscrição Na lista suspensa, selecione a assinatura do Azure na qual deseja criar a fábrica de dados. Grupo de Recursos Selecione Criar novo e insira o nome de um novo grupo de recursos. Se você já tiver um grupo de recursos, selecione Usar existente. Versão Na lista suspensa, selecione V2. Localização Na lista suspensa, selecione o local da fábrica de dados. Somente os locais suportados são exibidos na lista. Os armazenamentos de dados usados pelo data factory podem existir em outros locais ou regiões. Selecione Criar.
Para monitorar o processo de criação, selecione Notificações na barra de ferramentas. Depois de criar o data factory, selecione-o.
O painel Data Factory é aberto.

Para abrir o aplicativo em um painel separado, selecione o bloco Autor & Monitor .
Carregar dados no Azure Data Explorer
Você pode carregar dados de muitos tipos de armazenamentos de dados no Azure Data Explorer. Este artigo descreve como carregar dados do Amazon S3.
Pode carregar os seus dados de uma das seguintes formas:
- Na interface do usuário do Azure Data Factory, no painel esquerdo, selecione o ícone Autor . Isso é mostrado na seção "Criar uma fábrica de dados" de Criar uma fábrica de dados usando a interface do usuário do Azure Data Factory.
- Na ferramenta Copiar Dados do Azure Data Factory, conforme mostrado em Usar a ferramenta Copiar Dados para copiar dados.
Copiar dados do Amazon S3 (origem)
No painel Vamos começar , abra a ferramenta Copiar Dados selecionando Copiar Dados.
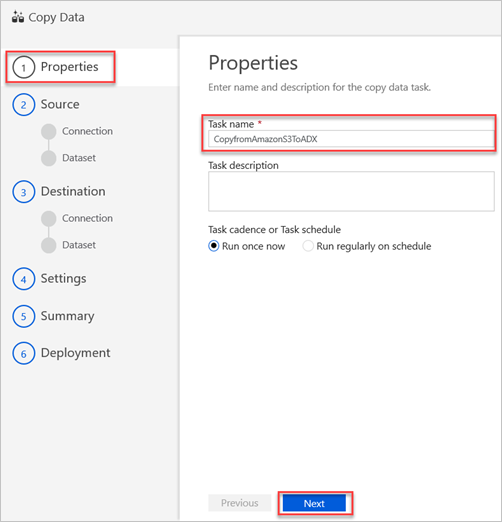
No painel Propriedades , na caixa Nome da tarefa , introduza um nome e, em seguida, selecione Seguinte.
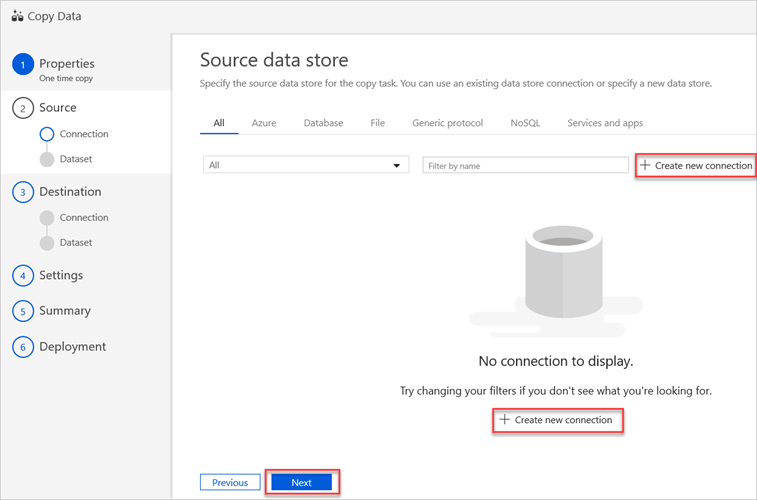
No painel Armazenamento de dados de origem , selecione Criar nova conexão.
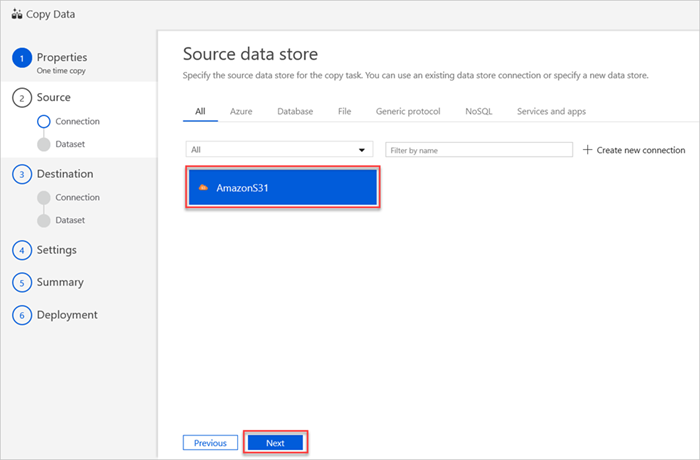
Selecione Amazon S3 e, em seguida, selecione Continuar.

No painel Novo serviço vinculado (Amazon S3), faça o seguinte:

a) Na caixa Nome , digite o nome do novo serviço vinculado.
b) Na lista suspensa Conectar via tempo de execução de integração , selecione o valor.
c. Na caixa ID da Chave de Acesso , insira o valor.
Observação
No Amazon S3, para localizar sua chave de acesso, selecione seu nome de usuário da Amazon na barra de navegação e, em seguida, selecione Minhas credenciais de segurança.
d. Na caixa Chave de Acesso Secreta , insira um valor.
e. Para testar a conexão de serviço vinculado que você criou, selecione Testar Conexão.
f. Selecione Concluir.
O painel Armazenamento de dados de origem exibe sua nova conexão do AmazonS31.
Selecione Seguinte.
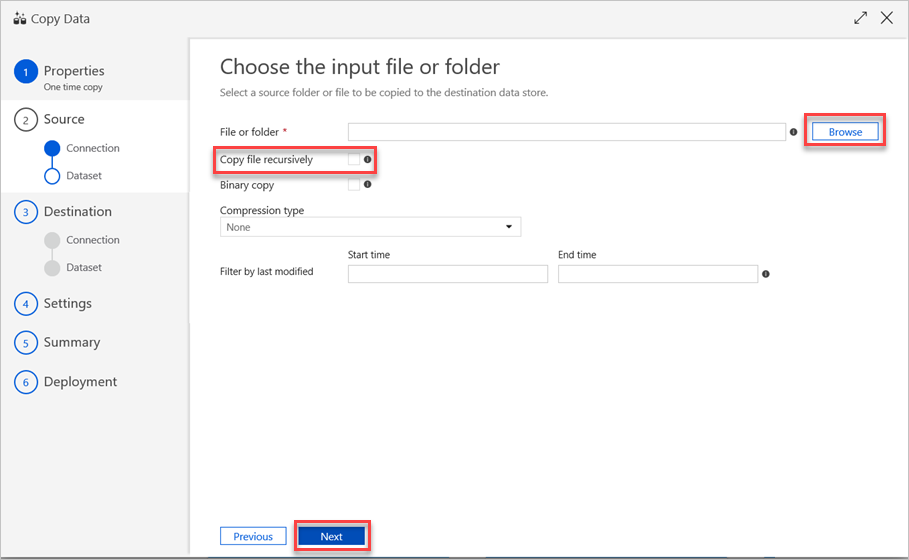
No painel Escolha o arquivo de entrada ou pasta , execute as seguintes etapas:
a) Navegue até o arquivo ou pasta que deseja copiar e selecione-o.
b) Selecione o comportamento de cópia desejado. Verifique se a caixa de seleção Cópia binária está desmarcada.
c. Selecione Seguinte.
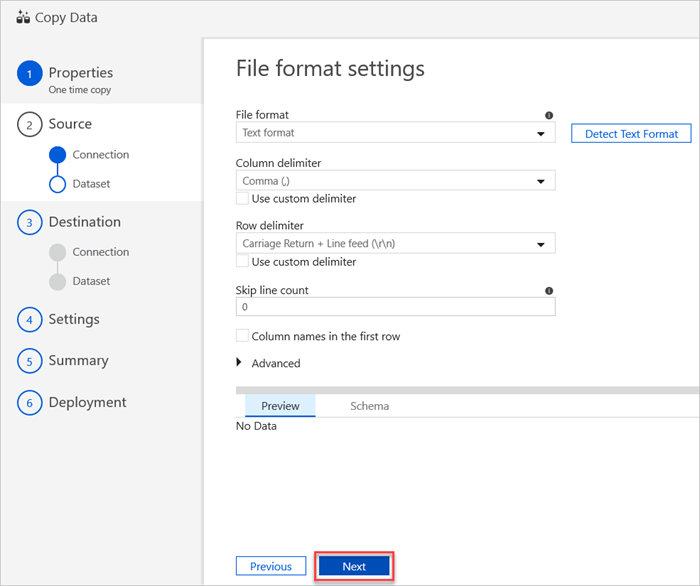
No painel Configurações de formato de arquivo , selecione as configurações relevantes para seu arquivo. e, em seguida, selecione Avançar.
Copiar dados para o Azure Data Explorer (destino)
O novo serviço vinculado do Azure Data Explorer é criado para copiar os dados para a tabela de destino (coletor) do Azure Data Explorer especificada nesta seção.
Observação
Use a atividade de comando do Azure Data Factory para executar comandos de gerenciamento do Azure Data Explorer e use qualquer um dos comandos ingeridos a partir de consulta, como .set-or-replace.
Criar o serviço vinculado do Azure Data Explorer
Para criar o serviço vinculado do Azure Data Explorer, execute as seguintes etapas:
Para usar uma conexão de armazenamento de dados existente ou especificar um novo armazenamento de dados, no painel Armazenamento de dados de destino , selecione Criar nova conexão.

No painel Novo Serviço Vinculado , selecione Azure Data Explorer e, em seguida, selecione Continuar.

No painel Novo Serviço Vinculado (Azure Data Explorer), execute as seguintes etapas:

Na caixa Nome , insira um nome para o serviço vinculado do Azure Data Explorer.
Em Método de autenticação, escolha Identidade gerenciada atribuída pelo sistema ou Entidade de serviço.
Para autenticar usando uma identidade gerenciada, conceda à identidade gerenciada acesso ao banco de dados usando o nome da identidade gerenciada ou a ID do objeto de identidade gerenciada.
Para autenticar usando uma entidade de serviço:
- Na caixa Inquilino , introduza o nome do inquilino.
- Na caixa ID da entidade de serviço , insira a ID da entidade de serviço.
- Selecione Chave da entidade de serviço e, em seguida, na caixa Chave da entidade de serviço , insira o valor da chave.
Observação
- O princípio de serviço é usado pelo Azure Data Factory para aceder ao serviço Azure Data Explorer. Para criar uma entidade de serviço, vá para criar uma entidade de serviço do Microsoft Entra.
- Para atribuir permissões a uma Identidade Gerenciada ou a uma Entidade de Serviço, consulte gerenciar permissões.
- Não use o método Azure Key Vault ou a Identidade Gerenciada Atribuída pelo Usuário.
Em Método de seleção de conta, escolha uma das seguintes opções:
Selecione Da assinatura do Azure e, em seguida, nas listas de seleção, selecione a sua assinatura do Azure e o seu Cluster.
Observação
- O controle suspenso Cluster lista apenas os clusters associados à sua assinatura.
- Seu cluster deve ter a SKU apropriada para o melhor desempenho.
Selecione Inserir manualmente e, em seguida, insira o seu Endpoint.
Na lista suspensa Banco de Dados, selecione o nome do banco de dados. Como alternativa, marque a caixa de seleção Editar e digite o nome do banco de dados.
Para testar a conexão de serviço vinculado que você criou, selecione Testar Conexão. Se você puder se conectar ao serviço vinculado, o painel exibirá uma marca de seleção verde e uma mensagem Conexão bem-sucedida .
Selecione Criar para concluir a criação do serviço vinculado.
Configurar a conexão de dados do Azure Data Explorer
Depois de criar a conexão de serviço vinculado, o painel Armazenamento de dados de destino é aberto e a conexão criada fica disponível para uso. Para configurar a conexão, execute as seguintes etapas:
Selecione Seguinte.

No painel Mapeamento de tabela , defina o nome da tabela de destino e selecione Avançar.

No painel Mapeamento de coluna , ocorrem os seguintes mapeamentos:
a) O primeiro mapeamento é realizado pelo Azure Data Factory de acordo com o mapeamento de esquema do Azure Data Factory. Faça o seguinte:
Defina os mapeamentos de coluna para a tabela de destino no Azure Data Factory. O mapeamento padrão é exibido da origem para a tabela de destino do Azure Data Factory.
Cancele a seleção das colunas de que não precisa para definir o mapeamento de colunas.
b) O segundo mapeamento ocorre quando esses dados tabulares são ingeridos no Azure Data Explorer. O mapeamento é realizado de acordo com as regras de mapeamento CSV. Mesmo que os dados de origem não estejam no formato CSV, o Azure Data Factory converte os dados em um formato tabular. Portanto, o mapeamento CSV é o único mapeamento relevante nesta fase. Faça o seguinte:
(Opcional) Em Propriedades do coletor do Azure Data Explorer (Kusto), adicione o nome de mapeamento de ingestão relevante para que o mapeamento de coluna possa ser usado.
Se o nome do mapeamento de ingestão não for especificado, a ordem de mapeamento por nome definida na seção Mapeamentos de coluna será usada. Se o mapeamento por nome falhar, o Azure Data Explorer tentará ingerir os dados em uma ordem de posição por coluna (ou seja, ele mapeia por posição como padrão).
Selecione Seguinte.

No painel Configurações , execute as seguintes etapas:
a) Em Configurações de tolerância a falhas, insira as configurações relevantes.
b) Em Configurações de desempenho, Habilitar preparo não se aplica e Configurações avançadas inclui considerações de custo. Se você não tiver requisitos específicos, deixe essas configurações como estão.
c. Selecione Seguinte.

No painel Resumo , reveja as definições e, em seguida, selecione Seguinte.

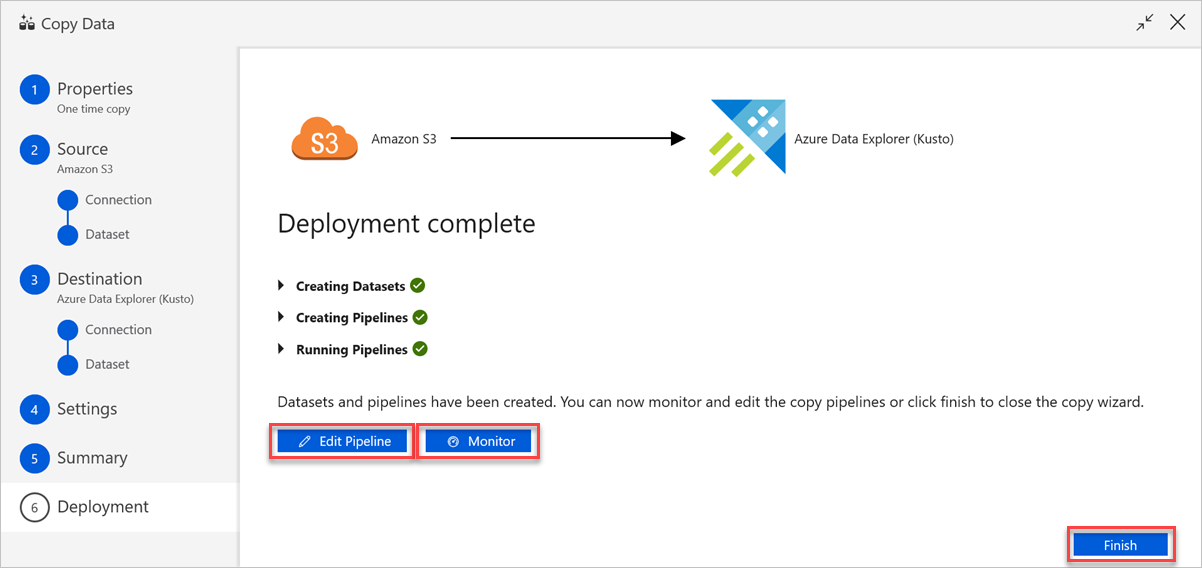
No painel Implantação concluída , faça o seguinte:
a) Para alternar para a guia Monitor e exibir o status do pipeline (ou seja, progresso, erros e fluxo de dados), selecione Monitor.
b) Para editar serviços, conjuntos de dados e pipelines vinculados, selecione Editar pipeline.
c. Selecione Concluir para concluir a tarefa de cópia de dados.
Conteúdo relacionado
- Saiba mais sobre o conector do Azure Data Explorer para o Azure Data Factory.
- Edite serviços vinculados, conjuntos de dados e pipelines na interface do usuário do Data Factory.
- Consultar dados na interface do usuário da Web do Azure Data Explorer.